


The following is adapted from a presentation given by Leandro Moreira and Juarez Bochi of Globo.com at nginx.conf 2015, held in San Francisco in September. This blog post is the second of two parts, and focuses on using NGINX to build microservices. The first part focuses on NGINX for streaming video delivery and caching. You can watch the video of the complete talk on YouTube.
Table of Contents
| Part 1: Streaming Media and Caching | |
| 19:02 | DVR |
| 20:24 | DVR Challenges – Failover |
| 21:06 | DVR Challenges – Storage |
| 22:11 | Redis as a Datastore |
| 23:20 | Brazil’s General Election |
| 24:12 | From Redis to Cassandra |
| 25:11 | Waiting Room |
| 27:40 | Waiting Room Architecture |
| 29:02 | FIFA 2014 World Cup Results |
| 31:00 | Recap and Next Steps |
| 31:58 | NGINX + Lua is Amazing |
| 33:17 | Open Source Software Development |
| 33:55 | Summary and the Future |
| 34:50 | Questions and Answers |
19:02 DVR
![For Digital Video Recording (DVR), the HLS playlist includes segments for the entire program (match, in the case of World Cup) using live video streaming [Globo.com presentation at nginx.conf2015]](https://www.nginx.com/wp-content/uploads/2016/04/Globo-conf2015-slide30_dvr-hls.png)
Juarez: By 2013, we were really happy with our infrastructure and the experience that we were delivering, so we started to think about what else we could do for the 2014 World Cup.
One of the features that we decided to develop is DVR. That stands for Digital Video Recording, and it gives the ability to pause the video, go back and, for instance, watch the goal again.
To do DVR with HLS, we just use a larger playlist. You have seen that the playlist is just a text file that lists the segments. For DVR, instead of just a couple of seconds of video, we list the segments for the entire match.
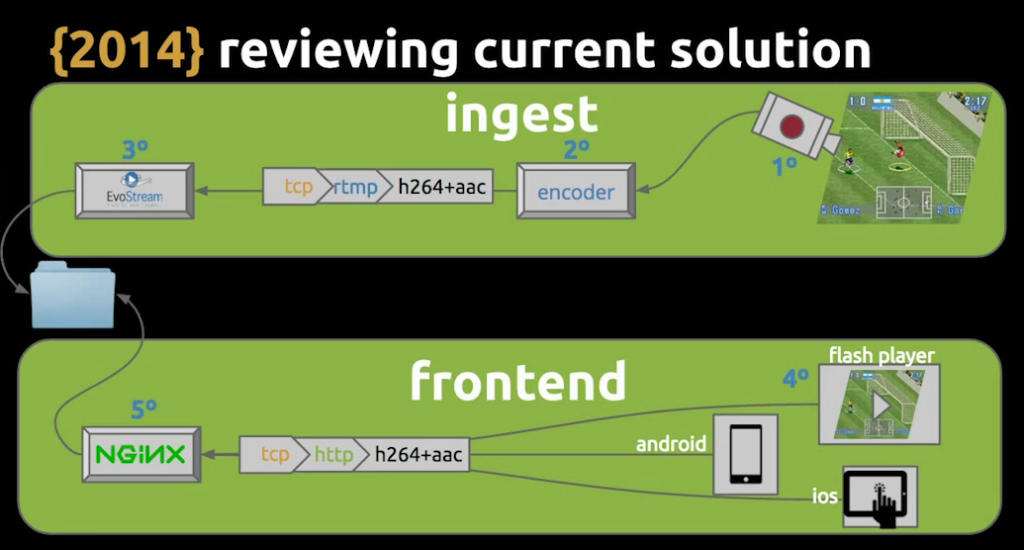
Just to review our solution, we can say that there were two main parts: the ingest and the frontend. The interface between them was the storage; these are the files that we were segmenting and making available for NGINX to deliver.
20:24 DVR Challenges – Failover
![A problem with EvoStream is that it does not provide failover during live video streaming [Globo.com presentation at nginx.conf2015]](https://www.nginx.com/wp-content/uploads/2016/04/Globo-conf2015-slide32_dvr-challenges-failover.png)
So, the storage was a problem because we didn’t have failover. If the stream stopped, then we had to start again. The server that we were using, EvoStream, would just erase the playlist and start a new one.
This is not a problem if you don’t have DVR, because the user will just see a small bump and reconnect again and the stream will continue normally, but if you lose the older playlist, then the user will not be able to seek back. So for DVR, we need to keep all the segments and the playlists.
21:06 DVR Challenges – Storage
![Redis was chosen for RAM storage of video (6 GB per match) during live video streaming [Globo.com presentation at nginx.conf2015]](https://www.nginx.com/wp-content/uploads/2016/04/Globo-conf2015-slide33_dvr-challenges-storage.png)
We also were a little bit worried about the storage, because for a single stream, a single match, we would split that in several bitrates; six in this case. Each bitrate is a different quality so, depending on the user bandwidth, they can watch one or another. It uses about 4.5 MB for 5 seconds of video, so for a two hour game, that would be around 6 GB.
We had two simultaneous games and other streams that our company Globo was broadcasting, so we needed about 40 GB. That’s not too much. We can put it all in RAM, so we decided to go ahead and use Redis as storage for video.
Leandro: We just replaced that older structure where we were saving the data to a folder and now we save the chunks and HLS files to Redis.
22:11 Redis as a Datastore
![A script written in Python moves newly generated segments to Redis for storage during live video streaming [Globo.com presentation at nginx.conf2015]](https://www.nginx.com/wp-content/uploads/2016/04/Globo-conf2015-slide34_redis-datastore.png)
Juarez: We built a daemon in Python, a simple script that would monitor the files and move the files as they were segmented to our Redis database. Then we used NGINX with the Lua module to fetch the list of streams from Redis and view the playlist dynamically. It took only a day or two to make that work.
Leandro: It was nice to use Python, but at the same time we found it difficult to scale. I don’t know if it’s because we didn’t have enough experience, but it was not easy for us to scale Python to multiple cores, so the daemon that monitors the file change and saves it to HLS gave us a lot of pain. If we did it again, we might choose another language, but at the time it was the simplest solution, and it’s still working today.
Juarez: Yes. This became a problem, especially when we had the general election in Brazil.
23:20 Brazil’s General Election
![Televising results from Brazil's general election involved 30 simultaneous streams, which challenged the Python/Redis solution during live video streaming [Globo.com presentation at nginx.conf2015]](https://www.nginx.com/wp-content/uploads/2016/04/Globo-conf2015-slide35_brazil-election.png)
So, later, when we were broadcasting Brazil’s general election, we had more than 30 simultaneous streams, one for each state. As Leandro said, the Python script became a bottleneck. And with Redis we also ran into issues since we couldn’t put all of this in memory, so we decided to move from Redis to Cassandra.
And just to clarify – for the World Cup, we were still using Redis. The election happened after, but we thought that was interesting to share here.
24:12 From Redis to Cassandra
![Because of Redis' limitations, Cassandra was adopted as the database for live video streaming [Globo.com presentation at nginx.conf2015]](https://www.nginx.com/wp-content/uploads/2016/04/Globo-conf2015-slide36_redis-cassandra.png)
We didn’t have to change this daemon much besides dealing with the scalability issues, but on the frontend we had to develop a new driver for Lua. We didn’t find anything at the time available for NGINX, so we had to write one ourselves. Since then more people have used this module, which has been great to see.
25:11 Waiting Room
Another thing that we had to build was a waiting room. We don’t use a CDN, and we have links with several internet providers in Brazil, and we have two data centers.
Sometimes, a user would be watching a video from an ISP that had a low bandwidth connection with us, and that might make the experience worse for everybody in that ISP. So, we decided to build a waiting room – if too many users were watching from the same link, we would put them on a queue.
![Globo.com does not use a CDN and needs to service several ISPs from two data centers for live video streaming [Globo.com presentation at nginx.conf2015]](https://www.nginx.com/wp-content/uploads/2016/04/Globo-conf2015-slide37_multihoming.png)
Leandro: We’ll get into the details about the waiting room in a later slide, but first, we need to talk about our multihoming solution. To make a single IP, the illusion of a single point, we chose to go with anycast.
![For anycast, BGP announces routes from the data centers during live video streaming [Globo.com presentation at nginx.conf2015]](https://www.nginx.com/wp-content/uploads/2016/04/Globo-conf2015-slide38_multihoming2.png)
Anycast works like this: You have the BGP protocol, which announces the routes, and then we have the ISPs. Since we are an Internet company, we are an autonomous system so we can exchange data, house data with the company’s ISP.
So we announce a route, and then our ISP will acknowledge that route. Now if you have a group of users near São Paulo. When they try to reach a given address, the ISP will wisely route their request to the nearest PoP.
![With BGP for anycast, ISPs know to route requests to the nearest point of presence during live video streaming [Globo.com presentation at nginx.conf2015]](https://www.nginx.com/wp-content/uploads/2016/04/Globo-conf2015-slide39_multihoming3.png)
Now we can get more into the waiting room.
![If the connection between and ISP and the Globo.com data center has low bandwidth, users have a poor experience of live video streaming [Globo.com presentation at nginx.conf2015]](https://www.nginx.com/wp-content/uploads/2016/04/Globo-conf2015-slide40_user-bandwidth.png)
Here we can see that ISP Y has a very low bandwidth connection to us so their users will have a poor experience while watching our broadcast. But they will not complain about their ISP, they will tweet about us. This is obviously not ideal, so we came up with the waiting room.
27:40 Waiting Room Architecture
![Drawing of the architecture for the "waiting room", which uses NGINX in a microservice that checks whether a link has enough capacity for an additional user during live video streaming [Globo.com presentation at nginx.conf2015]](https://www.nginx.com/wp-content/uploads/2016/04/Globo-conf2015-slide41_waiting-room-architecture.png)
Juarez: Here is the back‑of‑the‑napkin draft that we did. The video player asks if there is room for him, and we would check which route, which link they are coming in from. If that link has enough capacity, we let them through. If not, we put them in a queue.
To check which link they are coming from, we used a fork of Redis that has this new data structure called interval sets and put all the available routes in it. This made it really fast to do a lookup of an IP address to a link. And we also had to build a script that would listen to the BGP protocol and save that data in Redis. But with NGINX and Lua, it was easy to build a microservice that would check this database.
Leandro: And once again, we used NGINX on the frontend to deliver this service.
29:02 FIFA 2014 World Cup Results
![Germany beat Brazil 7-1 in the semifinals of World Cup 2014 [Globo.com presentation at nginx.conf2015]](https://www.nginx.com/wp-content/uploads/2016/04/Globo-conf2015-slide42_2014-world-cup-results.png)
I don’t know if you guys like soccer as much as we do, but we were not happy with that result, but that’s life.
![Graph showing peak bandwidth usage during broadcasts of matches during live video streaming [Globo.com presentation at nginx.conf2015]](https://www.nginx.com/wp-content/uploads/2016/04/Globo-conf2015-slide43_2014-world-cup-brazil-data.png)
I was very excited with how much bandwidth we could use. This graph shows roughly a few peak points when we had games online. This is not all of the games, but I was pretty happy with this result.

We had over 500,000 simultaneous users at one point and could have easily supported more. We expected to have around a million, but we suspect maybe there were less online viewers than expected because when Brazil was playing, people were able to watch the game from their house. So, some people preferred to watch on television especially for the games when we would expect to have the most viewers.
Another cool number is 640 Gbps in one game, which I think is pretty good.
![The DVR solution served about 1600 years' worth of viewing time in 40 million video sessions of live video streaming [Globo.com presentation at nginx.conf2015]](https://www.nginx.com/wp-content/uploads/2016/04/Globo-conf2015-slide45_2014-world-cup-brazil-data3.png)
Since we had the Sauron instrumentation, we could estimate using Graphite, that the sum of all the viewing time was roughly 1,600 years. And we also had over 40 million video views.
![The DVR solution delivered 20 GB per node using only 10% CPU during live video streaming [Globo.com presentation at nginx.conf2015]](https://www.nginx.com/wp-content/uploads/2016/04/Globo-conf2015-slide46_2014-world-cup-brazil-data4.png)
Here you can see our average bitrates, and one thing that I liked too was that we were able to deliver 20 GB per node using only 10% CPU.
31:00 Recap and Next Steps
Now that we’ve shown you our results, I think it’s time to do a recap and talk about the next steps we think are possible for our platform.
![he DVR solution used NGINX for live video streaming and caching with custom modules for geolocation and authorization, and as the basis for microservices [Globo.com presentation at nginx.conf2015]](https://www.nginx.com/wp-content/uploads/2016/04/Globo-conf2015-slide47_nginx-usage.png)
Juarez: We used NGINX a lot for video streaming. We used it for delivery, for caching. We developed modules for geolocation, authorization, authentication.
We also built a lot of our microservices around it. We used NGINX and Lua for playlist generation, for the waiting room. Another system we had which we didn’t have time to mention was the system that locks the number of concurrent sessions that a single user can have. But this was mostly for closed broadcasts, not for something like the World Cup.
31:58 NGINX + Lua is Amazing
![The NGINX Lua module and the unit testing framework called "busted" delivered great results for live video streaming [Globo.com presentation at nginx.conf2015]](https://www.nginx.com/wp-content/uploads/2016/04/Globo-conf2015-slide48_lua.png)
We really love NGINX and Lua. We are excited to try nginScript [Editor – now called the NGINX JavaScript module], but so far we are really happy with Lua. It was made in Brazil but –
Leandro: That’s not relevant!
Juarez: That’s not relevant, haha. I think we should look at the technical side. One model that we tried and we loved is busted. It works great for test‑driven development and made our lives easier.
Lua is a small language so it’s pretty easy to learn. And compared to the C model, we had a much better experience developing with NGINX and Lua. It was much faster to develop in Lua, and you still get a performance near C, so we were really happy with that.
Leandro: It was easier at least for us because we are not C experts.
33:17 Open Source Software Development
![Globo.com now strives to use all open source software for live video streaming [Globo.com presentation at nginx.conf2015]](https://www.nginx.com/wp-content/uploads/2016/04/Globo-conf2015-slide49_oss.png)
One of the cool things we did from that time, was we pushed ourselves to make almost all the software we did open source.
We created this video player called Clappr, which is in production now. We are using it and it’s receiving a lot of support from the community as well. We also made the m3u8 parser, which is the Python script to read the playlist from HLS.
33:55 Summary and the Future
![Between 2010 and 2014, Globo.com migrate from RTMP to HLS and created a DVR. They're now planning for the 2016 Olympics with live video streaming [Globo.com presentation at nginx.conf2015]](https://www.nginx.com/wp-content/uploads/2016/04/Globo-conf2015-slide50_summary.png)
Leandro: In summary, from 2010 to 2014, we transitioned from RTMP to HLS, and then we introduced this feature called DVR.
Now, we’re looking forward to the Olympic Games. We’re thinking of offering different kind of formats like DASH. We will probably change the ingest, the way the signal is ingested, and maybe support 4K.
Juarez: One thing that we know for sure is that we will keep using NGINX.
Leandro: Yes.
34:50 Questions and Answers
1. How many users were watching the match between you and Germany? Do you have any idea?
Juarez: I think after the third goal, none [laughs]. No, just kidding. The audience for the Brazil match was low because everybody was watching on the TV, not on the internet. But it was around 100,000 users.
2. The frontend NGINX servers – were those NGINX Plus machines or NGINX Open Source machines?
Leandro: Open source machines. We were using the community one.
Juarez: Yes. We were using the default open source NGINX solution, and we also had some hardware load balancers that we used to split the load across several instances of NGINX.
3. When you were talking about irqbalance and CPU affinity, how did you realize that there was a problem there?
Juarez: The first thing that we noticed was that we were losing packets; and the second thing that we noticed was that just one core of the machine was in use, and the process that was using the most CPU was the process that was handling the software interrupt for the network cards. So then, we first set the irqbalance to split across some cores, and we found we could have even better performance when we pinned each interrupt to a specific core.
Leandro: It all comes down to the fact that we saw that we have a node capable of 20 Gbps, and we were not reaching that 20 Gbps, so we thought maybe a problem with NGINX, or a problem with something else, because it’s just serving static files, which shouldn’t be hard. So we started researching, troubleshooting, and we were able to understand and apply those changes that he just talked about.
Juarez: Another interesting number is that with just two NGINX servers, we could handle 100,000 users. That was about what we could get with 50 Flash Media servers.
This blog post is the second of two parts. Part 1 explains how Globo.com uses NGINX for streaming video delivery and caching.


