


This post is adapted from a webinar by Floyd Smith and Kunal Pariani.
Also see the related blog post, 3 Ways to Automate with NGINX and NGINX Plus.
Table of Contents
| Introduction | |
| 3:44 | How Long Does it Take You to Deploy New Code? |
| 5:17 | Deploying New App Versions |
| 5:46 | Modifying Open Source NGINX Configuration |
| 6:40 | NGINX Plus HTTP‑Based API (Configuration) |
| 8:06 | NGINX Plus HTTP‑Based API (Commands) |
| 10:49 | NGINX Plus Health Checks |
| 14:40 | Orchestration and Management |
| 15:25 | Orchestration and Management Tools |
| 16:46 | Service Discovery |
| 18:48 | Service Discovery Diagram |
| 19:35 | DNS for Service Discovery with NGINX |
| 20:36 | Limitations and Caveats |
| 21:33 | DNS SRV‑based Service Discovery with NGINX Plus |
| 23:18 | DNS SRV Example |
| 25:08 | Caveats |
| 25:56 | Demo |
| 34:37 | Automation Case Study |
| 37:15 | Summary |
| 38:46 | Resources |
Introduction
Floyd Smith: Imagine your software development and delivery process operating in a fully automated way like the factory that you see above. Imagine it was this easy and productive when you deliver your software.

I’m Floyd Smith. I’m the Technical Marketing Writer here at NGINX. Previously, I’ve worked at Apple, AltaVista, and Google, and I’ve written a number of books about different aspects of technology.
The main content of our presentation today has been developed by Kunal Pariani, a Technical Solutions Architect at NGINX. Kunal worked formerly at Zimbra, Motorola, and Cisco. He also interned at JPL, so he’s literally a rocket scientist.
3:44 How Long Does it Take You to Deploy New Code?

The key question for our presentation today is: How long would it take your organization to deploy a change that involves just one single line of code?
The funny thing is, if you’re a one‑man or three‑person show, the answer is five minutes because you can just go and change stuff. But with bigger websites and higher stakes, that’s around the time it starts taking longer, and longer and longer because any one line of code can impact other lines.
The penalties for your site or app going down because of a mistake becomes so huge that you have Q&A steps, staging steps – all sorts of things between you and deployment. Therefore, major organizations like Salesforce often just do a major software release every quarter and only handle emergencies in between. So, the answer to that question for Salesforce is 3 months.
Now the Salesforce approach could be seen as fleeing bugs, right? That’s not an ideal way to do things. Also, improvements are progressive. When you make a change that makes things better, it opens the door to other changes that make things better. If you’re limited in your ability to make the initial change, you can’t see or experience the opportunity to build on that initial improvement.
So, really, you want to be able to deploy constantly so you can improve constantly and that’s the purpose of this presentation – to help you do that.
Now that you understand the huge benefits you can see from continuous deployment, Kunal is going to show you how to do it.
5:17 Deploying New App Versions

Kunal Pariani: Let’s jump into the three methods of automating with NGINX and NGINX Plus.
So the first method is deploying new application versions or doing backend upgrades.
5:46 Modifying Open Source NGINX Configuration

Today, with open source NGINX, every time you want to deploy a new version of the software on a backend server, you have to SSH into the box running NGINX and manually edit the configuration file to add the new server to the upstream block.
Then you have to do a config check just to make sure the configuration looks good, which you can do using the nginx ‑t command. Then if you pass the configuration check, you do a reload using nginx ‑s reload.
The problem with this approach is that it’s not scalable at all. Imagine if you’re an organization that wants to do rolling upgrades very fast and on a regular basis. If you are deploying thousands of servers, this manual approach can easily turn into a nightmare.
6:40 NGINX Plus HTTP‑Based API (Configuration)

NGINX Plus offers two useful features in this respect for backend upgrades.
[Editor – The slide and text in this section have been updated to refer to the NGINX Plus API, which replaces and deprecates the separate dynamic configuration module originally discussed here.]
Let’s look at the first method, which is using the NGINX Plus API. This API essentially allows NGINX Plus to add or remove servers on the fly. You can use it to change server parameters or modify server weights without having to do a reload.
In this sample configuration, there is the upstream block named backend which has a server directive pointing to app‑server‑v1. This is the server we’re looking to upgrade.
Then there’s the virtual server block listening on port 8080 which has the location block. At the bottom of that block there is the api directive which enables use of the NGINX Plus API.
When using the NGINX Plus API, you want to restrict access to a limited set of clients. We are doing that here with the allow and deny directives. In this example, we are allowing just the clients in the same local area network (whose IP address falls in a specific subnet defined by the allow directive).
8:06 NGINX Plus HTTP‑Based API (Commands)

[Editor – The commands in the slide above are appropriate for the Upstream Config API module, which is replaced and deprecated by the NGINX Plus API introduced in NGINX Plus Release 13.
The text describing the commands on the original slide has been removed. The equivalent commands for the NGINX Plus API are as follows. For more information about the commands – and instructions for using the dashboard to configure upstream servers – see the NGINX Plus Admin Guide.]
-
Add new server.
# curl -X POST -d '{"server":"app-server-v2"}' http://localhost:8080/api/3/http/upstreams/backend/servers -
List servers. For readability, we pipe the output to the
jqutility to put each JSON element on its own line.# curl -s http://localhost:8080/api/3/http/upstreams/backend/servers | jq [ { "backup": false, "down": false, "fail_timeout": "10s", "id": 0, "max_conns": 0, "max_fails": 1, "route": "", "server": "app-server-v1", "slow_start": "0s", "weight": 1 }, { "backup": false, "down": false, "fail_timeout": "10s", "id": 1, "max_conns": 0, "max_fails": 1, "route": "", "server": "app-server-v2", "slow_start": "0s", "weight": 1 }, ] -
Put existing server in draining state
# curl -sX PATCH -d '{"drain":true}' localhost:8080/api/version/http/upstreams/backend/servers/0 -
Monitor the NGINX Plus dashboard until the active connections count for the server reaches zero
-
Remove the inactive server
# curl -sX DELETE localhost:8080/api/version/http/upstreams/backend/servers/0
10:49 NGINX Plus Health Checks

Another way of doing backend upgrades with NGINX Plus is using a feature called active health checks or application health checks.
This method has NGINX Plus periodically send HTTP health‑check requests to each of the backend servers. Then, based on the response code, NGINX Plus will dynamically load balance the traffic across only the healthy nodes.
Health checks can be as simple as looking for the presence of a file, or as advanced as looking for a specific string in the response header or the body.
With backend upgrades using health checks, one thing you could do is configure the health checks to check for the presence of a file, for example healthcheck.html. If the file is present on the backend server, it would return a 200 OK to NGINX Plus, which will mark that server as a healthy server. If the file is not present, it would mark it as a failed server and not send any traffic to it.
When you want to remove a server from a pool, you would just delete the monitored file, which would cause health checks to fail. You could then go ahead and upgrade the software version on this server or make any kind of other change.
Once it’s ready and you have the backend server with the latest software installed, you can then go ahead and re‑create the healthcheck.html file, which will cause the health checks to pass again. NGINX Plus will then mark the server as healthy and start sending traffic to it again.
A very nice option you have with health checks is to enable the slow‑start functionality that comes with NGINX Plus. This tell NGINX Plus to slowly ramp up the traffic over a configured period of time instead of throwing 100% of the traffic to the server right away.
This allows the backend server to warm up by populating caches, establishing database connections, etc. before it starts handling 100% of the traffic it was assigned to. This prevents the server from being overwhelmed.
Comparing these two methods for the backend upgrade, using the API and the active health checks, the recommended way is usually to use the API since it is a fully automatable and scriptable method.
The difference is that the changes that are done using the API are applied right away, whereas with the health checks, the actual time when the server gets removed depends upon the frequency of health checks. By default, NGINX Plus does health checks every five seconds. That means it might take up to five seconds for a server to be removed from the pool with the default settings.
The other significant difference is that with the API all the upgrades are managed within the NGINX Plus configuration instead of messing around with scripts or HTML files on the backend servers. So, this gives you complete control over the backend upgrades using NGINX Plus itself rather than messing with things on your backend servers.
The one drawback of the API method is you don’t get to use the slow‑start feature. That’s only available with the health checks.
14:40 Orchestration and Management

Now let’s look at the second way to automate, which is orchestration and management.
If you have a large enterprise that deploys thousands of NGINX servers, configuring each of them individually can easily become a nightmare.

This is where DevOps tools come to the rescue. DevOps tools allow you to manage and update the configuration from a central location, and the changes can then be pushed out automatically to all the nodes you are managing.
15:25 DevOps Tools for Orchestration and Management

Chef, Puppet, and Ansible are some of the more popular DevOps tools out there.
If you have done any kind of deployment automation in the past, you’ve probably used one of these tools. If you use Chef and NGINX, there are several Chef cookbooks available showing how to deploy NGINX or NGINX Plus, or even set up a high availability cluster with NGINX.
If you’re using Puppet and NGINX, there is a well‑maintained GitHub repo which manages NGINX, and also a blog post about deploying NGINX using Puppet.
Ansible is another popular IT automation tool which is gaining a lot of popularity. It’s now part of the Red Hat family. It’s popular mainly because it doesn’t require any kind of separate agent to be running on all the nodes which you’re looking to manage. It just uses the standard SSH protocol. Just like with the other DevOps tools, Ansible playbooks to deploy NGINX or NGINX Plus can be found on the NGINX blog.
16:46 Service Discovery

Now, let’s talk about the third way to automate: service discovery.
For any microservices‑based application, which is very dynamic by nature, keeping track of the endpoint addresses where the services are running is the most critical part.

You need to know where your services are running and where the NGINX Plus load balancer needs to route the traffic to. This is exactly what service discovery enables. It is essentially a process of discovering these endpoint addresses to which the requests can be routed.
Achieving automation when you are using NGINX with service discovery means as your backend application is being scaled up or scaled down, your NGINX Plus load balancer in front should get automatically reconfigured without any manual configuration, so that clients can have a good end‑user experience without any service disruption.
Some of the popular service discovery tools out there are Consul, etcd, and ZooKeeper. A lot of container orchestration platforms also used these service discovery tools. Kubernetes uses etcd as a service‑discovery backend, and Mesosphere uses ZooKeeper.
With service discovery there’s no configuration change required on the NGINX side, which is a huge benefit. As we’ll see in the later slides, NGINX just needs to query a centralized registry. This greatly reduces complexity, and it also automates the entire workflow.
18:48 Service Discovery Diagram
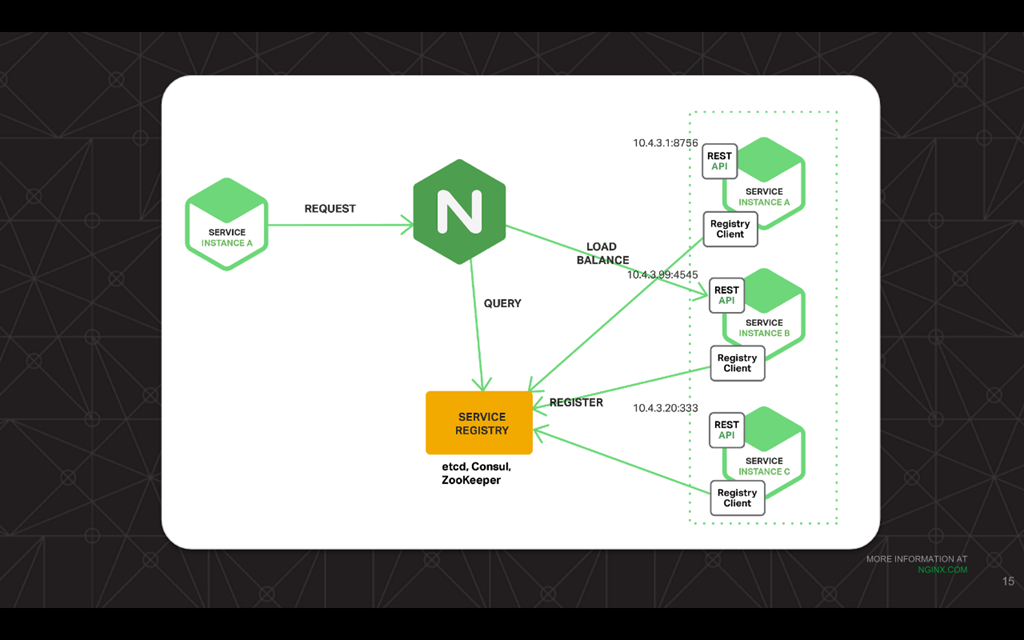
In this diagram, we see there are three instances of a server: instance A, B, and C, all using a REST API for external communication. There’s also a registry client which is responsible for doing all the service registration.
Every time a server comes up or goes down, the registry client updates its data in the service registry, which can be either Consul, etcd, or Zookeeper. Then, NGINX just queries this centralized registry and starts load balancing the traffic across all the instances which are present in the service registry.
19:35 DNS for Service Discovery with NGINX

Let’s see now how you can use DNS for service discovery with NGINX.
With open source NGINX, you have to use the DNS resolver library, which is completely asynchronous, implemented inside NGINX. You can specify the main servers there, which will essentially be the DNS interface of one of these service discovery tools.
NGINX can then request the DNS A records to get all the IP addresses associated with the domain name, and then simply start load balancing the traffic across these endpoints.
There’s also an option of honoring the TTL which is the time to live in the DNS response, or you could also have NGINX override it using the valid parameter, which we’ll discuss in later slides.
20:36 Limitations and Caveats

Some limitations and caveats with open source NGINX.
It does not have the support for SRV records, which is very crucial for any microservices application which has dynamically assigned ports. As microservices require multiple services running either on single or multiple hosts, but on different ports, you need the load balancer to have information about the ports, as well as other parameters which are part of the SRV records, like the priorities and the weight of the services, which can then be used for load balancing.
In addition, the port numbers have to be statically defined, which is a limitation when you are looking to deploy services in a microservices environment.
21:33 DNS SRV‑based Service Discovery with NGINX Plus

This is where DNS SRV‑based service discovery support comes into play. We added this feature in NGINX Plus R9 back in April. It allows us to query not only the IP address, but also the port number, the weight, and the priority of each of the backend services.
An SRV record is defined by a triplet, consisting of the service name, the protocol used, and the domain name. Whenever NGINX Plus queries the SRV record, it can use all the information retrieved from the record, such as priorities and weights, to do more intelligent load balancing.
Priorities can be used to have primary and backup servers. Weights can be used for weighted load‑balancing algorithms. These are both really critical for microservices‑based environments.
With DNS SRV‑based service discovery, you don’t have to make any manual configuration change within NGINX Plus. You just have to make sure that the service registry holds the latest current state of the services running in your environment.
This also helps achieve automation and significantly reduces complexity.
23:18 DNS SRV Example

This is an example NGINX Plus configuration showing the DNS SRV records in action.
As you can see, there’s the resolver directive pointing to the DNS server, which is the DNS interface of the service registry, and we set a valid timestamp of ten seconds.
The valid parameter overrides the TTL received in the DNS response and forces NGINX Plus to query the service registry every ten seconds, thereby keeping the state in sync with whatever it is load balancing, versus what is there in the service registry.
Also, you can see there’s the upstream group named backend with the server directive pointing to backends.example.com. The service parameter is the key here. It sets the service name and enables the resolving of the DNS SRV records, set to http in this case. The resolve parameter at the end monitors the changes in SRV records, and modifies the upstream configuration automatically, without having to reload NGINX Plus.
This functionality requires the upstream group to be in a shared memory zone, so that all NGINX local processes can share the upstream configuration and the running state. This is achieved here using the zone directive, which states the name of the empty zone which is backend and the size – 64k in this example.
And then there’s just a virtual server block below, with the location block, which is doing a proxy_pass to the backend.
25:08 Caveats

There are some caveats with this approach.
As you can probably guess, you want to make sure that your DNS server is highly available. If the DNS server is down, NGINX Plus will stop getting updates and it will keep the existing backend in the configuration and ignore the TTL value, unless you do a configuration reload or a restart. So we should make sure that we have multiple DNS resolvers with the resolver directive.
An alternative to using DNS is the dynamic reconfiguration API, which we discussed in method one. This is another way of achieving automation with the service discovery tools.
25:56 Demo

Editor – To view the demo of dynamic configuration of NGINX Plus, watch the video of the webinar on demand, starting at timepoint 26:00. You can find the demo code on GitHub.
34:37 Automation Case Study

Floyd: What are the benefits from achieving automation? The best testimony you’re ever going to get for this will be from your peers and colleagues who are using NGINX and NGINX Plus themselves. But we’ve done some case studies and are getting some really strong feedback about the benefits of what Kunal has just showed you.
Bluestem Brands runs about a dozen websites, and they had were having problems during the holidays for several years where their serves were getting overloading and kicking users off.
Their whole purpose in life is to be there during the holidays and get a lot of business. The servers weren’t supporting that so it’s a terrible problem for their business. The technical people who were trying to solve this issue adopted automation with NGINX Plus and have gotten really, really good results.
These are two quotes from the Principal Architect for Bluestem. “Our whole deployment pipeline for NGINX Plus is automated.” So, think of that figure at the start of the presentation with those machines ready to do the work automatically. That’s what the Bluestem team has now created.
He also says that it’s made it easy for their developers to adopt the canary release model. That’s the idea that you put a canary down in a coal mine to see if it’s healthy down there. So, they will release a change to a small number of users on a small part of their infrastructure, make sure it works well, check out what it looks like from the user end, and then gradually spread it to their entire userbase for each of their different businesses.
It’s just really gotten the delivery and deployment process out of the way for them. When they need to make a change, it’s quite easy and quite seamless, and they can steadily improve what they’re offering their customers.
37:15 Summary
To summarize, there are three points:

- The dynamic, on‑the‑fly reconfiguration API and health checks with NGINX Plus both enable automated deployments.
- Deploying NGINX and NGINX Plus with Ansible, Chef, or Puppet makes it easier to manage large production deployments. Different people have different reasons for choosing different tools, so we support all of them quite well.
- DNS
SRV‑based service discovery with NGINX Plus reduces complexity and allows for greater scalability with microservices‑based apps.


