


This post is adapted from a webinar hosted by Floyd Smith and Michael Hausenblas of Mesosphere. This blog post is the second of two parts, and is focused on immutable infrastructure. The first part focuses on microservices. You can also watch a recording of the webinar.
This part of the webinar focuses on immutable infrastructure, which is defined in an in‑depth article from O’Reilly as follows: “once you instantiate something, you never change it. Instead, you replace it with another instance to make changes or ensure proper behavior.”
Table of Contents
| Part 1 | |
| 19:21 | Immutable Infrastructure |
| 20:17 | Why Immutability? |
| 21:43 | Container Lifecycle |
| 23:18 | Tooling |
| 25:16 | Tooling (cont) |
| 28:18 | p24e.io |
| 28:56 | O’Reilly Book |
| 29:19 | Resources |
| 35:00 | Questions and Answers |
19:21 Immutable Infrastructure

Michael: Let’s take a look at the concept of immutable infrastructure, which is an underlying idea important for running containerized microservices in production.
The idea of immutable infrastructure fits into the larger context of the programmable infrastructure concept. This is the idea of applying the tooling methods of software development onto the management of IT infrastructure. Automation obviously is very important, as well as versioning and APIs; immutability is also one of the core concepts involved.
So, let’s have a look at why. Why immutability?
20:17 Why Immutability?

We know that, by subscribing to the DevOps paradigm, you can iterate faster, you can deploy many versions per day. Immutability supports that. It gives you the ability to do iterations way faster than if you have mutable infrastructure.
Another aspect is what I like to call the human fault tolerance. People make mistakes and there’s a Facebook study out there that looks at when incidents happen. It turns out they happen from Monday to Friday, between 9 AM and 5 PM – when people are around, basically.
The systems themselves do well. The self‑healing properties of container orchestration systems are so good already that the human poses quite a big risk screwing up some configuration, or trying out something in production that they shouldn’t. Immutability protects against that. It increases the human fault tolerance.
It also simplifies operations, because it’s immutable. You can’t change anything on the fly, so as nothing can go wrong in that sense.
21:43 Container Lifecycle
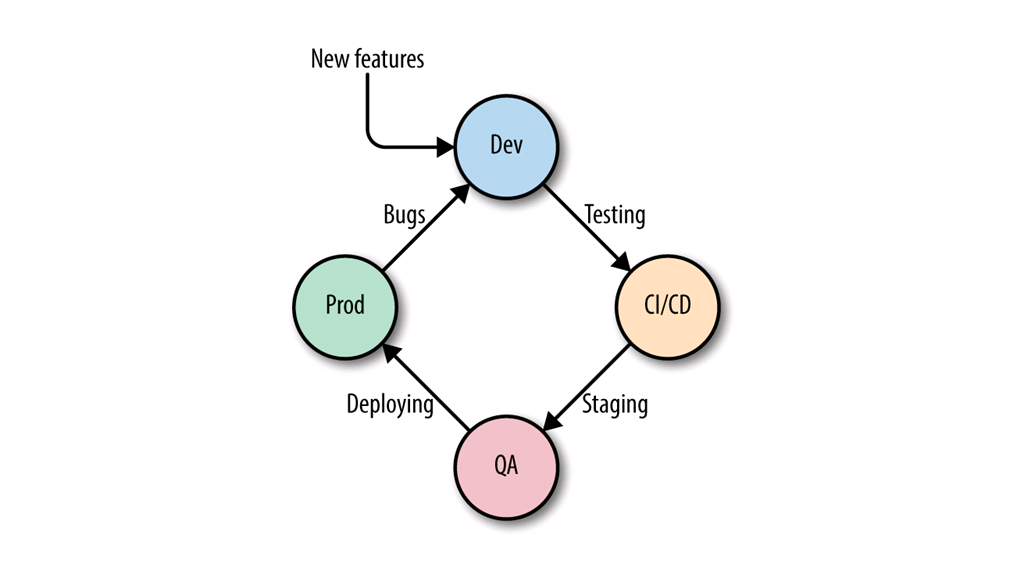
Let’s have a look at the life cycle of a container, or microservice‑using containers. We start at the top, in development. So for example, that could be your developer laptop where you’re creating your application and building a Docker image. So I add a couple new features there, and at some point in time you then run those through your CI/CD pipeline – your continuous integration, continuous delivery pipeline.
You might also have a staging area, where you do QA. And at some point in time, once QA is passed you’re deploying the container into production.
Then, from production, you learn about bugs, that could potentially be used to set inputs for bug fixing in the next iteration.
The faster we can run through that cycle, the faster we can go from Dev to CI/CD to QA to Production, back to Dev, and the better it is.
Moving faster means smaller features; you’re not deploying 15 or 20 new features, you’re deploying one new feature and immediately learn about how it is doing.
At the end of the day, we really want to be able to go through that cycle as fast as possible. To think about that in a 3D way. It becomes a spiral that would incorporate each new feature, each new bug fix that you would have in production.
23:18 Tooling

Okay, so the concept of immutability is one thing, but as a practitioner, you probably want to know how to actually go about it. What do I need to do, and what tools, what things do I need to use?
Since we’re using containers here, on your host or your node where you’re running your container, you will need to provision the base operating system. There are container‑native operating systems like CoreOS, otherwise you need to provision a Docker runtime. For the container runtime, Docker is one, but there are others now as well; Rocket, for example.
Floyd mentioned load balancing and that’s often a must‑have for real world container deployments. With load balancing you’re spreading the incoming traffic amongst a number of containers, a number of instances at the same time.
Of course, you’ll want to be able to do logging. You need to log against different levels – things within the container, things that are happening on the host operating system, as well as on the container orchestration platform. So the requirements of the logging systems are probably slightly different to what you’ve been using so far.
Just as we did with logging, we also want to monitor on different levels. We want to see what’s happening within the container, the host operating system level, and the overall big picture. How is, for example, a certain application or a certain microservice that uses multiple containers doing, and when should you be reacting, for instance rolling out a new version or rolling back a version that didn’t work out?
25:16 Tooling (cont)

Container Orchestration. Once you have your application using containers you will need to coordinate them, manage them. Container orchestration helps you schedule your containers, it does service discovery, and helps you manage them. It lets you scale easily and keep your containers healthy.
Immutable infrastructure is a core piece of that. With the container life cycle we talked about, in the first step in development you would produce a Docker image, and that would be your immutable piece for the runtime – you’re not changing it, you’re just deploying it in production. And if you figure out a bug, you then create a new Docker image, which then again goes through CI/CD, QA and then into production.
Networking will also be important. It’s a pretty profound topic which becomes even more important with containers and microservices. NGINX provides quite a complete solution on this end.
One thing which is not obvious at first, but will be once you’re stepping into this direction of containers and microservices and putting everything into production: you will need a container image repository, or more generally speaking, an artifact repository to manage your images.
Secrets management also matters. You will always have things you need to keep secure, such as API keys. So, you want to be able to share that within the containers in the cluster in a safe and secure way.
Finally, there’s the question of handling stateful services. If you have any kind of data store, be it MySQL, a NoSQL database, Cassandra or whatever, you will need to think about how you will handle the failover for the stateful part?
Stateless is quite easy. Let’s say an NGINX container goes down on one host, the container orchestration system can relaunch it easily on a different node. However, if you have a MySQL instance, for example, on one host and that fails, and you need to restart it on a second, what about the data? The data needs to be captured and transferred as well.
There are a couple of pre‑existing solutions out there. For example, EMC Rexray, Flocker and others. So you don’t have to build your own stuff, but you do need to think about this issue. Are you using stateful services, databases, or any sort of discrete file systems? And if so, also check against your container orchestration system.
For example, Marathon, the open source project we are mainly driving, has very good support for stateful services already so you could rely on that. Otherwise, if your container orchestration platform does not support it, then you may need to handle that on your own.
28:18 p24e.io
If you want to dig deeper into immutable infrastructure, in case want to learn about all the options and so on, I’d like to point out p24e.io, which stands for Programmable Infrastructure, and there you will find listings about many of these technologies. This is a community site hosted on Github, so please, if you see anything missing there, send in a pull request or raise an issue. The site really benefits from your input.
28:56 O’Reilly Book

The second resource I wanted to point out, is the O’Reilly book. Just 50 or 60 pages, but it covers these two topics, Docker networking and service discovery, in greater detail. It’s free, so you can simply download it and learn more about those topics.
29:19 Resources
Floyd: I’m going to talk about a couple of resources, and then go into Q&A.
We’re covering decades of computing here, and we have a strong focus on things that are happening right now as we’re speaking, and that will be happening, really, in the next couple of years. What you’re seeing today is very much a view into the present and the near future of computing, really broadly, as well as for particular things around app delivery. So, it does all tie together, but it can be a bit overwhelming on initial exposure. If you want to dig deeper, there are some resources from both of our companies that can help, and then just tons more to read, learn and try on your own.
We have a number of blog resources for you. Refactoring a Monolith into Microservices is part of a seven‑part series on microservices from author and speaker Chris Richardson. The refactoring one is the last one, but actually I would start with it if you’re used to the monolithic world. It tells you how to shift from monolith to microservices a step at a time, and that really enlightens you about microservices and where you’re trying to get to as you make the change. You can read the whole seven parts and they will also link you to some of the other microservices resources on our site.
There’s a great how‑to post, Deploying NGINX and NGINX Plus with Docker, it’s very hands‑on. We have dockerfiles and commands there that you can easily copy and paste to get going with Docker if you’re still at that stage, or to modify for your particular application.
Make your Containers Production-Ready is an O’Reilly e‑book that starts to bring up some of the issues that we’re talking about here as well. It addresses roll up your sleeves, get things done, my‑server‑just‑died kind of problems and how to fix those in a microservices world.
For webinars a really valuable one is Building Applications with Microservices and Docker. NGINX is an important part of that mix. We followed that up with Ask Me Anything from NGINX & Docker. We talk about Bringing Kubernetes to the Edge within NGINX Plus, starting to get into some of these higher-level concerns. And then finally, we have a presentation on Scaling Microservices with NGINX, Docker and Mesos which takes you right to the brink of what we’re talking about today.
We also have a YouTube channel. We’ll be having a user conference in September in Austin, Texas, and that’s a great excuse to go to Austin where there’s lots of cool things going on. If you can’t make it or if you want to see previous presentations, the Youtube channel is where you’ll find presentations from our upcoming as well as our previous conferences.
So again, whether you’re trying to get stuff done today or whether you’re looking to think big and plan out the next couple of years of work at your shop, we have lots of valuable information.
35:00 Questions and Answers

1. I’ve used NGINX for a long time, but the rest of this is new to me. How do I get started?
Floyd: Well, part of what’s seductive about our software is that it fixes a lot of the problems with monolithic applications, quite simply and easily, just by dropping an NGINX server in front and letting the NGINX server handle communications with the user.
The cool part is that NGINX is also huge for helping you pivot to the microservices world. The microservices reference architecture which we’ve announced recently really shows exactly how that happens, but everybody who’s used NGINX will have some idea of what I’m talking about.
2. I’ve just started using Docker. When do I need Mesosphere DCOS? How does Kubernetes fit in?
Michael: Excellent question. Your first experience with Docker is going to be launching a container on the command line. Now, that’s fine for quickly testing something out. However, once you started growing and building a serious application there are a number of things that will pop up that you need to take care of.
You need to find an appropriate host in a cluster to launch your container. You need to know where each of these containers runs, what happens if one of the containers fails, who’s going to take care of restarting it in that case. You’ll also need to figure out how to manage the networking, how to deal with stateful services and so on and so forth.
A good way to think of container orchestration platforms is as if the collective experience of a lot of people who have been running containers at scale for many, many years, manifested itself in software. So they essentially have coded the knowledge that is necessary to run containers at scale, the best practices, to cover all of these issues; failover scenarios, service discovery, and all of that for you so that you can really focus on the business aspects. You want to be able to get a new feature out there as soon as possible. You don’t want to necessarily deal with the low‑level logistics involved.
This is similar to how, with a mobile app, you are focused on the features of your app and that’s why you have an operating system there that’s taking care of managing the resources, finding a CPU core to run one of your tasks, and so on and so forth. You’re not doing the operating system bit, you’re just using an operating system. So, that is exactly where DCOS comes in. DCOS, the data center operating system, is a distributed operating system that happens to use Apache Mesos as its kernel. Among other things, it allows you to have a container orchestration option which by default is Marathon, although we also support Kubernetes, Swarm, and more.
So it’s perfectly okay to start learning Docker by running a container manually on a command line. But as soon as you are heading towards a microservices architecture, you’ll have potentially many microservices that have to communicate and must be coordinated, and each of the microservices might be multiple containers, so you will end up with anywhere from a handful to 20, 30, 40, or 50 containers. So, you will need a container orchestration system.
By using an existing container orchestration system instead of re‑inventing the wheel, you benefit from the experience that many people who have been doing that in production for many years have thankfully shared in the Mesos project.
3. Is it optimal to run one container per microservice?
Michael: This is a tricky question. I’m a huge fan of keeping it simple, but I would also argue that there are certain limitations or requirements that might require you to run multiple containers.
For example, you might have NGINX and also a second process that pulls data from some cloud storage, and you want this to be part of serving your web application. To decide how to structure this you have to look into the tradeoffs.
What happens if you put that into two different containers? This is obviously more reusable because you can then reuse the container that pulls data from the cloud storage in another context. But there is a tradeoff between reusability and locality – so if your container orchestration platform doesn’t support the colocation features, that let you ensure that these two containers are actually running on the same host, then there might be an overhead so you might have delays there.
So there is, in my experience, no strict rules. You don’t necessarily have to have exactly one container for one microservice, but there might be situations where you do and then you need to look into the tradeoffs and figure out what is more important to you?
4. How is data handled in a containerized environment. For instance, data from ERP out to cloud containers, and also how do you load different data sources?
Floyd: First I want to mention that there is a great article in that seven‑part series that I mentioned, about this specific question: how to handle data in a microservices environment.
It’s a combination of pain and pleasure. The opportunity is that you get to manage data in each of your microservices. And the pain is that you have to manage data in each of your microservices.
Some things that are easy in a monolithic environment are harder to do in a microservices environment. Although there’s a lot of vulnerabilities and problems, but it’s easier to write that code in a monolithic environment. In a microservices environment, you really have to think from the very beginning about what each service is doing with data, what it needs with data, how resilient it will be in case of a crash; all of these things. It might be the hardest big problem in microservices, although there may be other close candidates.
So please read the article and start thinking hard about how you want to handle that. The ultimate result will be better than what we’re doing today, but there’s some hard work along the way.
You’ll also find yourself developing expertise in different ways to structure and handle data specific to different kinds of microservices. It’s challenging but it’s fun at the same time and I think you end up with a better result.
5. Using NGINX to route requests to microservices on DCOS or Mesos is great, but it assumes that each service handles its own monolithic responsibilities like authorization, rate limiting and so on.
Michael: So this is why DCOS as an operating system, is way more than just Apache Mesos. Mesos is the kernel. It really focuses on the resource management, the resource extraction, so that you, as a developer do not have to focus on allocating CPU shares, ram, port ranges and whatever on each of the machines. You can just use your cluster of machines like one big box with hundreds of cores and gigabytes or terabytes of RAM or whatever.
The magic with DCOS really happens in the framework, which is essentially two parts. It’s a scheduler, that’s why it’s also called two‑level scheduling. Mesos itself doesn’t make any scheduling decisions, but it’s really up to the framework scheduler such as Marathon to make these scheduling decisions.
With DCOS, we are adding many more things beyond Mesos and Marathon. Things like load balancing, options and storage, and so on and so forth, including amongst other things what you raised there. So, I really encourage you to check out DCOS, and rest assured that’s exactly what we are trying to address with our offering here.
6. Have you noticed huge degradation/overhead using Docker containers on an already virtualized host?
Floyd: Not really, and that’s surprising though, right? There’s a famous saying in computing: “There’s no problem in computing that can’t be solved with another level of indirection” but we all know that that costs performance, right?
Well, a couple of things help here. First of all NGINX is famous for steady resource usage, meaning not needing more memory usage. Using a stable amount of memory to handle great ranges of and increases in the number of processes that are going on at a time. Whether those are front end processes or processes in the background like microservices speaking to each other.
It’s almost like NGINX was designed for the challenge of microservices, but it wasn’t. Microservices weren’t around when it was first developed. It’s just that the underlying architectural approach in both NGINX’s design and microservices architecture is similar.
The other thing is that with a microservices architecture properly deployed and with containers, it’s much easier to scale out almost arbitrarily. You can just throw machines at the problem which now means you can just do cloud instances of the problem, and you can spin them up and pay for them as they’re needed and spin them down when they’re not needed.
So, yes, I’m sure there is measurable performance degradation and overhead, but containers have found a sweet spot in terms of having a lot of functionality, capability, and resiliency, with a reasonable performance overhead that you can overcome in deployment through appropriate use of resources, one of which is NGINX.
7. What is the recommendation for stateful applications? To have the data layer running in containers or outside of the containers? Which factors should be considered?
Floyd: It depends on what you’re specifically trying to do, and techniques for managing this are actually being developed live right now by people who are facing these problems.
From our talk and if you’re familiar with containers you know that we love a world where things are stateless as much as possible. However, that’s not always possible and then you get into these questions. Please read our microservices series which does address this questions, but it’s kind of hitting the gap between what we can talk about in a general way. It really depends on the specifics of your implementation.
8. Can you easily manage blue‑green deployments for continuous delivery with NGINX/Mesos?
Michael: The short answer is yes. There’s actually a blog post on our site that talks about blue‑green deployment with Marathon.
The main question there is really, what kind of deployment are you looking? If it’s like a spectrum of canary deployments, blue‑greens, you have a lot of options there. So yes, easily possible, directly supported by Marathon. Again remember, Mesos is the core of this distributed operating system, and Marathon is one of these frameworks we’re actually interacting with, but I wouldn’t limit it to blue‑green deployment.
So, you have a number of options and the blog post I just mentioned explains it in detail also exactly how to do it.
9.Since I’m currently working on an environment that relies on HAProxy, why should I switch to NGINX?
Floyd: It really depends on what you’re trying to do. We find if people take on more ambitious goals for their deployment or face stronger performance challenges, they often move to NGINX. But HAProxy’s a useful tool.
Talk to other people who are doing things similar to what you’re trying to do and ask what they’re solving, and that will help you know when you need to move to a different solution than something that’s working for you right now. There are a lot of things that we believe that NGINX can do and does well, that no other solution does, but you may not be into those yet. So, check out what you’re doing, talk to other people, and look for us.
Our conference is also a good place to come to ask questions like this of us, or even of colleagues in a similar situations, and this is true with all of these software questions.
There are a lot of ways to skin the cat right now, even including the fundamental choice of a monolithic or microservices architecture, and then just scores of questions coming after that, and it depends what you’re trying to do.
But you know, if you’re going big, if you’re trying to meet big needs, then look at what the people who are meeting those big needs are doing. That’s part of our point today. You know, a lot of people reading this post might not need all of what we’re talking about today. But it may be where you’re headed, and you’ll want to know what you’ll be able to do going forward.
10. Is there an app size or complexity level at which I need NGINX or Docker or DCOS?
Floyd: Regarding NGINX, if you’re running a WordPress blog, or you’ve moved up and your blog now has ecommerce on it on a single server, there’s a certain point at which you don’t necessarily need NGINX. But then what happens is, it’s Christmas time or it’s the holidays, or you have a sale, or it’s graduation day, or you release something really cool, or you get mentioned on a site that brings you a lot of users suddenly and the server crashes – and you bring it up and it crashes again, and then it stops crashing until the next time that big traffic happens.
That’s when people start moving to NGINX: just for pure performance readiness and for flexibility and scalability. NGINX will solve a problem like that on day one, and then it’ll allow you to run multiple application servers and also solve it for a long time into the future.
Then when your code starts getting more complex, as you start having problems like you have the wrong version of the wrong library on a certain service or part of your monolithic architecture. Then it’s high time to go to Docker and soon you’ll be saying, “Oh gosh, containers. I don’t know how I lived without them.” From there, if you have multiple containers to the point where manual coordination doesn’t cut it, you might need some more powerful tools.
Michael: When Docker introduces the concept of the immutable infrastructure building block, it’s really application-level dependency management. So you can ensure that whatever you’re seeing on your laptop, you will see the same thing in QA, and you will see the same thing in production.
But as we mentioned, this building block alone is not enough. Why? Because with microservices, we’re dealing with potentially many containers and different container image types to be more specific. So at the end of the day, you have to think about finding the tradeoff between getting into production and running and benefitting from the cool features and nice properties of immutable infrastructure at large, and container‑based, containerized workloads and the effort you need to put in there in order to manage everything in this new paradigm.
This post is the second of two, adapted from a webinar hosted by Floyd Smith and Michael Hausenblas of Mesosphere. The first part focuses on microservices. You can also watch a recording of the webinar.


