You’re a modern Platform Ops or DevOps engineer. You use a library of open source (and maybe some commercial) tools to test, deploy, and manage new apps and containers for your Dev team. You’ve chosen Kubernetes to run these containers and pods in development, test, staging, and production environments. You’ve bought into the architectures and concepts of microservices and, for the most part, it works pretty well. However, you’ve encountered a few speed bumps along this journey.
For instance, as you build and roll out new clusters, services, and applications, how do you easily integrate or migrate these new resources into production without dropping any traffic? Traditional networking appliances require reloads or reboots when implementing configuration changes to DNS records, load balancers, firewalls, and proxies. These adjustments are not reconfigurable without causing downtime because a “service outage” or “maintenance window” is required to update DNS, load balancer, and firewall rules. More often than not, you have to submit a dreaded service ticket and wait for another team to approve and make the changes.
Maintenance windows can drive your team into a ditch, stall application delivery, and make you declare, “There must be a better way to manage traffic!” So, let’s explore a solution that gets you back in the fast lane.
Active-Active Multi-Cluster Load Balancing
If you have multiple Kubernetes clusters, it’s ideal to route traffic to both clusters at the same time. An even better option is to perform A/B, canary, or blue-green traffic splitting and send a small percentage of your traffic as a test. To do this, you can use NGINX Plus with ngx_http_split_clients_module.

The HTTP Split Clients module is written by NGINX Open Source and allows the ratio of requests to be distributed based on a key. In this use case, the clusters are the “upstreams” of NGINX. So, as the client requests arrive, the traffic is split between two clusters. The key that is used to determine the client request is any available NGINX client $variable. That said, to control this for every request, use the $request_id variable, which is a unique number assigned by NGINX to every incoming request.
To configure the split ratios, determine which percentages you’d like to go to each cluster. In this example, we use K8s Cluster1 as a “large cluster” for production and Cluster2 as a “small cluster” for pre-production testing. If you had a small cluster for staging, you could use a 90:10 ratio and test 10% of your traffic on the small cluster to ensure everything is working before you roll out new changes to the large cluster. If that sounds too risky, you can change the ratio to 95:5. Truthfully, you can pick any ratio you’d like from 0 to 100%.
For most real-time production traffic, you likely want a 50:50 ratio where your two clusters are of equal size. But you can easily provide other ratios, based on the cluster size or other details. You can easily set the ratio to 0:100 (or 100:0) and upgrade, patch, repair, or even replace an entire cluster with no downtime. Let NGINX split_clients route the requests to the live cluster while you address issues on the other.
# Nginx Multi Cluster Load Balancing
# HTTP Split Clients Configuration for Cluster1:Cluster2 ratios
# Provide 100, 99, 50, 1, 0% ratios (add/change as needed)
# Based on
# https://www.nginx.com/blog/dynamic-a-b-testing-with-nginx-plus/
# Chris Akker – Jan 2024
#
split_clients $request_id $split100 {
* cluster1-cafe; # All traffic to cluster1
}
split_clients $request_id $split99 {
99% cluster1-cafe; # 99% cluster1, 1% cluster2
* cluster2-cafe;
}
split_clients $request_id $split50 {
50% cluster1-cafe; # 50% cluster1, 50% cluster2
* cluster2-cafe;
}
split_clients $request_id $split1 {
1.0% cluster1-cafe; # 1% to cluster1, 99% to cluster2
* cluster2-cafe;
}
split_clients $request_id $split0 {
* cluster2-cafe; # All traffic to cluster2
}
# Choose which cluster upstream based on the ratio
map $split_level $upstream {
100 $split100;
99 $split99;
50 $split50;
1.0 $split1;
0 $split0;
default $split50;
}
You can add or edit the configuration above to match the ratios that you need (e.g., 90:10, 80:20, 60:40, and so on).
Note: NGINX also has a Split Clients module for TCP connections in the stream context, which can be used for non-HTTP traffic. This splits the traffic based on new TCP connections, instead of HTTP requests.
NGINX Plus Key-Value Store
The next feature you can use is the NGINX Plus key-value store. This is a key-value object in an NGINX shared memory zone that can be used for many different data storage use cases. Here, we use it to store the split ratio value mentioned in the section above. NGINX Plus allows you to change any key-value record without reloading NGINX. This enables you to change this split value with an API call, creating the dynamic split function.
Based on our example, it looks like this:
{“cafe.example.com”:90}
This KeyVal record reads:
The Key is the “cafe.example.com” hostname
The Value is “90” for the split ratio
Instead of hard-coding the split ratio in the NGINX configuration files, you can instead use the key-value memory. This eliminates the NGINX reload required to change a static split value in NGINX.
In this example, NGINX is configured to use 90:10 for the split ratio with the large Cluster1 for the 90% and the small Cluster2 for the remaining 10%. Because this is a key-value record, you can change this ratio using the NGINX Plus API dynamically with no configuration reloads! The Split Clients module will use this new ratio value as soon as you change it, on the very next request.
Create the KV Record, start with a 50/50 ratio:
Add a new record to the KeyValue store, by sending an API command to NGINX Plus:
curl -iX POST -d '{"cafe.example.com":50}' http://nginxlb:9000/api/8/http/keyvals/split
Change the KV Record, change to the 90/10 ratio:
Change the KeyVal Split Ratio to 90, using an HTTP PATCH Method to update the KeyVal record in memory:
curl -iX PATCH -d '{"cafe.example.com":90}' http://nginxlb:9000/api/8/http/keyvals/split
Next, the pre-production testing team verifies the new application code is ready, you deploy it to the large Cluster1, and change the ratio to 100%. This immediately sends all the traffic to Cluster1 and your new application is “live” without any disruption to traffic, no service outages, no maintenance windows, reboots, reloads, or lots of tickets. It only takes one API call to change this split ratio at the time of your choosing.
Of course, being that easy to move from 90% to 100% means you have an easy way to change the ratio from 100:0 to 50:50 (or even 0:100). So, you can have a hot backup cluster or can scale your clusters horizontally with new resources. At full throttle, you can even completely build a new cluster with the latest software, hardware, and software patches – deploying the application and migrating the traffic over a period of time without dropping a single connection!
Use Cases
Using the HTTP Split Clients module with the dynamic key-value store can deliver the following use cases:
- Active-active load balancing – For load balancing to multiple clusters.
- Active-passive load balancing – For load balancing to primary, backup, and DR clusters and applications.
- A/B, blue-green, and canary testing – Used with new Kubernetes applications.
- Horizontal cluster scaling – Adds more cluster resources and changes the ratio when you’re ready.
- Hitless cluster upgrades – Ability to use one cluster while you upgrade, patch, or repair the other cluster.
- Instant failover – If one cluster has a serious issue, you can change the ratio to use your other cluster.
Configuration Examples
Here is an example of the key-value configuration:
# Define Key Value store, backup state file, timeout, and enable sync
keyval_zone zone=split:1m state=/var/lib/nginx/state/split.keyval timeout=365d sync;
keyval $host $split_level zone=split;
And this is an example of the cafe.example.com application configuration:
# Define server and location blocks for cafe.example.com, with TLS
server {
listen 443 ssl;
server_name cafe.example.com;
status_zone https://cafe.example.com;
ssl_certificate /etc/ssl/nginx/cafe.example.com.crt;
ssl_certificate_key /etc/ssl/nginx/cafe.example.com.key;
location / {
status_zone /;
proxy_set_header Host $host;
proxy_http_version 1.1;
proxy_set_header "Connection" "";
proxy_pass https://$upstream; # traffic split to upstream blocks
}
# Define 2 upstream blocks – one for each cluster
# Servers managed dynamically by NLK, state file backup
# Cluster1 upstreams
upstream cluster1-cafe {
zone cluster1-cafe 256k;
least_time last_byte;
keepalive 16;
#servers managed by NLK Controller
state /var/lib/nginx/state/cluster1-cafe.state;
}
# Cluster2 upstreams
upstream cluster2-cafe {
zone cluster2-cafe 256k;
least_time last_byte;
keepalive 16;
#servers managed by NLK Controller
state /var/lib/nginx/state/cluster2-cafe.state;
}
The upstream server IP:ports are managed by NGINX Loadbalancer for Kubernetes, a new controller that also uses the NGINX Plus API to configure NGINX Plus dynamically. Details are in the next section.
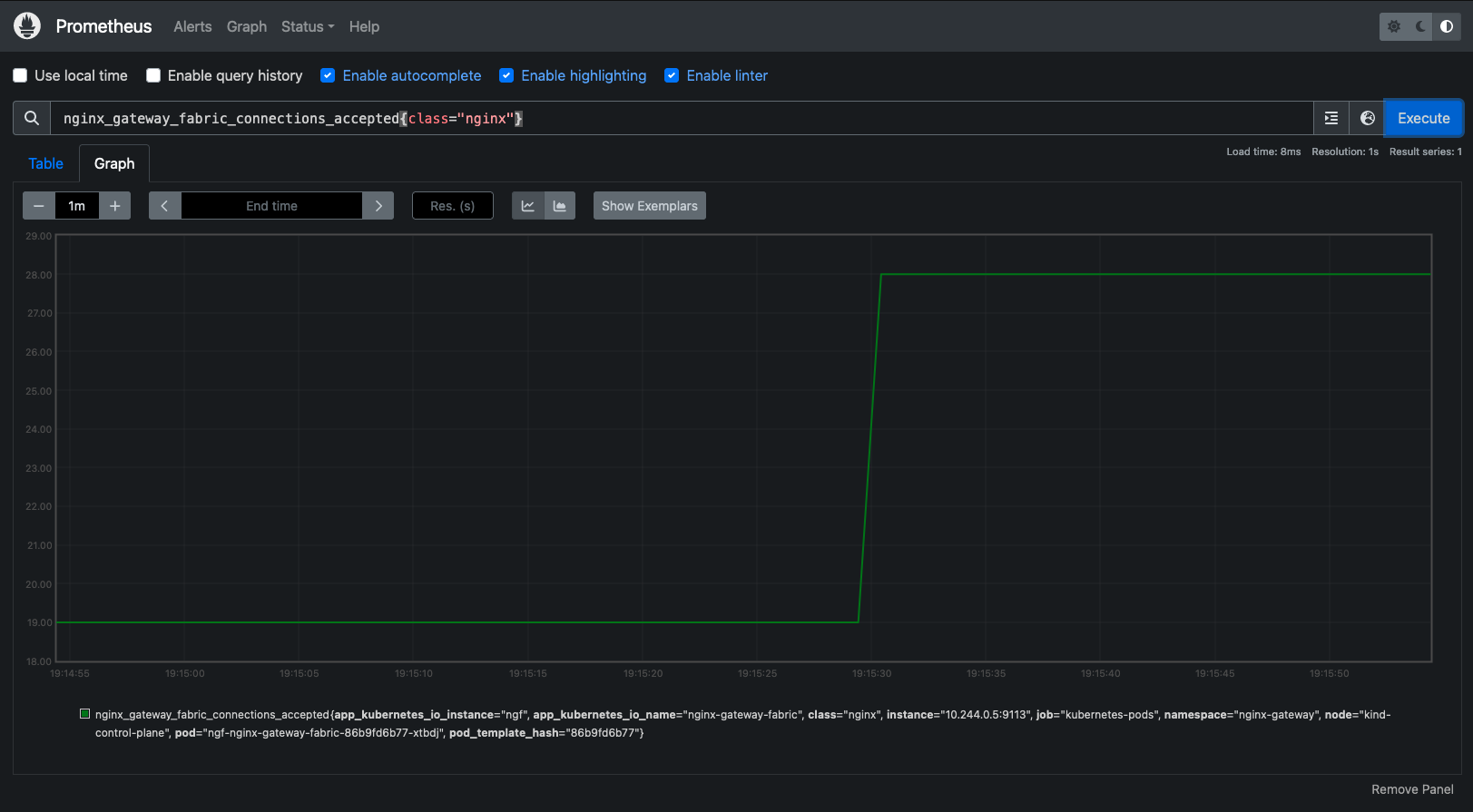
Let’s take a look at the HTTP split traffic over time with Grafana, a popular monitoring and visualization tool. You use the NGINX Prometheus Exporter (based on njs) to export all of your NGINX Plus metrics, which are then collected and graphed by Grafana. Details for configuring Prometheus and Grafana can be found here.
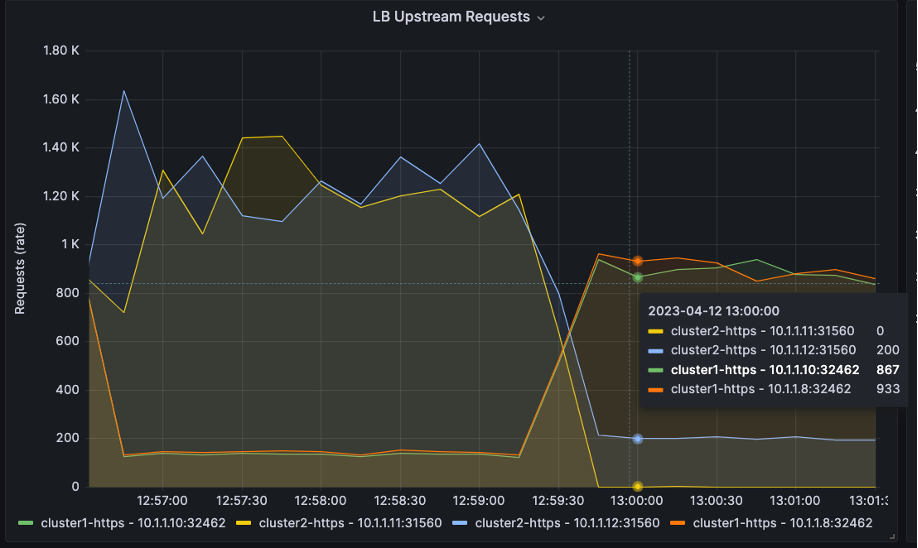
There are four upstreams servers in the graph: Two for Cluster1 and two for Cluster2. We use an HTTP load generation tool to create HTTP requests and send them to NGINX Plus.
In the three graphs below, you can see the split ratio is at 50:50 at the beginning of the graph.
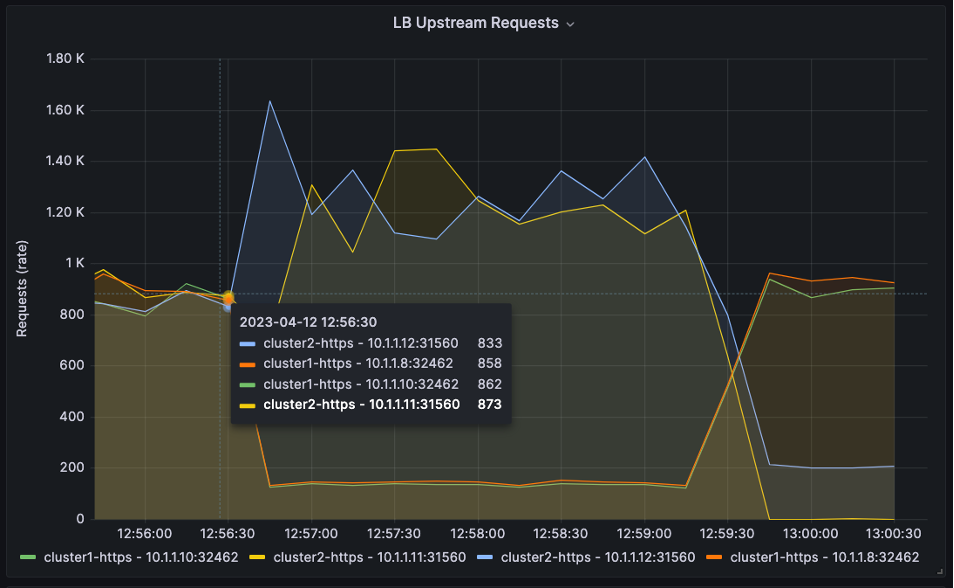
Then, the ratio changes to 10:90 at 12:56:30.
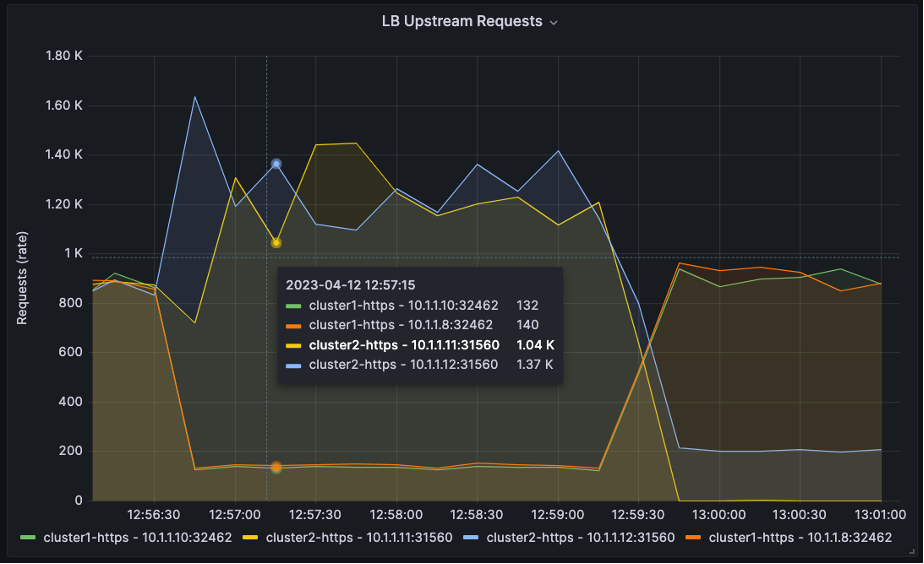
Then it changes to 90:10 at 13:00:00.
You can find working configurations of Prometheus and Grafana on the NGINX Loadbalancer for Kubernetes GitHub repository.
You can change the static NGINX Upstream configuration to dynamic cluster upstreams using the NGINX Plus API and the NGINX Loadbalancer for Kubernetes controller. This free project is a Kubernetes controller that watches NGINX Ingress Controller and automatically updates an external NGINX Plus instance configured for TCP/HTTP load balancing. It’s very straightforward in design and simple to install and operate. With this solution in place, you can implement TCP/HTTP load balancing in Kubernetes environments, ensuring new apps and services are immediately detected and available for traffic – with no reload required.
Architecture and Flow
NGINX Loadbalancer for Kubernetes sits inside a Kubernetes cluster. It is registered with Kubernetes to watch the NGINX Ingress Controller (nginx-ingress) Service. When there is a change to the Ingress controller(s), NGINX Loadbalancer for Kubernetes collects the Worker Ips and the NodePort TCP port numbers, then sends the IP:ports to NGINX Plus via the NGINX Plus API.
The NGINX upstream servers are updated with no reload required, and NGINX Plus load balances traffic to the correct upstream servers and Kubernetes NodePorts. Additional NGINX Plus instances can be added to achieve high availability.

A Snapshot of NGINX Loadbalancer for Kubernetes in Action
In the screenshot below, there are two windows that demonstrate NGINX Loadbalancer for Kubernetes deployed and doing its job:
- Service Type –
LoadBalancer for nginx-ingress
- External IP – Connects to the NGINX Plus servers
- Ports – NodePort maps to 443:30158 with matching NGINX upstream servers (as shown in the NGINX Plus real-time dashboard)
- Logs – Indicates NGINX Loadbalancer for Kubernetes is successfully sending data to NGINX Plus
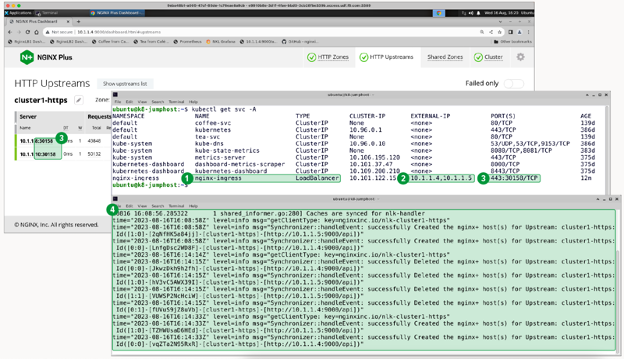
Note: In this example, the Kubernetes worker nodes are 10.1.1.8 and 10.1.1.10
Adding NGINX Plus Security Features
As more and more applications running in Kubernetes are exposed to the open internet, security becomes necessary. Fortunately, NGINX Plus has enterprise-class security features that can be used to create a layered, defense-in-depth architecture.
With NGINX Plus in front of your clusters and performing the split_clients function, why not leverage that presence and add some beneficial security features? Here are a few of the NGINX Plus features that could be used to enhance security, with links and references to other documentation that can be used to configure, test, and deploy them.
Get Started Today
If you’re frustrated with networking challenges at the edge of your Kubernetes cluster, consider trying out this NGINX multi-cluster Solution. Take the NGINX Loadbalancer for Kubernetes software for a test drive and let us know what you think. The source code is open source (under the Apache 2.0 license) and all installation instructions are available on GitHub.
To provide feedback, drop us a comment in the repo or message us in the NGINX Community Slack.