

A national government agency in the Netherlands with a diverse array of stakeholders and users wanted to move its workflows from paper‑based processes to a modern digital infrastructure. This would enable the agency to move more quickly and simplify the lives of its users and employees.
The challenge? The agency allowed each participating locality to craft somewhat unique processes and requirements. Initially, the agency had mounted a large effort to create an all‑inclusive monolithic application with numerous customizations. The first effort failed under the weight of hyper‑customization – “death by a thousand requirements”. HCS Company, a Dutch IT consultancy specializing in open source and Red Hat® technologies, was tapped to try new ways to digitize the agency’s processes with a different approach.
Rebuilding Simple: Composable Micro‑Front Ends, Containers, and Microservices
The DevOps team at the agency worked on the project with Benoit Schipper, Lead Site Reliability Engineer (SRE) at HCS. Together they began by taking a deeper look at the problem they were solving. Users ranging from government officials to lawyers, accountants, and regular citizens need to log into the agency app, check the status of a project or process, and upload a PDF. Benoit and the team decided to build a simple foundation as the starting point for the solution. Explains Benoit, “We looked at that and said, ‘Let’s make something very generic, and for any special requests we can build up from that generic foundation’”. The DevOps team also wanted to future‑proof the foundation, ensuring scalability both within the existing infrastructure and for additional locations and applications that might become needed in future.
Benoit and the team white‑boarded out that future and arrived at a novel architecture of very small (micro) front ends that can be composed into different applications mapped to small, distinct services (microservices) in the back end. “We went for microservices because with that architecture, you are ready to go to the cloud and to scale when it goes very big,” says Benoit. “We separated the puzzle into smaller pieces we could stick together.”
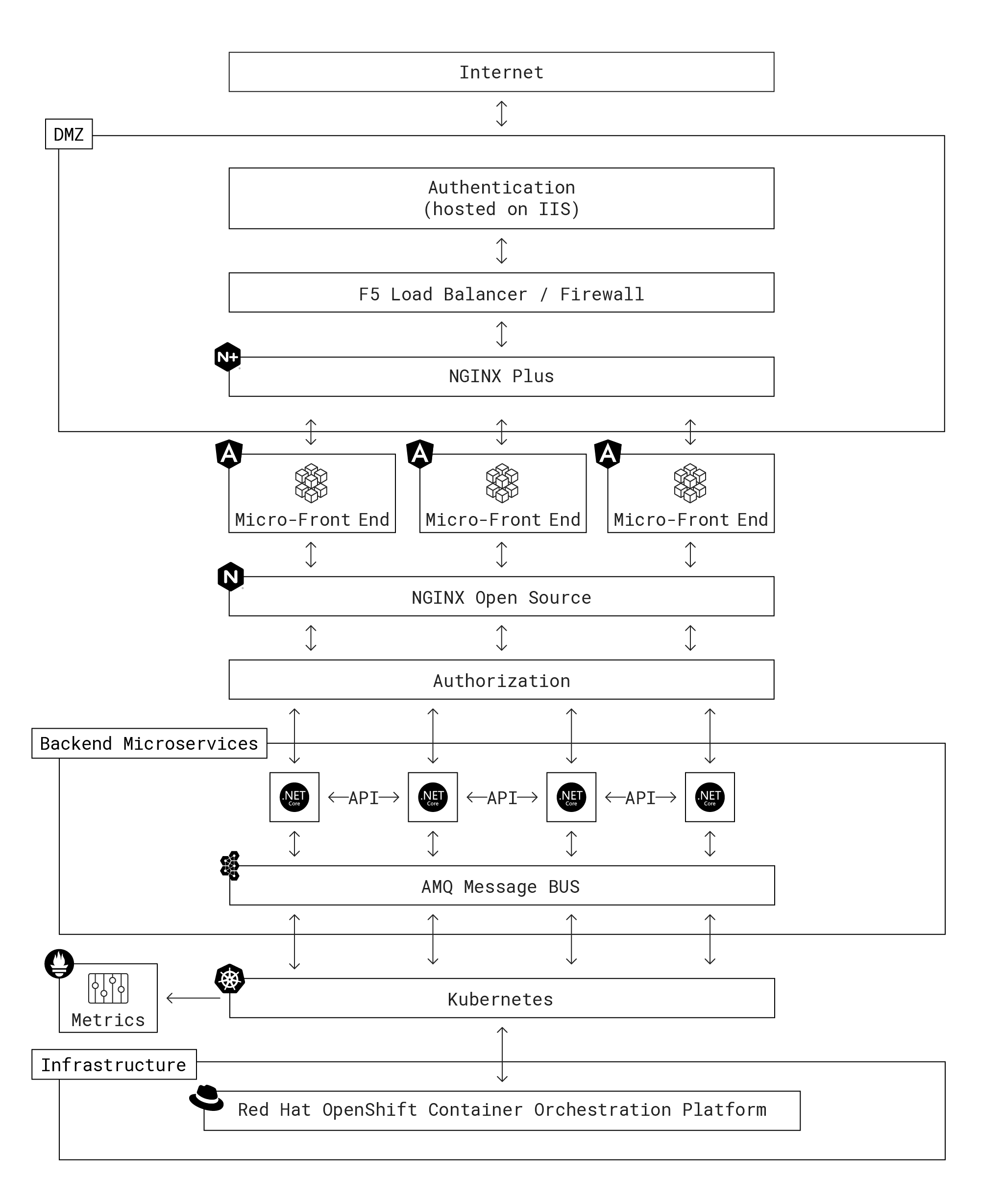
The first decision around implementation was to move from Microsoft Windows servers in a dedicated environment to a container‑based environment in the cloud which is more suitable for composable and flexible microservices. The team chose Red Hat OpenShift® as the container platform.
There were two strong factors in OpenShift’s favor. First, RedHat’s long experience working with governments made it easy to get government approval for the design. Second, OpenShift includes many tools and applications designed for easy construction and maintenance of microservices and microservices architectures, including:
- Red Hat Ceph® Storage – A blob storage service accessible via an S3‑compliant API
- Red Hat AMQ Broker – A message bus service for managing workload and application state and queueing workers
- Built‑in, certified support for Kubernetes – Important for further future‑proofing if HCS and the agency determine Kubernetes is the right tool for container orchestration
From Windows to Linux, .Net Core, and NGINX Open Source
Moving to containers meant replacing the agency’s previous .Net back end, which ran on Windows servers. Fortunately, it was an easy transition to .Net Core, a version of .Net optimized for containers. An added benefit is that the agency’s developers can continue coding in the Windows application languages and frameworks they’re familiar with.
The DevOps team built a core set of REST APIs for accessing the .Net Core backend services. The APIs are the glue holding together the application functionality and logic and the micro‑front ends. For the front‑end environment, the team chose AngularJS due to its wide acceptance among government organizations as a robust, reliable JavaScript framework with a strong community.
To create a cohesive routing layer for traffic and API calls back and forth between the front and back ends, the team explored various options before settling on NGINX Open Source due to its versatility. The pages on the agency website are built on the fly as micro‑front ends by pulling in content elements and using the same CSS logic to “skin” multiple back‑end services. To the user, it looks like everything is happening within the same application, “but actually we are using smart proxying and rewrites with NGINX. To fill the screen with the appropriate information for the front end, we do backend API calls via NGINX,” explains Benoit.
To expose the application to the public Internet, Benoit deployed an F5 NGINX Plus instance as a web server and reverse proxy on a virtual machine running in the agency’s DMZ. He explains why NGINX Plus is the right fit: “We needed TLS 1.3 and wanted to move quickly. It was affordable compared to dedicated appliances and we could easily add licenses”.
Benoit stresses that for the agency, “NGINX works as a web server, a proxy, and a basic API gateway for our application tier. It’s really a Swiss Army Knife™ that can do almost anything. That’s why we use it.” For example, to retrieve an uploaded PDF, users select the PDF they need from uploaded documents on their account and the PDF‑delivery application sends a request to the back‑end PDF retrieval service attached to the Ceph object store. Ceph returns the unique URL of the PDF’s location in the object store, which the user clicks on for either viewing or downloading.
Because the application is mission‑critical, the team engineered an active‑active high availability architecture with all applications running in at least two clusters. This provides redundancy for all services, micro‑front ends, and APIs, ensuring they continue to work in the event of an outage in one of the clusters.
To improve performance and enable a control plane for the compound applications spanning multiple services, the team uses the AMQ Broker message bus to configure topics and queues for services. “So if anything is possible to be run in the background, we do it in the background,” says Benoit. “If a message comes in and some method data needs to be adjusted, we have listeners that can process something or can find the workers to run the process.” To ensure a consistent state for users across the clusters, the team retained its existing highly available Microsoft SQL Server database infrastructure to maintain pod state and enable session persistence.
Designing for Observability, Scalability, and Flexibility
For observability, Benoit recommended Grafana as the cloud‑native dashboard. To obtain NGINX metrics, the DevOps team leverages the NGINX Prometheus Exporter in a sidecar paired to each pod. Exporter scrapes Layer 4 metrics from the NGINX Open Source Stub Status module and NGINX Plus API, matches each one to a string, creates a key‑value pair, and pushes the pair into Prometheus. From there the pair is published to a separate Grafana instance that is exposed only to developers and DevOps teams. “It’s amazing. I can build dashboards and collect metrics in a single place across all my NGINX Open Source and NGINX Plus instances. The DevOps team is in control. They can see what’s running and get alerts for problems,” says Benoit.
The team also uses the metrics for performance management of the application. Prometheus generates alerts for exceptions and unhandled connections in the applications, which signal that there aren’t enough workers running. Benoit has linked the metrics to the autoscaling feature in OpenShift. He explains, “I’ve configured the NGINX setup for a certain number of workers and calculated the required RAM and CPU. If things get too busy against that baseline, OpenShift automatically scales up and sends me an alert.”
When a penetration test indicated that the applications did not use a strong content security policy (CSP), the team was able to configure NGINX Open Source and NGINX Plus with policies for in‑line enforcement of CSP. They also set up custom configuration to pull JSON logging information from the container platform and send it to the Splunk logging platform for historical analysis and record keeping.
Improving the Developer Experience
For front‑end developers using Google Analytics and Lighthouse, HCS made it possible to include Lighthouse checks in the agency’s pipeline, coded into NGINX configs. “We quickly saw we could make significant performance gains by changing to the GZIP compression library,” says Benoit, and the result is a 60% improvement in application latency.
Further, with the new architecture developers are now directly in contact with end users because they have such detailed visibility into real‑time behavior. “The feedback loop is way faster, and if something happens and needs to be changed, we can get it into production in just a day. That’s very fast for governments, where changes used to take months or even years,” says Benoit. “For our developers, this is like night and day.”
The Tech Stack
- Back end – .Net Core
- Front end – AngularJS
- Networking (web server, reverse proxy, API gateway, Ingress controller, global load balancer) – NGINX Open Source, NGINX Plus, F5 BIG‑IP, HAProxy (on OpenShift)
- Database – Microsoft SQL Server, Red Hat Ceph Storage, InfluxDB for Lighthouse data
- CI/CD – Azure DevOps
- Infrastructure – Red Hat OpenShift, Linux containers
- Messaging – Red Hat AMQ Broker (Active MQ open source)
- Observability and Metrics – Grafana, Prometheus
- Logging – Splunk
Get Started
Want to duplicate the great results from this project by building your tech stack on NGINX Plus? Start your 30-day free trial today or contact us to discuss your use cases.


