


This post is adapted from a webinar by Floyd Smith and Faisal Memon from NGINX, Inc. Our new ebook on the topic is available for download.
Table of Contents
0:00 Introduction

Floyd Smith: Hello, and welcome to our presentation. We’re here at NGINX, and we’ll be talking today about my ebook 5 Reasons to Switch to Software for Load Balancing.
There are two of us presenting here today. I’m Floyd Smith, Technical Marketing Writer for NGINX. I was formerly a Senior Technical Writer at Apple, and I’ve been an author of a number of books about different aspects of technology.
Faisal Memon: Hi, I’m Faisal Memon and I do Product Marketing here at NGINX. I’ve been here for about a year. Prior to coming here at NGINX, I worked as a Technical Marketing Engineer at Riverbed, as well as at Cisco. I started off my career doing development in C. Software Engineer at Cisco – I did that role for about eight years.
1:38 Who Are You?

Floyd: We get sign‑ups for our webinars before we do them, and we can see the job titles, organizations, and reasons for attending that each of you submitted.
It was really interesting to look at the titles of people who are attending. We’ve got Solutions Architects – several different kinds of architects. Linux Admins, Heads of Engineering, CEO, Senior Agile Delivery Manager, several people with DevOps titles, Full Stack Software Developer, Engineer, Scientist, Developer, Marketing Operations Manager.
We have a really good range of people with a technical bent. My sense is that the people who are on this webinar are really very hands‑on with the technology and will be directly facing the issues that we’re talking about here today.
We also have a really nice, wide range of organizations represented. Some of you may be looking at this so you can guide your customers in making intelligent decisions, but the majority of you seem to be dealing with this directly, in house.
3:53 From Hardware to Software
The market for hardware ADCs is declining, according to financial reports, so the people who sell hardware ADCs are trying to increase the revenue they get per customer even as their customer base declines. A lot of hardware ADC customers are starting to find that they don’t want to be in that ever‑shrinking pool of people paying ever more money for these hardware ADC‑provided services. They are starting to see that they can actually do the same thing better in software, and gain more flexibility to boot. Those of you with DevOps in your title probably know what I mean.
What we often see here at NGINX is that people reach the contact renewal date on their hardware ADC, or they get a sudden increase in traffic and a sudden uptick in charges, and then they’re really scrambling to get out of the contract. Then they have to try to do things very quickly. They usually succeed, but it’s stressful, it’s unplanned, and it’s unbudgeted. With the help of this presentation, you can start more of a planned process.
The budgetary issue isn’t as critical, because you save so much money by moving to software, but the operational hassles are huge. You can reduce those a lot just by getting started early.

NGINX is a really solid alternative to a hardware ADC. It was originally created to solve the C10K problem. That’s one web server running on one computer serving 10,000 or more simultaneous connections. Before NGINX it was impossible. People would put up a website, it would get popular, and then it would keel over. Stopping this from happening was very, very, very difficult, but with NGINX, it got a lot easier.
Our first open source release was in 2004 in Russia, where NGINX [the software] was originally created [Editor – Floyd says “founded” here; NGINX, Inc. was founded in 2011]. NGINX Plus, the commercial version with support, was released in 2013.
NGINX the company is based in Silicon Valley (San Francisco), and our development offices are in Moscow. We also have offices in the UK. The company is VC‑backed by industry leaders. We have more than 800 customers, and we’ve just reached 100 employees the other day.
6:33 The Leading Web Server for the Busiest Sites in the World

There are 160 million total sites running on NGINX.
It’s used in two different modes. Some sites run NGINX as a web server, which was its original purpose. But many sites run NGINX as a reverse‑proxy server. That’s where you drop NGINX in front of your current architecture, using NGINX to handle traffic and route traffic to your application servers. As soon as you’re doing that, you’re on the way to doing load balancing, which is what we’ll be talking about today.

51 percent of the top 10,000 busiest websites have moved to NGINX. Now, why is that? Why do we have even more usage among the busiest websites than we do among websites as a whole?
The reason is that NGINX is the best solution for really busy websites. A quick way to save a busy website that’s having problems is dropping NGINX in as a reverse‑proxy server, then running load balancing on top of it.
Over time, you can either transition your existing apps to NGINX, or should you develop new ones, you can run NGINX as the web server as well for those. And that’s how we’ve achieved this usage among these very busy people, who don’t change web servers on a whim. They have experience with other web servers and they know how to use them, but they make this change because of all that NGINX does for them.

36 percent of all sites on Amazon Web Services use NGINX. It’s kind of becoming a standard tool. Now, people often start off with NGINX and stick with it throughout their project.
Here are some of the sites that use us. Of course, with 160 million websites using NGINX, we can’t get them all on one slide, but some of our partners and friends are Netflix, and Airbnb, and Uber, and Amazon Web Services as I mentioned, Box, Pinterest, WordPress.
All of these companies that do web delivery for a living, where it has to work, have moved to NGINX.

8:48 Where NGINX Fits
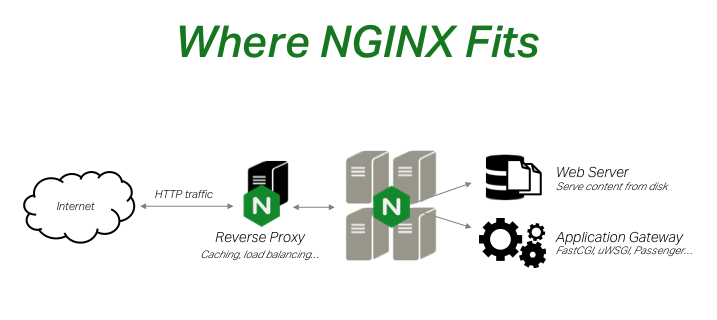
Let’s look at where NGINX fits.
On the right, you see NGINX running as a web server. And as a web server, it uses an application gateway to allow different kinds of app servers to run with it. NGINX as a web server can handle 10,000 simultaneous connections, more or less, depending on what you’re doing.
But NGINX is also useful as a reverse‑proxy server, and that’s where you get caching, load balancing, and a number of other capabilities.
9:32 Modern Web Architecture
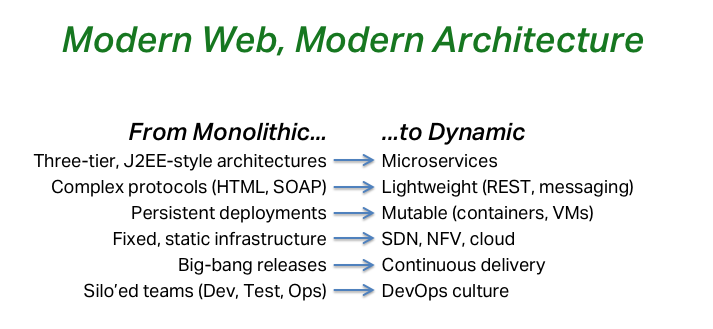
NGINX also helps you move to a modern web architecture. That could be three‑tier J2EE‑style architectures moving to microservices. It could be complex protocols of HTML and SOAP moving to lighter protocols like REST and messaging, which is a big part of microservices. Or going from persistent deployments to mutable deployments running containers or VMs.
Instead of a fixed, static infrastructure, you usually have a service that you own yourself. We have things like SDN and NFV and the cloud, especially the cloud. Instead of big‑bang releases every few months, you have continuous delivery every few hours. And instead of siloed teams, where you have a development group, a testing group, and an operations group working through their own managers, you have a DevOps culture of shared responsibility where everyone rolls up their sleeves and handles some aspects of every problem.
10:42 DevOps Works Great with NGINX
 DevOps methodology, cloud deployments, and automated service discovery” width=”716″ height=”301″ class=”aligncenter size-full wp-image-46723″ style=”border:2px solid #666666; padding:2px; margin:2px;” />
DevOps methodology, cloud deployments, and automated service discovery” width=”716″ height=”301″ class=”aligncenter size-full wp-image-46723″ style=”border:2px solid #666666; padding:2px; margin:2px;” />
The DevOps story is closely intertwined with NGINX. A lot of DevOps people have NGINX in their hip pockets, and when they run into a deployment that’s having problems, they bring NGINX in.
In certain deployments, you can just not even bother to change the app setup at all. You drop NGINX in front of it, you get the traffic to the app servers in a way that they can handle. You haven’t changed that code, and you haven’t risked your core functionality when you’re in a hurry to solve a performance problem.
One of the things that DevOps and NGINX tend to work well together for is software load balancing, as we’ll discuss. It works really well with cloud deployments, but also with your own servers. It features a variety of load balancing methods. Here there’s a difference between NGINX and NGINX Plus, which I’ll get into in a minute.
NGINX’s on‑the‑fly reconfiguration capability supports service discovery and uptime. Service discovery is essential for microservices and automation, and with on‑the‑fly reconfiguration, you don’t have to kick people off a server in order to configure it, which is a huge advantage in keeping your customers online.
Application health checks give early warning of application delivery issues so that you can gracefully wind down a problem server, rather than just having it seize up and throw people off. And then there’s robust customizable monitoring. Again, that’s letting you know about problems as they’re emerging, so you can solve them before they affect customers.
12:30 NGINX Plus Capabilities
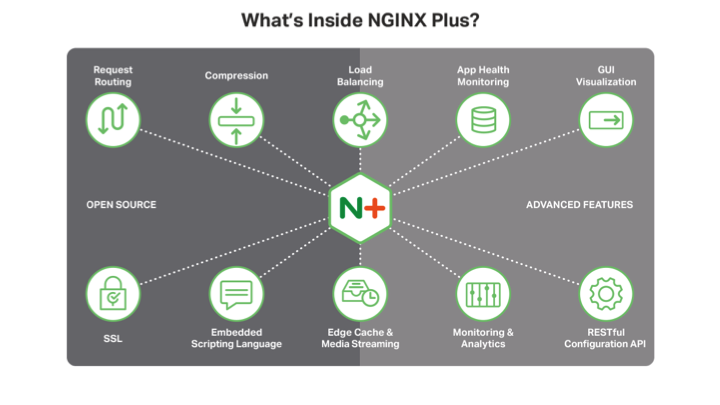
What’s inside NGINX Plus?
So open source NGINX is the original product, and NGINX Plus is the commercial product on top of it. We here at NGINX spend at least 70 percent of our time on the open source side, but that’s also the base for the advanced features in NGINX Plus.
The open source product includes request routing, which is the core of what a web server does; compression because that will minimize the load on a web server and it also minimizes traffic over the wire, which can be very valuable. It has support for SSL for security. We also have an embedded scripting language, two actually. One is our own, the NGINX JavaScript module [formerly called nginScript], and one is Lua.
There are a couple of capabilities that are partly open source NGINX but are enhanced in NGINX Plus. You can do load balancing quite well with open source NGINX, but with NGINX Plus, you get a couple more advanced capabilities. Similarly, you can use open source NGINX as an edge cache and for media streaming, and that works even better in NGINX Plus.
NGINX Plus also has several features of its own. There’s application health monitoring, GUI visualization for your monitoring, monitoring and analytics, the RESTful configuration API, and a couple of the more advanced load‑balancing techniques.
With NGINX Plus, you get access to NGINX engineers to help support you as you do your work. If you’re currently using F5, Citrix, or a similar system, you’re probably used to that kind of support. For larger and busier websites, where even a little bit of downtime costs you a lot of money, this can be crucial – and can easily pay for itself if you avoid even a brief outage just once a year.
14:41 Customer Case Study – WordPress.com

Let’s look at some case studies of customers who made the switch.
WordPress.com was using F5’s BIG‑IP and they moved away from that for NGINX because they needed to do load balancing with more than 10,000 requests per second per server – that’s the C10k problem we were talking about which NGINX has been solving for more than ten years. At the time, they were limited to 1,000 requests per second per server. You can imagine how burdensome that was as compared to 10,000 or more.
Wordpress.com had several F5 BIG‑IP systems, and they were going to grow to ten data centers. To support high availability, basically to have a live backup for every data center, they were looking at ten pairs of BIG‑IP servers. Very expensive. They also needed on‑the‑fly reconfiguration to not boot users off when they changed the configuration.
They started making the move to NGINX by testing it on Gravatar, which is an app that puts up an avatar for users. That got them familiar with NGINX. Then, they made the move from their F5 servers to NGINX, and that gave them a small and predictable memory footprint, as well as a small and predictable CPU footprint.
Now they handle more than 70,000 requests per second and 15 gigabits per second [Gbps] on 36 NGINX servers. They can peak at 20,000 requests per second per server. And they can reconfigure and update on the fly.
If you see the quote, they’re just talking about the difference in expense between a small implementation, where NGINX will save you a significant amount of money. But when you go to ten pairs of servers, it is a huge night‑and‑day difference.
16:42 Customer Case Study – Montana Interactive

Montana Interactive chooses NGINX Plus for high‑availability load balancing. It’s actually easier, cheaper, and better for a lot of government services to be provided online. If you’ve booked an appointment at your motor vehicle department or similar, you’ll know what I mean. These websites can support voting, paying your taxes, etc.
There’s a tremendous amount of these essential government services, and Montana is a very large state with a relatively small number of people in it spread out all over the place. So, having online availability for services is very important, versus having residents drive six or eight hours to get to a government office.
Montana was moving to online services pretty robustly at first, but as they grew they started suffering from dropped sessions. They had big quarterly spikes in transaction traffic due to a large payment app for taxes. In the middle of filling out a large form, suddenly someone would get dropped, all their work would be lost. If you’re doing your taxes, or any other kind of involved process, that’s pretty stressful.
The solution for them was to upgrade from servers running Pound to NGINX Plus, to put NGINX Plus on different hypervisors, data centers, and to operate as a dynamic reverse proxy, routing requests in real time, giving them better traffic management. As a result of moving to NGINX Plus, they saw massive improvements in speed, flexibility, and ease of use. They benefited from on‑the‑fly reconfiguration, they offloaded their SSL processing to NGINX servers, and used role‑based management to improve operations and security.
Montana Interactive’s James Ridle was amazed by the power of NGINX. The benchmarks blew him away and he almost couldn’t believe the difference in what he could handle through the same servers with NGINX.
18:43 Customer Case Study – BuyDig.com

This is another case study with huge benefits for the customer – BuyDig.com, which is an ecommerce site that got scalability and security with NGINX.
BuyDig.com had an older .NET app. They didn’t want to change it, and they didn’t have to. After suffering from a large‑scale DDoS attack, they realized they needed a fast, fault‑tolerant, and easy‑to‑configure frontend with better performance, security, and scalability.
They put NGINX Plus in the frontend application layer, hosted on Amazon Web Services. They didn’t make any changes to their backend services running on .NET. And that’s so big – no changes – not small changes, not minor hassles, not minor risks, but none.
Now they get fantastic performance and security. They used configuration languages for NGINX to customize it. They use TLS SNI and customizable logs in order to help them stay secure. They’ve had not had one single slowdown or site downtime, and they’re really happy with the performance.
So, those are just some of the examples of what NGINX Plus can do.
20:10 Ebook – 5 Reasons to Switch to Software for Load Balancing

Let me now dive into the ebook. I’ll give you a quick summary of what’s in the ebook and then Faisal’s going to take you through the first two reasons for switching, which are more technical, and I’ll pick up after that. There are links. You’ll get this presentation and the webinar recording made available to you after we’re finished. It takes about a day, I think, for that email to get out.
And this link here will get you to a download spot for this free ebook. So, just to mention in advance what the reasons are: they’re to cut costs; improve DevOps fit; to deploy everywhere (your own on‑premises servers, in the cloud, private cloud, anything you want to do); the ability to adapt quickly and no weird contractual constraints, which I’ll explain in some detail. But now, let me turn it over to Faisal to talk about cutting costs.
21:22 Reason #1 – Dramatically Reduce Costs

Faisal: Thanks, Floyd. Reason #1 of the five reasons is that you can drastically reduce costs by moving to NGINX Plus for software application delivery.
Looking back to the mid‑90s, the only way to scale a website was to buy a bigger server, which was incredibly expensive and also unreliable, because that single server was also a single point of failure.
It was around this time that F5 first released BIG‑IP, and that provided a different architecture for website owners; instead of buying a bigger server, you could use the BIG‑IP to load balance an array of inexpensive servers. So that reduces costs, because it’s cheaper to buy the BIG‑IP and the inexpensive servers than to buy that one gigantic server, and you also gain some redundancy because you’ve eliminated the single point of failure.
This was a great architecture – revolutionary and really the only game in town at the time – but a lot of things have changed over past 20 years. One major change has been that the cost of servers has dropped dramatically. Nowadays you can buy a fairly hefty server for less than the cost of one month’s rent out here in the San Francisco Bay Area.
The second major change is the existence now of open source software like NGINX that provides the same functionality that you get out of F5 BIG‑IP or Citrix NetScaler. In the case of open source, you can get similar functionality to those big expensive appliances for free. Floyd pointed out earlier that there’s over 160 million websites using NGINX. And if you look at the top 10,000 sites, over half of them are running on NGINX.
So, we now have this open source software that not only has all the functionality that you need compared to F5, but it’s also as scalable and reliable as any other commercial product.
23:19 NGINX Plus vs. F5 BIG‑IP

I did some benchmarking and cost analysis earlier this year and here’s an excerpt from that. This is comparing NGINX Plus software running on off‑the‑shelf commodity hardware. In this case it’s provided by Dell, and [we’re] comparing that to different models of the F5 BIG‑IP.
This particular example is the 2000S, which is the entry level F5 BIG‑IP. I’ve compared it to two different sizes of NGINX Plus on Dell servers. One that performs slightly lower than the F5 BIG‑IP (you can see the performance metrics on the bottom there) and one that nearly doubles the performance.
Just looking at that right column, where NGINX Plus doubles the performance of the 2000S, you’re getting 78% savings in Year 1, including the cost of the hardware and the maintenance support for one year. And those cost savings carry out all the way to Year 5. Even after five years, the total cost of ownership of NGINX Plus with the Dell server is 58% cheaper than the F5.
24:37 NGINX Plus vs. Citrix NetScaler

I did the same cost comparison with Citrix NetScaler. Here, we’re comparing the entry‑level NetScaler, the MPX‑5550 Enterprise Edition.
Citrix has licensing where if you want basic features such as caching and content compression, you have to upgrade your license to the Enterprise Edition license. With NGINX, content caching and compression are included at no additional charge in both open source and NGINX Plus. So what we’re comparing here is the Enterprise Edition of Citrix NetScaler, because that gives better feature parity with what’s provided in NGINX Plus, and we see the same cost savings here as we do with the F5 when you replace the Citrix NetScaler with NGINX Plus.
You get all the same features and performance that you expect, but you’re paying 89% less in Year 1. Even all the way out to Year 5, you’re still saving 75% for both the cost of the hardware (in this case commodity Dell servers) and the cost of a subscription to the NGINX Plus software.
A critical metric, and one that hardware vendors talk about a lot, is SSL transactions per second, or the number of new SSL connections that can be made per second. Within these platforms, that number is typically accelerated by hardware, so NetScaler and F5 BIG‑IP have specialized hardware to accelerate SSL transactions, which drives up the cost of those platforms.
What we’re seeing is that even with a software solution – without hardware acceleration, just using processing power from the CPU – we can keep up with the custom hardware. We deliver dramatic cost savings, with the performance that you would be getting from the hardware‑accelerated solutions.
So, that’s Reason #1: you can save a lot of money by moving to NGINX Plus. But it’s not just about money.
26:52 Reason #2 – DevOps Requires Software Application Delivery

With a software‑based solution you also get a lot of flexibility, and Reason #2 to switch to a software‑based load balancer is that if you’re moving to DevOps, you really need software for application delivery.
With F5 and NetScaler, the way that these appliance are typically deployed within large enterprises is as an aggregation point. So, a lot of unrelated traffic is run through it. That same F5 BIG‑IP can be load balancing network firewalls, it can be load balancing the corporate email servers, it can be load balancing multiple different backend enterprise applications, and it can also be load balancing the front‑facing enterprise application. It could be load balancing APIs in a microservices architecture. So, it can be load balancing a lot of things.
On the surface, this seems like a good architecture because it’s quite simple; you just run everything through the F5. For a long time this did work, especially the early 2000s when it was all about the private data center, and we ran all of our applications, everything that the enterprise relied on, out of an on‑premises data center. But things have changed in the past few years, and now most things are being moved off to the cloud.
When I say cloud, I’m not just talking about hosting a front‑facing web application within Amazon, but also using things like Salesforce and Office 365, as opposed to on‑premises CRM systems and on‑premises email servers. So having a device that could do all those things can be overkill for what people are actually running nowadays.
A second problem that this aggregation poses is that it leads to these appliances being very well locked down. You become very hesitant to make changes to it, because if you mess up the F5 configuration, you could take down the whole corporate network. It could be load balancing email servers, network firewalls. So, configuration becomes a risky affair and changes need to be very restricted and very locked down.
Anyone that wants to make changes to it typically needs to file an IT ticket, which can take hours, days, or weeks depending on the organization and the priority that the organization places on the change requested.
Having this extremely locked‑down piece of hardware makes it really hard to move to DevOps. When you’re doing DevOps and you’re moving towards automation, you’re moving toward continuous integration, you’re moving toward releasing code much more frequently. And if you have to file an IT ticket every time you want to make a change, it inhibits and kills that initiative.
What we see within a lot of organizations is that people who are responsible for the application and are wanting to move towards DevOps and towards Agile development can’t deal with having to file a ticket each time because that gets in the way of the DevOps and agile initiatives. So they’ll sometimes deploy open source NGINX, and have the F5 BIG‑IP point to that, and that NGINX instance will managed by the DevOps or the application team, which lets them do automation and make changes without the hassle. So that’s a way of kind of getting around corporate IT policy. Then we see a lot of customers, of course, once they try that, start to move towards NGINX Plus to get the more advanced features along with the support.
NGINX supports a range of flexible, different deployment models, including ones where you can keep your current F5 in place. You can use NGINX Plus to supplement and offload the load balancing and delivery of front‑facing web applications and APIs and microservices, keeping F5 in place to do network load balancing of corporate email servers. If you’re not needing network services and network load balancing, you can obviously also just replace the F5 with NGINX Plus and have a single solution there.
We support a range of different deployment models to help organizations move towards DevOps, towards continuous delivery, towards automation.
For Reason #3, I’ll hand it back to Floyd.
31:59 Reason #3 – Deploy Everywhere with One ADC

Floyd:Thank you, Faisal.
With NGINX, you can deploy everywhere with one ADC solution. What does ‘everywhere’ mean? It means your on‑premises servers, public cloud, private cloud, or hybrid cloud all work on one solution. And there’s a practical and also an architectural aspect to that.
First of all, if you’re using in‑house servers and you’re not using the cloud, everything that we’ve said strongly applies. Many people who move to NGINX and NGINX Plus to get better flexibility, more features and save money are in that exact situation: they’re deploying to in‑house servers.
If you are using or want to consider using the cloud as you go forward, there’s just no comparison between NGINX and the hardware ADC. You can’t move your hardware ADC to Amazon’s data centers. The hardware ADC is not going to help you there.
Now, the hardware ADC developers do have some software‑based solutions, but in some cases, they only recommend that you use those for development. It’s not a replacement for the hardware ADC. The advantages that you might see in terms of simplicity, or “if ain’t broke don’t fix it”, fall apart when you want to move to the cloud.
With NGINX and NGINX Plus, the application architecture is independent of the delivery platform. Certain cloud providers are starting to add more and more services that you can tie into by means of APIs. During development, it’s really a great thing to have, because you don’t have to worry about how to do something; you just use their APIs to handle load balancing, or caching, or other capabilities. But then when you scale, you’re paying a small amount for every transaction.
Well, all of a sudden, when you’re doing thousands, and tens of thousands, and hundreds of thousands of transactions, those numbers start to add up. The billing is very confusing and hard to predict, especially since it’s based on traffic, which is always varying.
If you use an NGINX‑ or NGINX Plus‑based approach, you basically do the same thing on any platform, and there’s very little difference when you move to a different cloud provider or back in house.
We actually have customers doing load balancing across their in‑house servers and the cloud. So, what does that look like? They get enough in‑house servers to support their needs 80 or 90 percent of time. Then when they need to scale up, they don’t have to buy or even plug in new servers; they just scale into the cloud.
The cloud is usually slower than your on‑premises servers and because everything’s load balanced, only the sessions that would get dropped if you were just using your in‑house servers go to the cloud. They have slightly longer latency, but they get handled, they don’t get put in a queue or dropped.
Financially it’s great because you’re only paying for cloud on an emergency basis, like a sudden spike in traffic. This can happen because of news coverage, if your product gets a good review, or you could just be exceeding your business plan on an ongoing basis, and you haven’t scaled up in house to meet it yet, or it happens to be the holidays and it’s just not worth having twice as many servers you will only need for a few weeks a year, when you can do that by scaling into the cloud. With NGINX this can all be done flexibly and even automatically.
35:42 Reason #4 – Adapt Quickly to Changing Demands

NGINX lets you adapt quickly to meet the changing demands on your applications. When you need to quickly add servers or add server pairs for high availability, you can’t wait for hardware to be ordered, delivered, received, tested, and do your iRules or whatever software configuration you need to do for them. iRules is also proprietary – the only time you need iRules is if you have an F5 server. It’s not a skill set that you can go hire for out of college easily. If your iRules person leaves, you’ll be hard‑pressed to find another one.
When it comes to configuration changes, often you can’t wait for network operations to approve changes. You don’t really want your changes to be put in the queue with things that are less urgent.
With NGINX there’s far less overhead for new project approval. With NGINX and NGINX Plus, you can keep some extra hardware in a closet when you’re talking about servers that cost $2,000 or $3,000. You can’t do that when you’re talking about multiple tens of thousands of dollars for hardware ADCs.
That kind of flexibility, redundancy, ability to do what you need to do, when you need to do it, is a core feature of NGINX, and part of the reason that the people who use us love us so much.
37:08 Reason #5 – No Artificial Performance Constraints

Finally, with NGINX there are no artificial or contact‑driven constraints on performance. For NetScaler Enterprise Edition, the contractual limit on throughput for that server is 0.5 Gbps. Well, that’s ridiculous in an enterprise situation. The comparable NGINX setup running on industry‑standard hardware will support 20 Gbps. That’s 40 times the Citrix limit.
The other thing is that the Citrix number is a contractual constraint. If you go over it, your payment terms suddenly and dramatically increase. The 20 Gbps is a recommendation from us. So, that just means that when you get into that area, you might start to notice your performance lowering a little bit, and you might think it’s a good idea to get another server and load balance onto it. But you have the flexibility; you decide. You don’t get a sudden ding in your budget.
With Citrix, it’s like running into a stop sign. In that scenario, more business can be bad news. One more customer can cost you a bunch of money, a few more customers can cost you a bunch of money because they put you over these caps. When you’re using NGINX, having more business is good news, and your costs are scaling steadily with your increased revenue from your increased customer base.
We often get urgent calls from people who are over these caps, and suddenly they’re over budget. And they’re not going to get back on budget without making a big change. Then they have to scramble to get on NGINX and get back into a good situation. Then, they often actually end up under budget because they saved so much money on NGINX.
But who needs that headache? As well as the uncertainty, and feeling of dread when you suddenly run into this terrible budget/performance conflict? Switching to NGINX early on means you can be completely free of that.
40:00 Resources
- Case Study – NGINX at WordPress.com/Automattic
- Case Study – Montana Interactive Improves App Performance & Customer Service with NGINX Plus
- Case Study – How Buydig.com Scales and Secures Its Microsoft .NET App Without Changing a Single Line of Code
- Ebook – 5 Reasons to Switch to Software for Load Balancing
- Blog – NGINX Plus vs. F5 BIG‑IP: A Price‑Performance Comparison
- Blog – NGINX Plus vs. Citrix NetScaler: A Price‑Performance Comparison
- NGINX Plus free trial


