


This post is adapted from a presentation at nginx.conf 2016 by Yichun Zhang, Founder and CEO of OpenResty, Inc. This is the first of two parts of the adaptation. In this part, Yichun describes OpenResty’s capabilities and goes over web application use cases built atop OpenResty. In Part 2, Yichun looks at what a domain‑specific language is in more detail.
You can view the complete presentation on YouTube.
Table of Contents
| 0:00 | Introduction |
| 0:33 | OpenResty |
| 1:41 | Lua Libraries |
| 2:25 | NGINX + LuaJIT |
| 2:45 | The All-Inclusive Philosophy |
| 3:31 | Simple Small Fast Flexible |
| 4:22 | Synchronously Nonblocking |
| 4:47 | Light Threads & Semaphores |
| 5:02 | Cosockets |
| 5:18 | Timers and Sleeping |
| 5:36 | Shm-Based Dictionaries and Queues |
| 5:52 | Dynamic SSL Handshakes |
| 7:33 | Dynamic Load Balancers |
| 8:48 | ngx_stream_lua_module (TCP & UDP) |
| 9:42 | Advanced Debugging & Profiling Tools Based on GDB & SystemTap |
| 11:32 | C2000K |
| 12:01 | Web API and Microservices |
| 12:57 | Web Gateways |
| 15:02 | Web Applications |
| 17:41 | New OpenResty Website |
| 18:15 | Distributed Storage Systems |
| 19:06 | Datanet |
| 19:41 | Conflict-Free Replicated Data Types |
| 20:02 | Forming a Stateful Network |
| 21:26 | Sregex |
| 23:28 | Sregex’s DFA Engine Performance Benchmark |
| Part 2 |
0:00 Introduction
Hello everyone. My name is Yichun Zhang. My “webnick” is agentzh. I’m currently working for Cloudflare as a systems engineer. I’m very excited to speak here. It’s a big room! I think mine is the last talk, which probably means we don’t have a time limit, right? I have prepared a lot of slides.
0:33 OpenResty

OpenResty was created 9 years ago, in the year 2007. I’m the creator of OpenResty and I’m currently the maintainer.
We have an official development team working on OpenResty’s new features and bug fixes. We also have mail lists, a relatively big community. We have both a Chinese mail list and an English mail list.
We also have a Twitter account, also called @OpenResty.
1:41 Lua Libraries

Also, over the years, we have accumulated many Lua libraries designed specifically for OpenResty.
OpenResty is essentially embedding LuaJIT (the Just-In-Time compiler for LUA) into NGINX, and we have all the nonblocking I/O abstractions that can help you build very complicated web applications.
These libraries provide many, many things, for example: MySQL clients and Prosquare SQL, MongoDB, RabbitMQ, and also health checks to NGINX upstreams. We really appreciate our growing community.
2:25 NGINX + LuaJIT
OpenResty is essentially NGINX plus LuaJIT, but we also invented a lot of our own abstractions like light threads and timers, thanks to Lua’s co‑routines support.
2:45 The All-Inclusive Philosophy
So, the OpenResty world encourages the all‑inclusive philosophy. Many of our users come from different open source communities like Ruby, Java, PHP, Node.js, and even Go. And Java, of course.
NGINX consists of a very interesting place where you can do very interesting things in the middle, like between your backends and your customers. So, it’s possible for OpenResty users to use hybrid solutions. Many of the users combine OpenResty with more traditional technical stacks.
3:31 Simple Small Fast Flexible

The goals of OpenResty are simple: to be very simple and very small in terms of memory usage and copy [?] size; also, it should be very fast.
We chose Lua because of its very good implementations. To tell the truth, I started learning Lua after working on the NGINX Lua module. I knew very little about Lua before. The choice of Lua is very pragmatic.
Also, it should be flexible. The goal is to support very complicated, large‑scale web applications atop OpenResty alone, though many users still use hybrid solutions. We also encourage that with a lot of choices.
4:22 Synchronously Nonblocking
The key of OpenResty’s I/O model is that it’s synchronously nonblocking. I know the word asynchronous is maybe too ubiquitous, but I think human minds think synchronously, not asynchronously. I hate callbacks, obviously.
4:47 Light Threads & Semaphores
We invented the light threads and semaphores to emulate concurrency, but with only one, single operating system thread.
5:02 Cosockets
And we invented cosockets. A cosockets just like traditional BSD sockets or Lua sockets, but it’s completely nonblocking. You just use it to write code, just like in PHP or any other language.
5:18 Timers and Sleeping
And we also have timers and sleeping primitives. You have asynchronous threads running in the background detached from any downstream requests handled by NGINX. It’s like cron jobs, right?
5:36 Shm-Based Dictionaries and Queues
And we also have shared memory‑based dictionaries and queues which expose very nice Lua APIs to the Lua code. All these things are based on the NGINX infrastructure. Why share memory? Basically, we want to share data among all the NGINX worker processes.
5:52 Dynamic SSL Handshakes

And we also started supporting dynamic SSL handshakes for downstream HTTPS traffic, just in the most recent months.

For example, at Cloudflare, we are a CDN provider, right? We have a lot of customers, a lot of virtual servers. And we also have a lot of edge servers making up our network.
One problem is: too many SSL certificates and private keys. To solve that problem, we can load the certificates and private keys on demand only when real traffic asks for them.
This way, we can theoretically support an unlimited set of certificates and private keys thanks to the locality of the traffic because there’s no way for a single machine to see all the possible customer traffic.
Also, with OpenResty, we can cache the certificates and private keys inside NGINX, both in shared memory and also on the worker-process level.
The data – such as certificates – are distributed, via Kyoto Tycoon at the moment, but other choices are also possible, like Redis or some other distributed data storage. We’ll talk about those very soon.
7:33 Dynamic Load Balancers

We also support dynamic load balancers in Lua in NGINX.

For example, in the traditional upstream configuration block, you can use a few lines of Lua code to define your own, complicated, dynamic balancers.
Dynamic means that you can use a different balancing policy on every individual request – on that level. It’s extremely flexible.
And you can also introduce retry policies. For example, when a particular peer that’s been selected fails the request, you can choose the next, and how to choose the request, and where to choose the retry. You have complete control in balancer_by_lua_block.
And with this, standard NGINX modules like Proxy, FastCGI, and uwsgi, all work out of the box. That’s the goal.
Also, the keepalive module, the connection pool module provided by the NGINX core, should also work out of the box.
8:48 ngx_stream_lua_module (TCP & UDP)

Just recently, I also created another Lua model: ngx_stream_lua_module. The previous one, the more common one, is ngx_http_lua_ module.
ngx_stream_lua_module utilizes the new stream subsystem in the ngx core which makes it possible to implement generic TCP servers and UDP servers.
Speaking of which, on the official OpenResty.org website: its DNS server is powered by this module. It’s an authoritative DNS server. I see people use this module to write generic TCP daemons like Syslog to accept a lot of online locked data screens.
9:42 Advanced Debugging & Profiling Tools Based on GDB & SystemTap
Over the years, we also accumulated a lot of advanced debugging and profiling tools most of which can be used safely online.
At Cloudflare, we have a large global network and things can go wrong. Sometimes, bad things happen only at a very low rate like 1% or even 0.1% or 0.001%. To troubleshoot such problems that are almost impossible to reproduce, we need advanced debugging tools.
We open-sourced most of our tools based on GDB and SystemTap:
- GDB is mostly for debugging dead processes, like analyzing core dumps.We used this approach, GDB and core dump, to help Mike Pall nail down ten very deep bugs in the Just-In-Time (JIT) compiler of LuaJIT which were hidden for years.
- SystemTap is a dynamic tracing framework provided by a bunch of very smart Red Hat developers, kernel developers. It allows you to analyze running systems, the whole software stack from the kernel to NGINX to your application Lua scripts, on the fly with minimal impact on the production server. You don’t have to drop the box or set up a firewall. You can do the live analysis. I think there’s a future for systems engineering.
11:32 C2000K
In recent months, we introduced several important features that make it possible for OpenResty-based applications to handle this much concurrency level in a single production box. It’s like 2 million concurrent connections.
Some of our user companies run such push systems online.
12:01 Web API and Microservices

Another very interesting use case is Web API and microservices. Many people use OpenResty to build such things, like Mashape’s Kong platform and Adobe’s API Gateway for cloud traffic.
Also, some United States banks use OpenResty to route their application traffic.
And also, some very big Chinese Internet companies use OpenResty to build real‑time stock market information services. Those interfaces are among their biggest interfaces, obviously, and there are other real‑time weather information interfaces. The possibilities are unlimited.
12:57 Web Gateways

Another very common use case for OpenResty is web gateways. Many CDN vendors use OpenResty, at least in the middle.
We also have people using OpenResty to run HTTP or generic TCP or UDP traffic.
Lua makes it possible to script your gateways on the fly. Because of the dynamic nature of the Internet, people other than CDN vendors have to handle many different customers, and the customers’ requirements are more and more complicated.
Some of the logic is even from the applications, and they want to run some of their business logic on the edge. It’s very common. They also want the capability to change the configurations in real time, at least software real time. People want such capabilities.
The choice of Lua makes it possible because we can use Lua Just-In-Time to “just-in-time” the code depending on the new configurations or new traffic load patterns. That’s the beauty of JIT because it uses profiling information to guide the code’s compilation and use different optimizations based on the load patterns. That’s exactly what we want, right?
NGINX does support HUP reload – reloading configurations based on a HUP signal. That’s way too expensive for CDN vendors. It’s not an option because you have to gracefully quit all your worker processes and start a bunch of new ones.
And the cache might be cold: I mean the code cache and sometimes the data cache. [To restart] for a single customer’s change, it’s just too much impact to all the other customers.
15:02 Web Applications

The original design goal of OpenResty was to support full‑fledged web applications. My first imaginary use case was to build a personal blog of my own, so I created OpenResty.
Nowadays, there are many ecommerce websites, some ad providers, and also some more traditional websites using OpenResty to build full‑fledged web applications from scratch.
For example, JD.com (Jingdong) is one of the largest B2C ecommerce websites in China. Their websites usually have a huge amount of traffic on the big marketing days. What Black Friday is in the United States, November 11th is in China.
They originally started with Starnet technology, and their service crashed horribly. Then they migrated to Java and again, their service crashed.
Eventually they migrated to OpenResty. They still have some Java asynchronously in the backend, but it’s all OpenResty in the front to handle all the traffic. And they couldn’t be happier. There have been no incidents since then.
They use OpenResty to generate the most complicated web pages of their website.
For example, this is an iPhone product page. It’s a product details page. Such pages [attract] most of their traffic. They use OpenResty’s Template Library to generate the HTML.
It’s a very long page. Here, I can only show the top of it. They have very large HTML pages with Lua templates. They use Redis to avoid the downstream request hitting their Java backends directly. This model works pretty well for them.
I asked whether I could optimize their system for them. They replied that their system was already running so fast, they didn’t bother optimizing it anymore.
17:41 New OpenResty Website
We also have a new OpenResty website. This site was just rewritten in Lua atop OpenResty from scratch. The whole application is in Lua.
And we talked to PostgreSQL, the database, directly. The nonblocking NGINX event model handles all the IO events for us. It’s very cheap and it’s blazingly fast.
It supports inside search thanks to PostgreSQL’s full‑text search index support.
18:15 Distributed Storage Systems

To my surprise, some of my users use OpenResty to build distributed storage systems. I really didn’t expect that.
One such user is one of the biggest web portal websites in China. It’s called Sina; some of you might have heard of it. There are some very interesting products. It’s like Jawbox or something.
They not only use OpenResty for the front end, they also use it for the backend, handling file I/O directly. And they were pretty happy with that. One of their core developers has become a contributor at OpenResty.
19:06 Datanet

Another thing that the community is contributing is Datanet. I think this is the first public announcement of it. But it’s not open source yet. We’re still working on it and testing it.
The author of Datanet is Russell Sullivan. This is his Twitter handle: @jaksprats. You can tweet at him and say hi. He’s building a distributed data network atop OpenResty, mostly.
19:41 Conflict-Free Replicated Data Types

A standing point of this thing is that it uses CRDT, Conflict‑free Replicated Data Types. Frankly, I know nothing about this. Very complicated algorithms, 4 distributed systems, and the papers are very hard to learn, but the result is wonderful.
20:02 Forming a Stateful Network
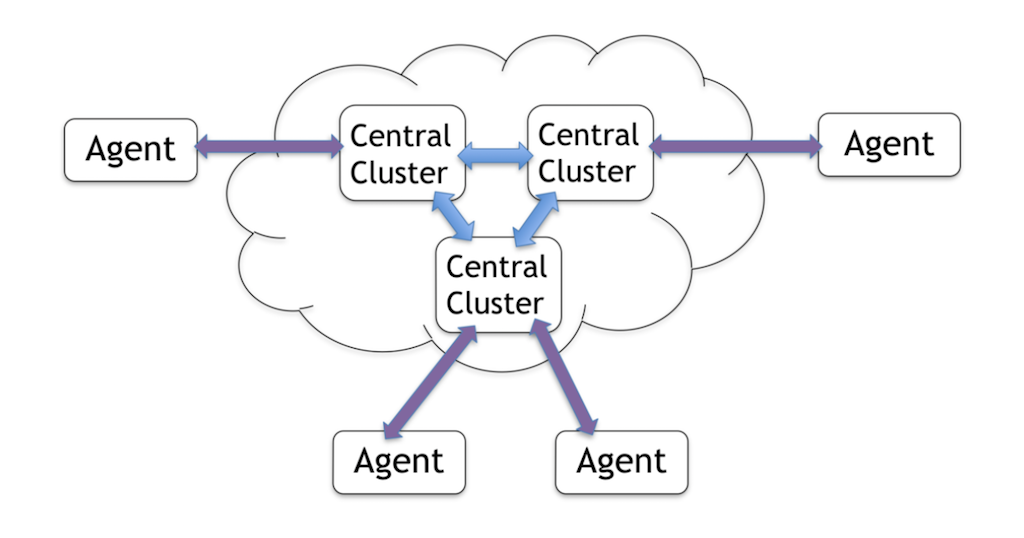
Basically, you can form a stateful network. Each node in your network can have state, and they can make changes or create new data, and the changes and the creation will populate to the other nodes in a semi‑P2P fashion. And the low latency is guaranteed to some point.
I said that’s semi‑P2P, right? Why’s that? Because it has to have some kind of “central,” but it’s a mesh of central clusters. It could be just a few big data centers, and all other PoPs or mini‑PoPs can sign up to a central network. And all of those form a stateful network. It can be geographically large.
Also, some of the agents may go offline temporarily, and they can accumulate local changes. Once they come back online, their accumulated local changes can populate as soon as possible.
I won’t talk more about that because the topic would deserve another hour or two.
21:26 sregex

sregex: I’ve been building my own regular expression engine, not just for fun, but also for real business requirements. It’s called sregex.
Basically, it supports streaming processing. The web server should handle very large data streams, or theoretically, infinite data streams.

The key is to use a constant buffer, a buffer with a [indistinct; possibly “bar” or “baud”], often a very small barn like 4 KB or something.
When data comes in, we process it, we get what we want, we make our decisions, like: we drop it or we let it through.
But everything should work in one‑way fashion. Once the data trunk is processed, it’s history, because the buffer is refilled by the next data trunk.
The idea is very intriguing, but the algorithms can be very difficult. Many traditional algorithms just won’t work.
![]()
The backtracking algorithm is very popular in mainstream regular expression engines.
Basically, when you fail to find some match, you may have to move the stream pointer backward to retry, right? So this is a backtracking algorithm. PCRE and many other regular expression engines use a backtracking algorithm. It has many problems, not just using a fixed buffer.
It can also lead to exponentially expensive behavior. We call it pathological behavior.
23:28 Sregex’s DFA Engine Performance Benchmark
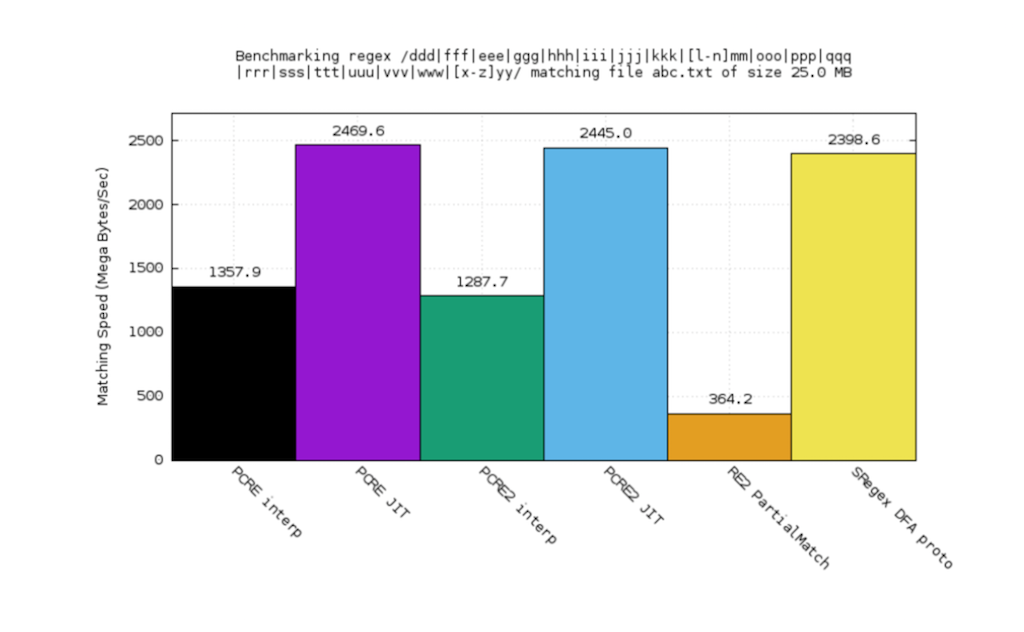
I created a DFA [deterministic finite automaton] engine for sregex. The performance benchmark looks pretty promising. You see the orange part? That’s Google RE2. The purple one is PCRE JIT. The black one’s PCRE interpreter. The green one’s PCRE2 interpreter. The blue one’s PCRE2 JIT.
PCRE is a very popular C library for supporting Perl‑compatible regular expressions and it also comes with a very nice JIT compiler.
For this case, RE2 plays really badly, but the backtracking engine plays well, especially the JIT1. And the sregex, the other one, is comparable.
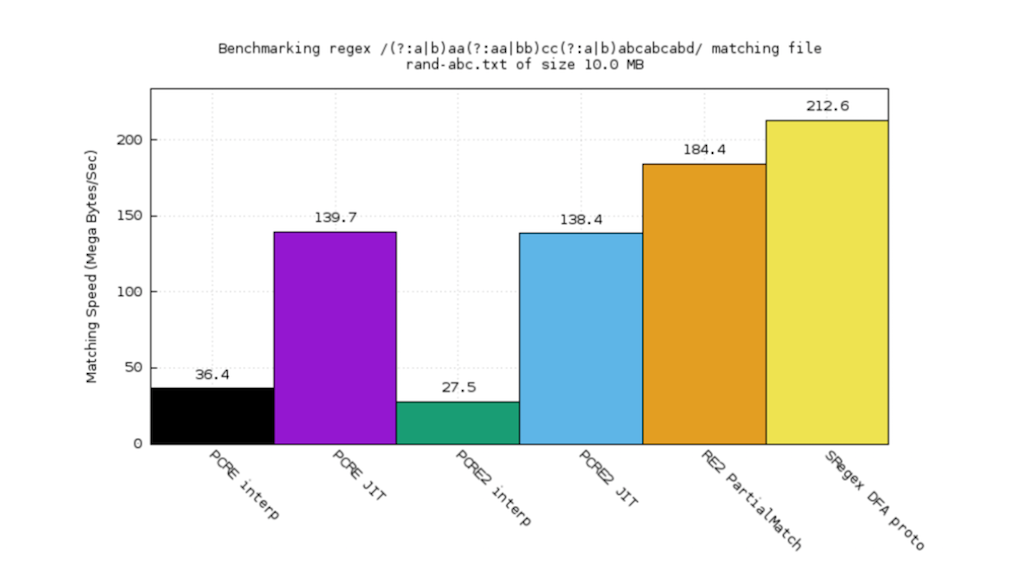
For this test case, we can see that RE2 plays better than PCRE, especially better than the interpreter, but we are even a little bit better.
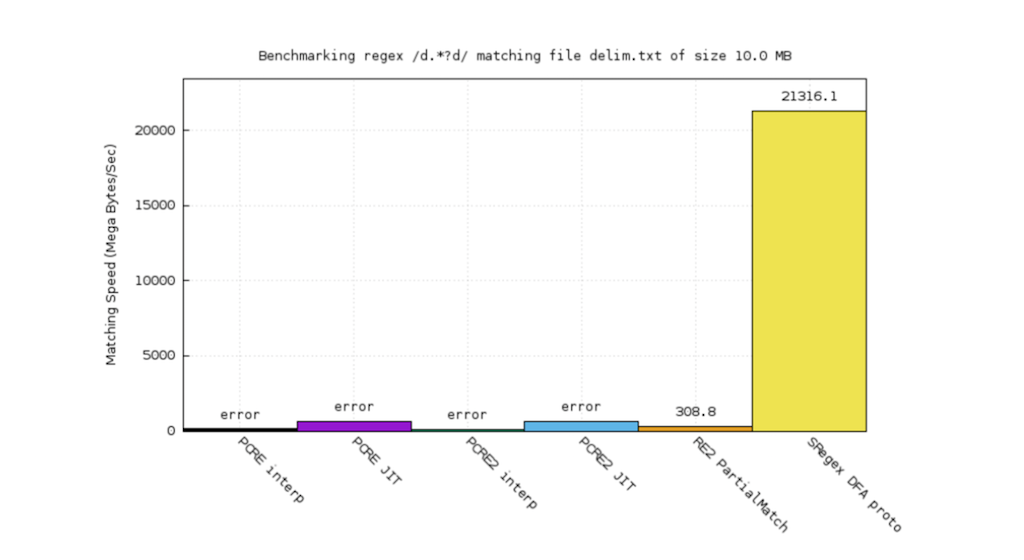
For this very simple regular expression, d.*?d, we win by a very wide margin. Because a DFA engine can disintegrate things and do very clever optimizations.
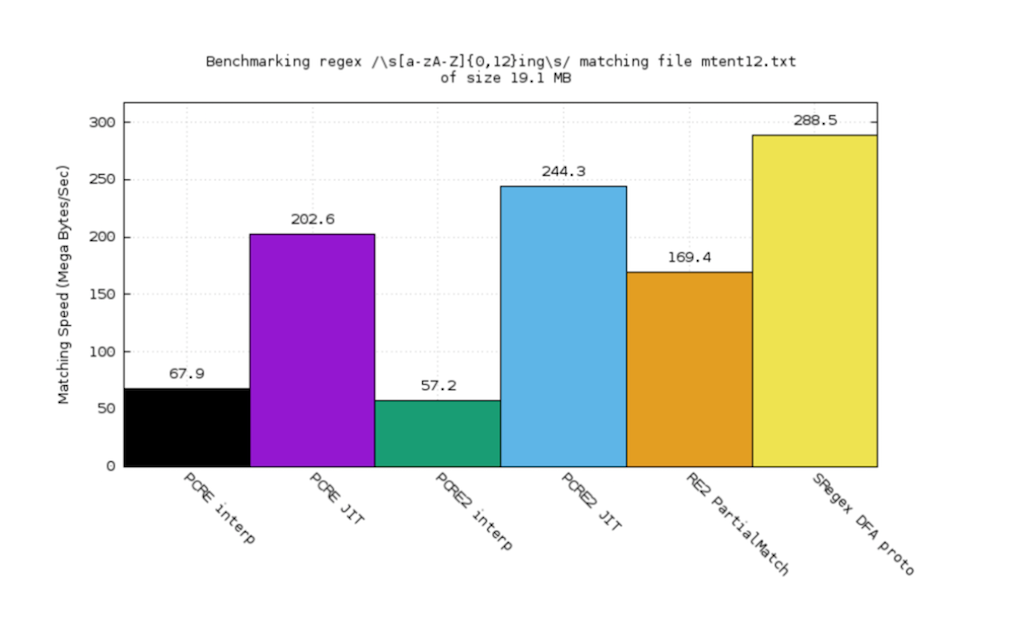
This use case is from PCRE’s benchmark test suite. Also, we’re a bit better (the yellow one).
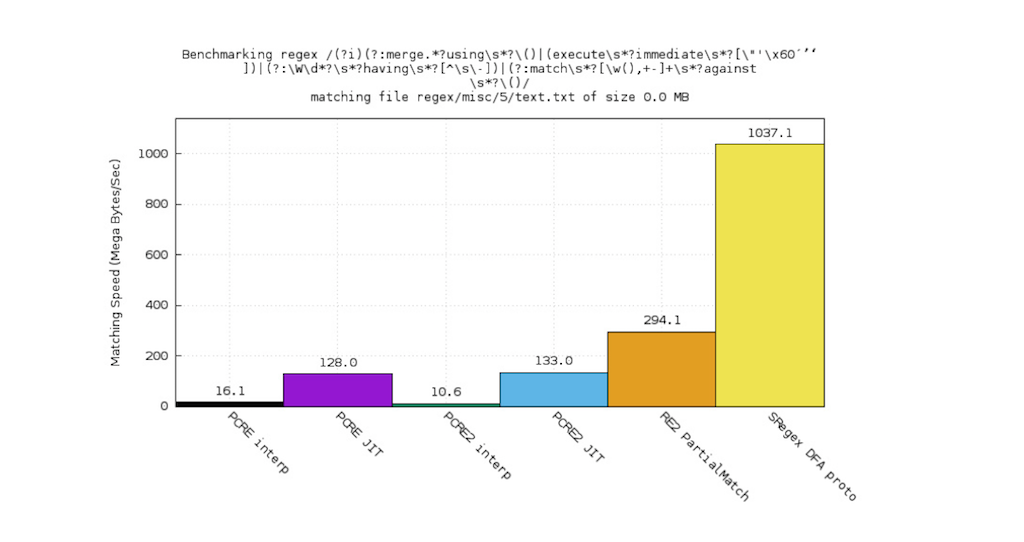
This regular expression is extracted from ModSecurity’s core rule set for web application firewall (WAF) filtering. The backtracking engine plays really badly. It consumes a lot of CPU time because of backtracking.
sregex’s DFA engine is wonderful. It processes very fast and without looking backward, just going straight ahead.
sregex will be our next big thing at OpenResty.
What you’re seeing is not a production‑ready thing; it’s just a quick prototype. Everything’s in Perl.
I used about 2000 lines of Perl to write a regular expression engine compiler that can generate C code. The resulting C code is compiled by Clang or GCC. I cheated a bit just for proof of concept.
I think my JIT compiler can do better than Clang or GCC because their optimizer is way more generic.
This post is adapted from a presentation at nginx.conf 2016 by Yichun Zhang, President & Founder of OpenResty, Inc. This is the first of two parts of the adaptation. In this part, Yichun described OpenResty’s capabilities and went over web application use cases built atop OpenResty. In Part 2, Yichun looks at what a domain‑specific language is in more detail.
You can view the complete presentation on YouTube.


