

![Title slide for applicaiton security tips [presentation by Stepan Ilyan, co-founder of Wallarm at the nginx 2016 conference]](https://www.nginx.com/wp-content/uploads/2019/01/Ilyan-conf2016-slide1_title.png)
This post is adapted from a presentation by Stepan Ilyan of Wallarm at nginx.conf in September 2016. You can view a recording of the presentation on YouTube.
Table of Contents
0:00 Who Am I?

Stepan Ilyin: My name is Stepan, and I’m the cofounder of Wallarm. Wallarm is a smart web application and API security solution. We help companies protect their websites, applications, and their web assets from being hacked.
Some Stats

Let me start with some stats. According to Verizon, 26% of all data breaches happen because of vulnerabilities in web applications. Web apps are exposed to the Internet, and are accessible by your customers, but unfortunately they are also accessible by the bad guys. It’s a kind of low‑hanging fruit for everyone.
Security was always hard, and now it is becoming an even more sophisticated task for everybody. The problem here is that more and more enterprises want to run faster, so everybody is implementing a CI/CD approach. Literally every developer now can push his code to production very easily, and security is a big pain in the neck.
Agenda

The agenda for today is to cover some of the tips and tricks that you can use with NGINX. We will learn how you can mitigate some of the attacks targeting vulnerabilities in your applications, how to stop some kinds of the bots, and how to mitigate some very basic DDoS attacks on the application layer.
2:11 Why NGINX?

Because you already have NGINX, you already have traffic through NGINX and you already terminate SSL encryption through NGINX. It’s a perfect location to run some additional checks. It can be very important to do even if it’s only in detection mode.
2:41 Attack Blocking with NGINX
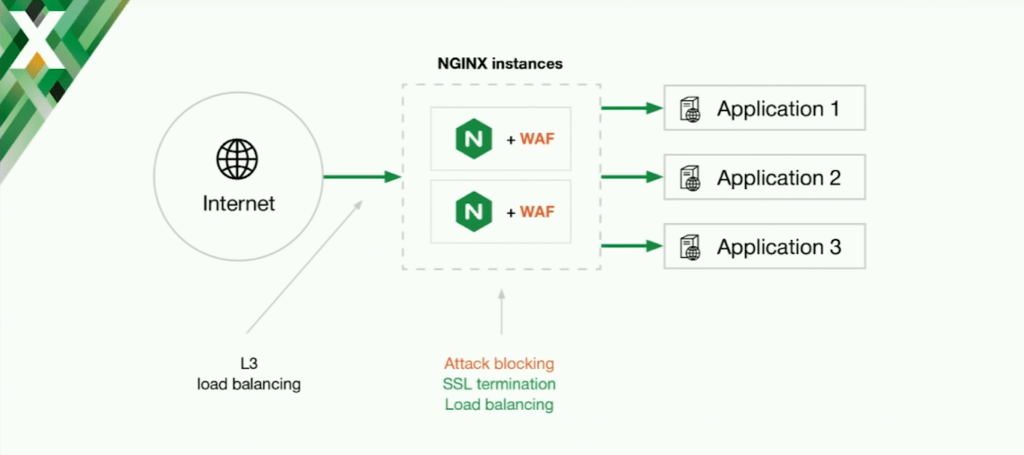
So you already have some service with NGINX. From our practice on this service here, you also have some capacity. NGINX is a very smart and very efficient piece of software and you have large servers, so in many cases you will be able to run additional checks right on the same machines.
3:05 Chapter 1 – Detect and Block

The first chapter is based on how we can actually detect some of the attacks targeting the vulnerabilities in your applications.
3:14 Tip #1 – Use the ModSecurity WAF

ModSecurity is the number one thing you can do.

ModSecurity is a very popular open source web application firewall [WAF]. It analyzes every incoming request and tries to match the content of the request with a library of malicious patterns, also known as signatures. If there is a match, then it will block it. This is the basic idea behind the every web application firewall.
ModSecurity originally was originally developed for the Apache and three years ago it was not possible to use it with NGINX in production. Now we can use it in a production and it works really well.
So what will it help protect against? It will protect against all the of the top ten attacks: SQL injection, cross‑site scripting, etc. It also supports virtual patches. For example if you have WordPress or PHP with a new vulnerability and you don’t have the opportunity to patch it right away, you can apply a virtual patch and block all requests that try to exploit this vulnerability. In some cases when you can’t apply [an actual] patch, this is very valuable.
Deployment is Easy

It’s very easy to plug in to NGINX. You just put ModSecurityEnabled on in your location block and then you have the traffic analysis for this part of the request.
What The Rules Look Like

This is an example of the ShellShock virtual patch. ShellShock is a kind of vulnerability that affected a lot of applications a year ago. You can just put this regular expression, which will try to find a malicious vector in the headers, and you can just block it.

Unfortunately these rules are regular expressions, so it’s a painful process to tune them. At some point you will see that you have a lot of rules like this. Regular expressions are very hard to write and even harder to read.
Core Rule Set (CRS)

The good thing is that there is something called the Core Rule Set. It has rules to describe all kinds of attacks that target your application and it is very well supported by the community and the company behind ModSecurity. There is also a commercial rule set available so we can buy a subscription and get the updated version of the rule sets, usually with different virtual patches, which is really cool.
More Rules, More Overhead
The problem you need to be prepared for is that maintaining the rules is a big pain in the neck. You can turn on ModSecurity with the default rule set for your application and you will instantly get a lot of false positives. Unfortunately you have a lot of people from the business side who will question what you’re doing because of this.
Right now we are literally banning our customers, so you need to tune these blocking rules. You need to understand what rules you can apply and what the rules you don’t need to apply. This is a process that you need to maintain continuously. Be aware that when you update the application, you probably will need to update the release of the security rules from ModSecurity – this is tough.
When ModSecurity Is A Pain

This is the slide about how hard it is to maintain everything.
Best Practice

A good practice from my point of view – seen at a lot of big enterprises and some tech companies – is to use public rule sets that are available for everyone, but only in detection mode. This is so you don’t block anybody, but you will see the alerts and you can react to them.
When you want to create a special rule to, for example, detect some particular type of attacks that are most critical for your application, you can write rules for your application or API.
Use Request-Response

When you do so, it is usually very helpful to create a set of two‑phase rules. When you analyze, it fills the request and then you analyze and create a signature for the response as well.

This is an example of a request which has a malicious pattern like /+etc/+passwd. As you see, it is very easy to write. It’s not rocket science.

Then you create a signature for the response as well. As you see, there is a regular expression which tries to find content in /etc/passwd. If there is a match for the request signature and the response signature, we can just block it. This is just an example of how you can craft security rules in a quite convenient mode.

What I definitely recommend to everybody who wants to use ModSecurity is to read this book by Ivan Ristić. It is called ModSecurity Handbook, and it covers a lot of topics – everything you need to know about ModSecurity. I highly recommended it.
9:27 Tip #2 – Use NAXSI

There is also NAXSI, and this is another web application firewall.

NAXSI was originally developed for NGINX. It stands for “NGINX Anti‑XSS and SQL Injection”. The good thing about NAXSI is that it doesn’t rely on signatures.
NAXSI Security Rules

It uses a set of scoring rules and it tries to find a very small subset of malicious symbols. Examples are the SQL operators <, / [slash], or drop that are not supposed to be a part of a URI.

Once any of those characters or expressions match with incoming HTTP requests, NAXSI will increase the malicious score of this request. It creates scores for SQL injection attacks, cross‑site scripting attacks, and so on. So if the request score is more than a certain threshold, NAXSI will block the request.
Example for SQLi

The good thing here is that you don’t need to write these regular expressions and you can run NAXSI immediately on your traffic. The bad thing is that you can’t use it without union as well as ModSecurity. For example, this is a rule which tries to find SQL operators in the request, which is usually a characteristic of a SQL injection.
If somebody is doing SQL injection in the login form of a bank site, it is probably a SQL injection attack. However, if somebody is putting a SQL injection payload, for example, in an article on Stack Overflow, this is not an attack. It’s the normal behavior for that application, so you need to adjust NAXSI for your application.
Allowlists

This could be implemented using allowlists. What is an allowlist? It’s a special way in which you can create rules saying that malicious patterns are alright for a particular application.

It looks like this, but don’t worry. You don’t need to enter it in manually. NAXSI has a special tool that you can run and it will learn from the traffic when you need to create an allowlist. Unfortunately you can’t run this learning continuously, so you need to turn it on in the config file and inspect the traffic for the next 24 or 48 hours. Then you will be able to create your allowlist.
Pros and Cons

The good thing here is that NAXSI is very fast and it is in many cases much more resistant to so‑called bypass techniques where the developers can obfuscate the request and bypass the web application firewall. You also don’t need to write the signatures.
The downside is that you need to use LearningMode for every update of your application, which is a pain in the neck.
Kibana and Elasticsearch
In the last version of NAXSI you can also connect Kibana and Elasticsearch and export all of the events, which can be very helpful to you. I recommend to do this.
12:57 Tip #3 – Try Commercial NGINX-Based WAF

There is also a set of the commercial tools which are based on NGINX.

One of them is the Wallarm company, where I am the co‑founder. The other one is Signal Sciences.
Wallarm and How It Works

In most cases, these solutions are based on machine learning.
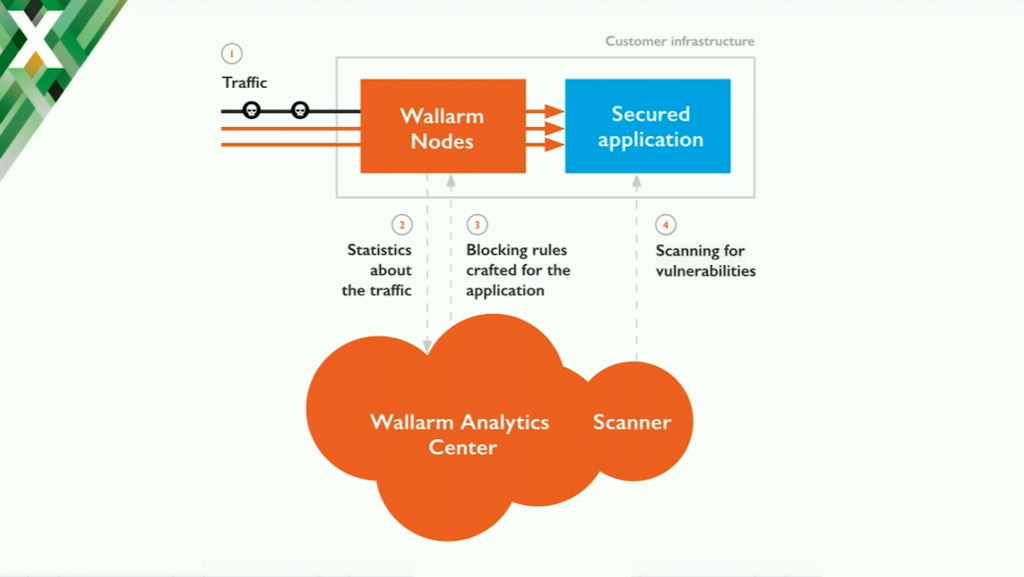
For example, this is how Wallarm works. We field the traffic right inside the custom infrastructure based on the NGINX instances, but we use machine learning to adapt dynamically for the application we are protecting.
Unfortunately we can’t run the statistical and machine learning analyses right on the load balancer or web server, so we sent all of the information about the traffic to our cloud. We create a profile of normal, everyday usage of your product and create security rules specifically crafted for your APIs and your applications. Then we ship them every 10–15 minutes to all NGINX‑based instances.
Something else that is helpful for situations where we have a lot of attacks: we can extract the payloads and exploits from the traffic and run special checks with our cloud‑based vulnerability scanner to figure out if the syntax has exposed vulnerabilities. Literally we can say you have thousands of attacks, but you need to care about only one of them because it is exposed in SQL injection in some particular part of your code.
Wallarm GUI
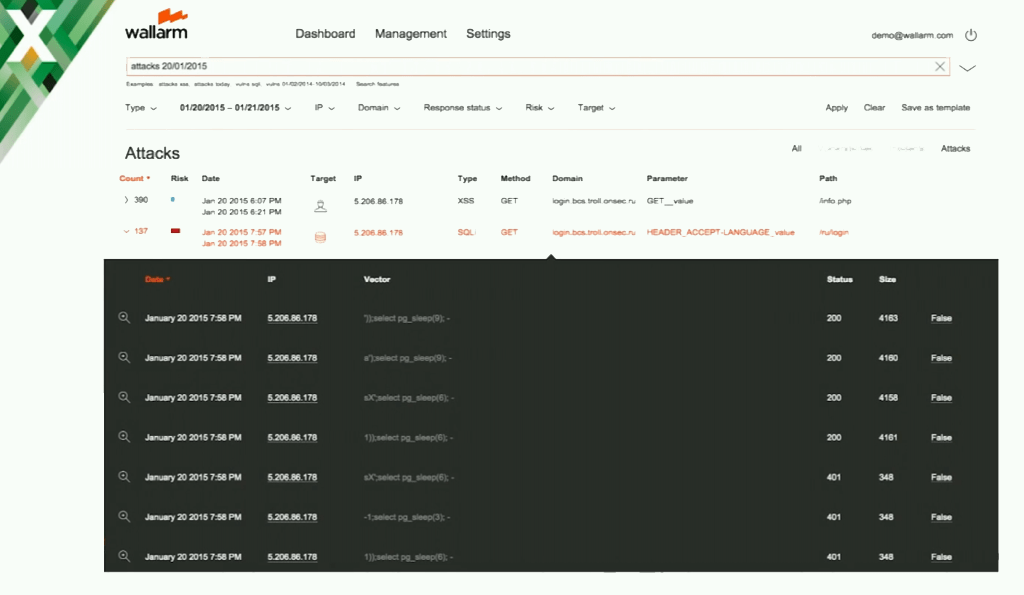
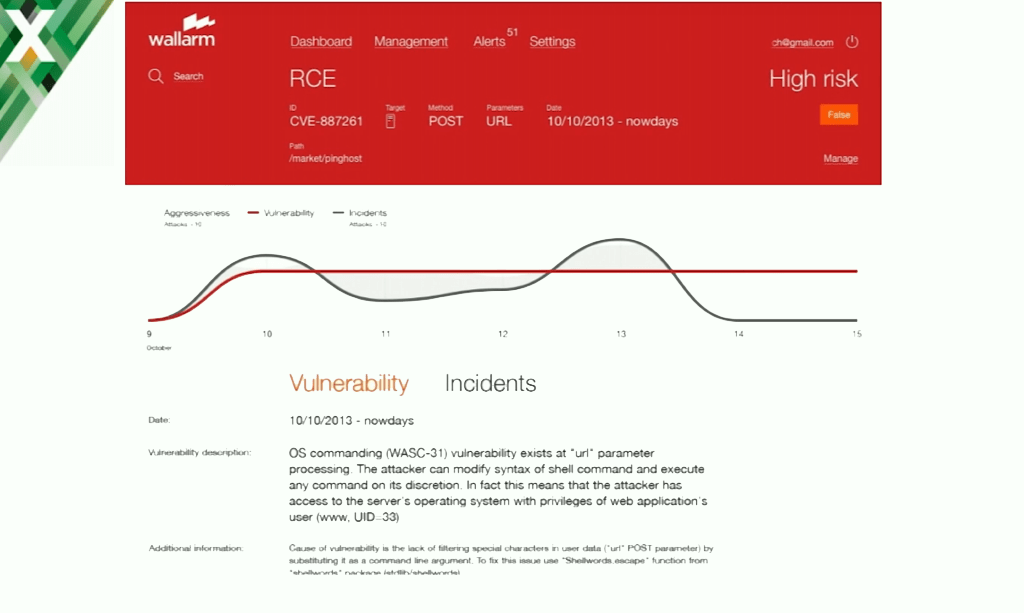
So we show information about attacks and about vulnerabilities.
14:44 Tip #4 – Try Repsheet

The next tip is to use Repsheet, which is a kind of behavior‑based security. This is a special module and actually a set of the tools which is developed by the guy from Groupon and Braintree.
Anti-Fraud Platform

Repsheet is a kind of reputational engine designed to help you manage threats against your application and it uses a behavior‑based approach.
Different Resources to Score Requests

The good thing about Repsheet is that you can use different sources of information to score the request and analyze if it is malicious or not. It could be the information from HTTP headers or from GeoIP.
You can also use the ModSecurity passive‑mode alerts here and some external feeds – for example, feeds with bad IP addresses which are known to be part of the botnets. Additionally, you can write a lot of other tools based on the logic of your application.
Repsheet Components and Architecture

Repsheet consists of several parts. There’s a module for Apache and for NGINX, there is a core library with the logic for how the text and the fraud situations are detected, and there is also a tool for visualizing the alerts.
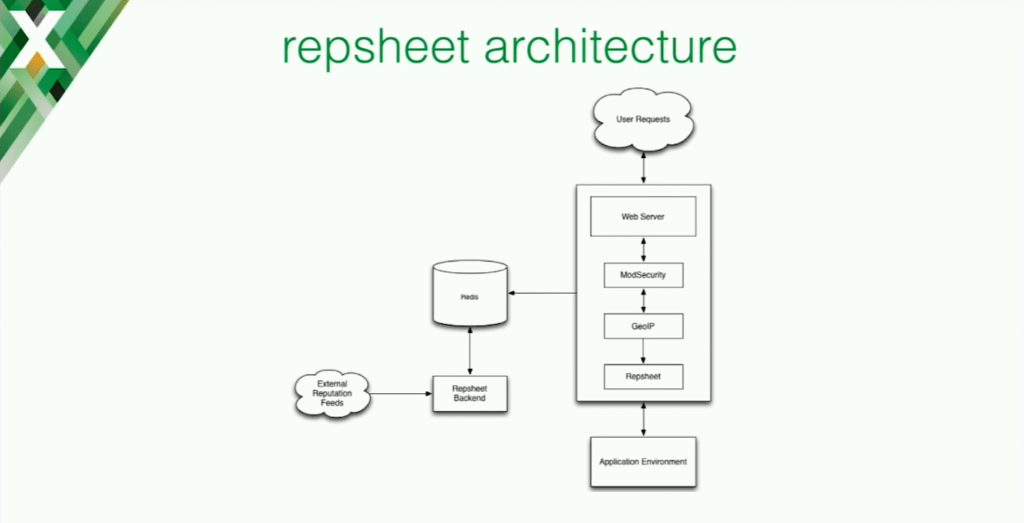
The architecture is actually pretty simple. You have your … ModSecurity [module], for example, and the GeoIP and Repsheet modules, but you also have the Redis database where you can put a lot of different information that can be helpful for detecting malicious requests. This is the thing that’s used by Repsheet to analyze information from different resources.
Malicious Attacks Map
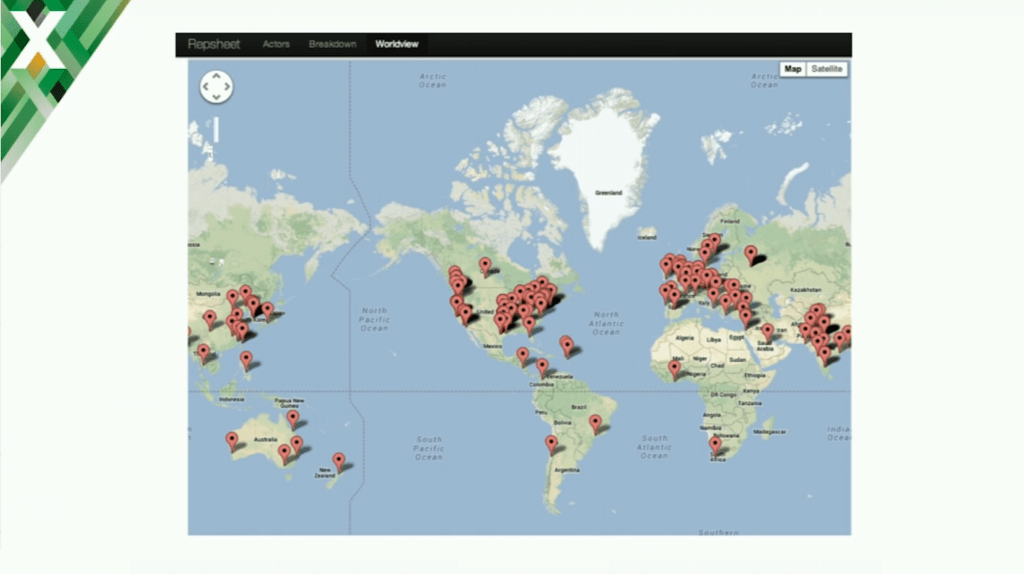
As a result, you can see some malicious attacks coming from different parts of the world. You can see which rules [were] triggered and you can block some of the users, but be aware that this product needs to be configured specifically for your environment, your API, or for your applications. It’s not a thing that you can install and start using it [out of the box].
17:24 Chapter 2: Deal With Bots And DDoS
The next chapter is not about the attacks. It is more about how to mitigate very basic DDoS attacks on the application layer and how to detect bots.

There are a lot of people now who try to scrape site content and who try to abuse your API by running complicated requests. There are a lot of attacks like DirBusting and brute‑forcing when somebody is making a lot of requests to your application.
This is actually a trend. We have a lot of customers now who are faced with people abusing their applications. For example, travel companies pay for every search request to the Global Distribution System (GDS) where they get information about flights and seats available.
These guys literally pay money if somebody uses their site or the API to find this information, so this is a big deal for a lot of people now. We can do something right on NGINX to mitigate these kinds of attacks.
18:32 Tip #5 – Use test_cookie Module

One of the most efficient ways is to use the test_cookie module. It is developed by the guy from Yandex, and it is very efficient and very simple.

The way that you can deal with this problem is that most of the HTTP bots are rather stupid. They do not support redirects and in many cases do not support cookies. Also, if it is not a full browserὝstack bot, it doesn’t support JavaScript. You can use all of this to identify bots.
The test_cookie module runs several very straightforward checks. It just checks if the client supports cookies, if the client can perform HTTP redirects, if it supports JavaScript, and so on.
How test_cookie Works with Wallarm
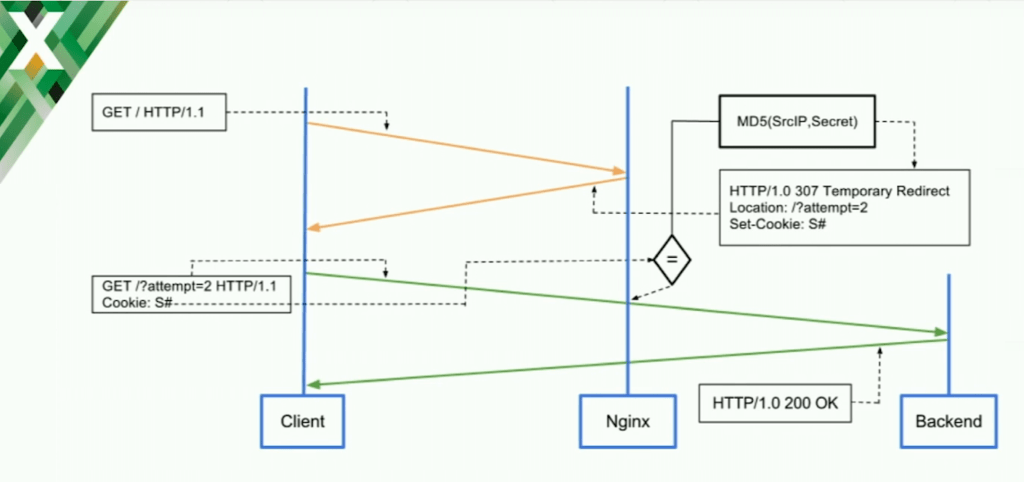
This is how the scheme works. When the request is going to the server, the test_cookie model creates a cookie and redirect so it can check if the client still goes to the website. It’s a basic check whether it supports a redirect or cookies.
How test_cookie Works with NGINX
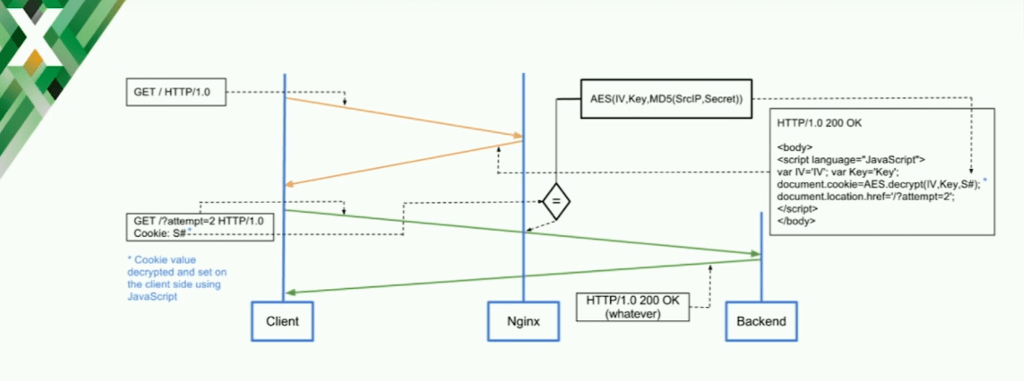
There are some more complex jobs for the bots. For example, if the bots support cookies and redirects, you can also give them what is called “proof of work”. You can give them a task to calculate something, which is also implemented with a test_cookie module. It really works well against the bots that are not full browser‑stack.
Full browser‑stack bots are just infected machines where the real browser is open in the background process. It is very hard to deal with them, but most of the bots now are very stupid so we don’t need to care about this a lot.
Side Effects and Drawbacks of test_cookie

The side effect of using test_cookie is that you block all the bots and prevent automatic parsing, but you also block all other bots including Google bots.

Be aware of this moment because it can kill your sale. You need to allowlist the IP addresses of all the search engines so it can find them in the Internet and with the special parameters. The best thing to do is get the IP addresses of these bots and allowlist them in test_cookie. Once again, it will not help you against the botnets with the full browser‑stack bots.
21:45 Tip #6 – Neural Network and Machine Learning

In case of more sophisticated problems when you are facing a really complicated botnet, probably the best thing you can do is to find a commercial tool. It is a very hard question when you need to run behavioral analytics to identify malicious requests.
Distinguishing Requests Manually

If you have time and you have the desire, you can try to play around with the log files to use neural networks and machine learning to identify good requests based on the log file. In many cases you can identify which request is bad and which request is good by your eyes, so we can train the neural network to do it for you.
AI to Detect Bots

This is a proof of concept. You can just take a look at the special script which uses PyBrain, so it’s written in Python. You can use it to identify bad requests and good requests based on the access log file.
Logs With Legitimate Traffic

To train this in the best way, you need to have a log file with good traffic for some considerable amount of time because otherwise you won’t be able to train the system.
How To Deal With DDoS

The basic approach of how to deal with a DDoS attack is actually to analyze data from the access log. Once again, we’re speaking about very basic DDoS attacks. If you are facing the very severe attack, you probably need to get a commercial tool to defeat it. But if you are facing some attack that’s not that difficult, you can try to do something by yourself.
23:51 Tip #7 – Code 444

In this case, you need to read the access log file and use some special tricks. NGINX supports status code 444, and it allows you to close the connection and give nothing in response.
Disable Resource-Intensive Parts

In a DDoS, the attackers will probably try to find the part of your application that consumes the most resources. For example, they will try to send a lot of requests to Search because they see that these requests make your application feel bad. If you see that all of the requests are going there, you can just ban them temporarily.
Code 444

The best way is to use code 444. You can just put this return 444 at a special occasion, for example, to turn off search. This is a kind of trick which could be quite helpful for you.
24:50 Tip #8 – Use ipset to Ban Bots Quickly

You can also use ipset.

If you see that most of the bots are trying to, for example, attack the search part of the application and you have already given them 444 in response, you can try to extract strings from the log file and ban all the IP addresses with a special script that is on the screen now.
You extract all the logged strings where you ban the customer, put 444 as the response code, and add it to the firewall to ban.
25:40 Tip #9 – GeoIP Banning

The next tip is banning by GeoIP. I personally don’t like this because GeoIP information is not accurate in many situations.

It’s not likely that you’re 100% sure that all of your customers are malicious in a particular country. In most cases it is not true, but be aware that you can use the GeoIP module (ngx_http_geoip_module) just to ban strictly requests from certain countries.
So if you see that there is a kind of attack coming from Europe or from Asia and you’re absolutely sure that most of your customers are coming from somewhere like California, you can use GeoIP to instantly ban those requests. But be very careful with this.
26:33 Tip #10 – Limit Buffers and Timeouts in NGINX

The next tip is not about attack mitigation. It is more about how you can prepare for DDoS attacks and to be prepared for the massive loads.
Every Resource Has A Limit

Every source has a limit. You can just install NGINX and believe that everything will be okay, but it will not be. You need to set limits for all the resources you are using with NGINX, and particularly memory.
NGINX Directives to Limit Buffers and Timeouts

NGINX has special directives to limit buffers like those listed on screen.

There are also directives to limit timeouts. The list of them is on the screen.
Finding the Right Values for Buffers and Timeouts
The main question is: what are they right values for the buffers and timeouts? Unfortunately, no one can give you an exact answer.

There are different approaches that deal with how we can play around with them.

What we typically recommend is to set a minimum value for the parameter and just see how your application works. If your application works without any problems, then the parameter is probably alright. But if something is going wrong, you need to increase the value of the parameter, perhaps double it, and run your tests again.
This is a kind of iteration process. Unfortunately it depends a lot on what your application is about – what requests you have and so on.
Benchmark It

You also need to benchmark your application to see how many requests you can handle in a normal situation. These are the kind of parameters that you also need to put in your NGINX config file because there are special directives to limit the connections.
They limit the request rate, so we need to put all that data in your configuration file just to be sure that in case of the DDoS attacks you have all those parameters predefined. It will really help a lot.
28:57 Summary

This is a kind of summary about what we were talking about today. You can use web application firewalls to mitigate all attacks through SQL injection, cross‑site scripting, and all other kinds of application vulnerabilities.
There are open source tools like ModSecurity and NAXSI. They are free to use, but be aware that you will have some costs to maintain them. In many situations you need a person who will be allocated to run all those things.
There are some commercial tools like Wallarm and Signal Sciences that use NGINX as a platform to analyze the requests in a more sophisticated way. Usually it’s machine learning, it’s an understanding of your application structure, and it’s dynamically adjusting all of the blocking rules for your specific application.
You can use Repsheet to use different sources of the information and to ban users based on the different sources and metrics. There is a test_cookie module that is very helpful to distinguish bots from human beings in your traffic. It analyzes if a client supports redirects and cookies.
You can use the information from your access log file and ban attackers using this information. There was an example where you can run machine‑learning programs to identify malicious requests.
You also need to be prepared for high loads from DDoS attacks. It’s very important to limit all of your buffers, timeouts, and your request rate. It will help a lot when you will face a real DDoS attack, and it is good to do this anyway.
30:55 Thank You

That’s everything that I wanted to say to you today. Thank you.


