


When we introduced the NGINX Modern Apps Reference Architecture (MARA) project last fall at Sprint 2.0, we emphasized our intent that it not be a “toy” like some architectures, but rather a solution that’s “solid, tested, and ready to deploy in live production applications running in Kubernetes environments”. For such a project, observability tooling is an absolute requirement. All the members of the MARA team have experienced firsthand how lack of insight into status and performance makes application development and delivery an exercise in frustration. We instantly reached consensus that the MARA has to include instrumentation for debugging and tracing in a production environment.
Another guiding principle of the MARA is a preference for open source solutions. In this post, we describe how our search for a multifunctional, open source observability tool led us to OpenTelemetry, and then detail the trade‑offs, design decisions, techniques, and technologies we used to integrate OpenTelemetry with a microservices application built with Python, Java, and NGINX.
We hope hearing about our experiences helps you avoid potential pitfalls and accelerate your own adoption of OpenTelemetry. Please note that post is a time‑sensitive progress report – we anticipate that the technologies we discuss will mature within a year. Moreover, though we point out current shortcomings in some projects, we are immensely grateful for all the open source work being done and excited to watch it progress.
Our Application
As the application to integrate with an observability solution, we chose the Bank of Sirius, our fork of the Bank of Anthos sample app from Google. It’s a web app with a microservices architecture which can be deployed via infrastructure as code. There are numerous ways this application can be improved in terms of performance and reliability, but it’s mature enough to be reasonably considered a brownfield application. As such, we believe it is a good example for showing how to integrate OpenTelemetry into an application, because in theory distributed tracing yields valuable insights into the shortcomings of an application architecture.
As shown in the diagram, the services that back the application are relatively straightforward.
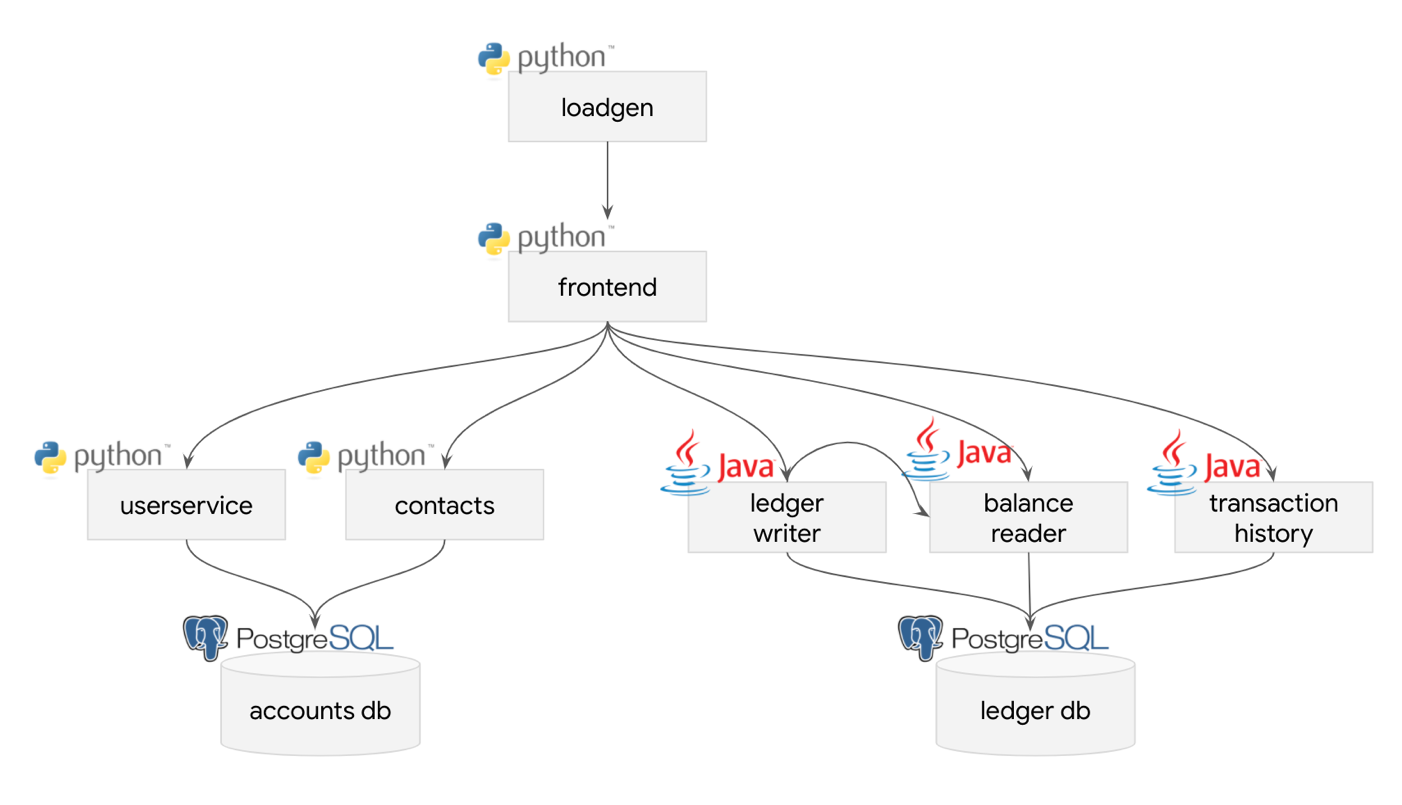
How We Chose OpenTelemetry
Our path to selecting OpenTelemetry was quite twisty and had several stages.
Creating a Feature Wishlist
Before evaluating the available open source observability tools themselves, we identified which aspects of observability we care about. Based on our past experiences, we came up with the following list.
- Logging – As we are using the term, this means generation of classic newline‑delimited sets of messages from applications; the Bank of Sirius app structures its logs in Bunyan format
- Distributed tracing – Timings and metadata for each component within the entire application, like what application performance management (APM) vendors provide
- Metrics – Measurements captured over a period of time and graphed as time‑series data
- Exception/error aggregation and notification – An aggregated collection of the most common exceptions and errors, which must be searchable so that we can determine which application errors are most common
- Health checks – Periodic probes sent to services to determine whether they are functioning correctly within the application
- Runtime state introspection – A set of APIs visible only to administrators that return information about the runtime state of the application
- Heap/core dumps – Comprehensive snapshots of a service’s runtime state; the important factor for our purposes is how easy it is to get these dumps on demand or when a service crashes
Comparing Tool Features Against the Wishlist
Of course, we did not expect a single open source tool or approach to include all these features, but at least it gave us an aspirational basis on which to compare the available tools. We consulted each tool’s documentation to find out which of the seven features in our wishlist it supports. The table summarizes our findings.
| Technology | Logging | Distributed Tracing | Metrics | Error Aggregation | Health Checks | Runtime Introspection | Heap/Core Dumps |
|---|---|---|---|---|---|---|---|
| ELK + Elastic APM | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ |
| Grafana | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ |
| Graylog | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
| Jaeger | ❌ | ✅ | ❌ | ✅ | ❌ | ❌ | ❌ |
| OpenCensus | ❌ | ❌ | ✅ | ❌ | ❌ | ❌ | ❌ |
| OpenTelemetry | Beta | ✅ | ✅ | ✅ | ✅ * | ❌ | ❌ |
| Prometheus | ❌ | ❌ | ✅ | ❌ | ❌ | ❌ | ❌ |
| StatsD | ❌ | ❌ | ✅ | ❌ | ❌ | ❌ | ❌ |
| Zipkin | ❌ | ✅ | ❌ | ✅ | ❌ | ❌ | ❌ |
* As an extension
Building this table was a rude awakening. The various tools differ so much in their capabilities and intended purposes that we couldn’t consider them all members of the same category – it was like comparing apples to toasters!
As an example, ELK (Elasticsearch-Logstash-Kibana, plus Filebeat) and Zipkin do such fundamentally different things that trying to compare them is more confusing than anything. Unfortunately, “mission creep” just muddies the waters further – doubtless in response to user requests, features have been added that are secondary to the tool’s main purpose and create overlap with other tools. On the surface, ELK does log storage and visualization whereas Zipkin does distributed tracing. But when you dive just a bit deeper into the Elastic product portfolio, you quickly come across Elastic APM, which supports distributed tracing and even has Jaeger compatibility.
Beyond the issue of mission creep, many of the tools can be integrated with each other, resulting in different combinations of collectors, aggregators, dashboards, and so on. Some of the technologies are compatible with each other and some are not.
Doing a Qualitative Investigation
As such, this comparison table didn’t give us an accurate enough picture to base our choice on. We needed to do a qualitative investigation into each project’s goals, guiding principles, and possible future direction, reasoning that the more similar a project’s values are to ours, the more likely we’ll remain compatible over time. Visiting the project pages, we immediately noticed this on the OpenCensus page.
OpenCensus and OpenTracing have merged to form OpenTelemetry, which serves as the next major version of OpenCensus and OpenTracing. OpenTelemetry will offer backwards compatibility with existing OpenCensus integrations, and we will continue to make security patches to existing OpenCensus libraries for two years.
That was a key data point as far as we were concerned. We knew we couldn’t guarantee our choice would be future‑proof, but we wanted to know at least that it will have solid community backing going forward. With this information, we could scratch OpenCensus off our list of candidates. It was probably not a good idea to use Jaeger either, because it’s the reference implementation for the now officially deprecated OpenTracing project – the bulk of new contributions is going to land in OpenTelemetry.
Then we read up on the OpenTelemetry Collector.
The OpenTelemetry Collector offers a vendor‑agnostic implementation on how to receive, process and export telemetry data. In addition, it removes the need to run, operate and maintain multiple agents/collectors in order to support open‑source telemetry data formats (e.g., Jaeger, Prometheus, etc.) sending to multiple open‑source or commercial back‑ends.
The OpenTelemetry Collector acts as an aggregator that allows us to mix and match different observability collection and instrumentation methods with different backends. Basically, our application can collect traces with Zipkin and metrics from Prometheus, which we can then send to a configurable backend and visualize with Grafana. Several other permutations of this design are possible, so we can try out different approaches to see which technologies are a good fit for our use case.
Integrating OpenTelemetry as the Way Forward
Basically, we got sold on the OpenTelemetry Collector because in theory it allows us to switch between observability technologies. Despite the relative immaturity of the project, we decided to boldly dive in and use OpenTelemetry with only open source integrations because the only way to understand the landscape is to use the technologies.
There are, however, some pieces missing from OpenTelemetry Collector, so we have to rely on other technologies for those features. The following sections summarize our choices and the reasoning behind them.
- Implementing Logging
- Implementing Distributed Tracing
- Implementing Metrics Collection
- Implementing Error Aggregation
- Implementing Health Checks and Runtime Introspection
- Implementing Heap and Core Dumps
Implementing Logging
Logging is a deceptively simple part of observability that rapidly leads to complicated decisions. It’s simple because you merely harvest the log output from your containers, but complicated because you then need to decide where to store the data, how to transport it to that store, how to index it to make it useful, and how long to keep it. To be useful, log files need to be easily searchable on enough different criteria to meet the needs of various searchers.
We looked at logging support with the OpenTelemetry Collector and at the time of writing it is very beta. We decided to use ELK for logging in the short term while continuing to investigate other options.
Absent any compelling reason not to, we defaulted to using the Elasticsearch tooling, enabling us to split the deployment into ingest, coordinating, master, and data nodes. For easier deployment, we used a Bitnami chart. To transport data, we deployed Filebeat as part of a Kubernetes DaemonSet. Search functionality was added by deploying Kibana and taking advantage of the pre‑loaded indexes, searches, visualizations, and dashboards.
Fairly quickly it became apparent that although this solution worked, the default configuration was quite resource hungry which made it hard to run in a smaller resource footprint such as K3S or Microk8s. Adding the ability to tune the number of replicas for each component addressed this issue, but did lead to some failures that were potentially due to resource exhaustion or excessive volumes of data.
Far from being disappointed by this, we are viewing it as an opportunity to benchmark our logging system with differing configurations, as well as to investigate other options such as Grafana Loki and Graylog. We may well discover that lighter‑weight logging solutions don’t provide the full set of features that some users need and can get from more resource‑hungry tools. Given the modular nature of MARA, we will likely build additional modules for these options to give users more choice.
Implementing Distributed Tracing
Beyond determining which tool provides the tracing functionality we want, we needed to consider how to implement the solution and which technologies need to be integrated with it.
First, we wanted to make sure that any instrumentation did not negatively affect quality of service for the application itself. All of us had worked with systems where performance dipped predictably once an hour as logs were being exported, and we had no desire to relive that experience. The architecture of the OpenTelemetry Collector was compelling in this respect because you can run one instance per host. Each collector receives data from clients and agents in all the different applications that are running on the host (containerized or otherwise). The collector aggregates and potentially compresses the data before sending it to a storage backend, which sounded ideal.
Next, we evaluated support for OpenTelemetry in the different programming languages and frameworks that we are using in the application. Here, things became a bit trickier. Despite using only the two programming languages and associated frameworks shown in the table, the level of complexity was surprisingly high.
| Language | Framework | Number of Services |
|---|---|---|
| Java | Spring Boot | 3 |
| Python | Flask | 3 |
To add language‑level tracing, we first tried OpenTelemetry’s automatic instrumentation agents, but found their output to be cluttered and confusing. We’re sure this will improve as the automatic instrumentation libraries mature, but for the time being we ruled out the OpenTelemetry agents and decided to weave tracing into our code.
Before jumping into a direct implementation of tracing in the code, we first wired the OpenTelemetry Collector to output all trace data to a locally running Jaeger instance where we could see the output more easily. This was quite useful, as we could play with the visual presentation of tracing data as we figured out how to fully integrate OpenTelemetry. For example, if we found that an HTTP client library did not include tracing data when making calls to a dependent service, we put the issue on our fix list right away. Jaeger presents a nice view of all the different spans within a single trace:

Distributed Tracing for Python
Adding trace to our Python code was relatively straightforward. We added two Python source files that are referenced by all our services, and updated the respective requirements.txt files to include the relevant opentelemetry-instrumentation-* dependencies. This meant we could use the same tracing configuration for all the Python services, as well as include the trace ID of each request in log messages and embed the trace ID in requests to dependent services.
Distributed Tracing for Java
Next, we turned our attention to the Java services. Using OpenTelemetry Java libraries directly in a greenfield project is relatively straightforward – all you need to do is to import the necessary libraries and use the tracing API directly. However, if you are using Spring as we are, you have additional decisions to make.
Spring already has a distributed tracing API, Spring Cloud Sleuth. It provides a façade over the underlying distributed tracing implementation that does the following, as described in the documentation:
- Adds trace and span ids to the Slf4J MDC, so you can extract all the logs from a given trace or span in a log aggregator.
- Instruments common ingress and egress points from Spring applications (servlet filter, rest template, scheduled actions, message channels, feign client).
- If
spring-cloud-sleuth-zipkinis available, … [generates and reports] Zipkin‑compatible traces via HTTP. By default, it sends them to a Zipkin collector service on localhost (port 9411). Configure the location of the service usingspring.zipkin.baseUrl.
The API also enables us to add traces to @Scheduled‑annotated tasks.
In other words, using Spring Cloud Sleuth alone we are getting traces at the level of the HTTP service endpoints out of the box, which is a nice benefit. As our project already uses Spring, we decided to keep everything within that framework and utilize the features provided. However, we discovered some issues as we were wiring everything together with Maven:
- The Spring Cloud Sleuth Autoconfigure module is still on a milestone release.
- The Spring Cloud Sleuth Autoconfigure module depends on an outdated alpha version of
opentelemetry-instrumentation-api. There is currently no recent non-alpha 1.x release of this library. - The project must pull the parent project object model (POM)
spring-cloud-buildfrom the Spring Snapshot repositories because of the way Spring Cloud Sleuth codes its dependency references for milestone releases.
This made our Maven project definition a bit more complicated, because we had to have Maven pull from the Spring repositories as well as Maven Central, a clear indication of how early‑stage the OpenTelemetry support in Spring Cloud was. Nonetheless, we continued forward and created a common telemetry module to configure distributed tracing using Spring Cloud Sleuth and OpenTelemetry, complete with various telemetry‑related helper functions and extensions.
In the common telemetry module, we extend the tracing functionality provided by Spring Cloud Sleuth and OpenTelemetry libraries by providing:
- Spring‑enabled
Autoconfigurationclasses that set up tracing and extended functionality for the project, and load additional trace resource attributes. - NoOp interface implementations, so we can disable tracing at startup by injecting NoOp instances into all Spring Cloud Sleuth interfaces.
- A trace naming interceptor for normalizing trace names.
- An error handler that outputs errors via slf4j and Spring Cloud Sleuth tracing.
- An enhanced implementation of tracing attributes that encodes additional information into each emitted trace, including service version, service instance ID, machine ID, pod name, container ID, container name, and namespace name.
- A tracing statement inspector that injects trace IDs into comments that precede SQL statements issued by Hibernate. Apparently, this can now be done with SQLCommenter, but we haven’t migrated to it yet.
Additionally, we implemented a Spring‑compatible HTTP client that is backed by the Apache HTTP Client, because we wanted more metrics and customizability when making HTTP calls between services. In this implementation, the trace and span identifiers are passed in as headers when dependent services are called, allowing them to be included in the tracing output. Moreover, this implementation provides HTTP connection pool metrics that are aggregated by OpenTelemetry.
All in all, it was a slog getting tracing wired with Spring Cloud Sleuth and OpenTelemetry, but we believe it was worth it. We hope that this project and this post help light the way for others who want to go down this path.
Distributed Tracing for NGINX
To get traces that connect all of the services for the entire life cycle of a request, we needed to integrate OpenTelemetry into NGINX. We used the OpenTelemetry NGINX module (still in beta) for this purpose. Anticipating that it might be potentially difficult to get working binaries of the module that work with all versions of NGINX, we created a GitHub repository of container images that incorporate unsupported NGINX modules. We run nightly builds and distribute the module binary via Docker images that are easy to import from.
We haven’t yet integrated this process into the build process for NGINX Ingress Controller in the MARA project, but we plan to do that soon.
Implementing Metrics Collection
After completing the OpenTelemetry integration of tracing, next we focused on metrics. There were no existing metrics for our Python‑based applications, and we decided to put off adding them for now. For the Java applications, the original Bank of Anthos source code, which uses Micrometer in conjunction with Google Cloud’s Stackdriver, supports metrics. However, we removed that code from Bank of Sirius after forking Bank of Anthos, because it did not allow us to configure a metrics backend. Nonetheless, the fact that metric hooks were already present spoke to the need for proper metrics integration.
To come up with a configurable and pragmatic solution, we first looked at metric support within the OpenTelemetry Java libraries and Micrometer. From a search for comparisons between the technologies, a number of results enumerated the shortcomings of OpenTelemetry used as a metrics API in the JVM even though OpenTelemetry metrics is still in alpha at the time of writing. Micrometer is a mature metrics façade layer for the JVM, akin to slf4j in providing a common API wrapper that fronts a configurable metrics implementation rather than a metrics implementation of its own. Interestingly, it is the default metrics API for Spring.
At this point, we were weighing the following facts:
- The OpenTelemetry Collector can consume metrics from just about any source, including Prometheus, StatsD, and the native OpenTelemetry Protocol (OTLP)
- Micrometer also supports a large number of metrics backends, including Prometheus and StatsD
- The OpenTelemetry Metrics SDK for the JVM supports sending metrics via OTLP
After a few experiments, we decided that the most pragmatic approach was to use the Micrometer façade with a Prometheus backing implementation and to configure the OpenTelemetry Collector to use the Prometheus API to pull metrics from the application. We knew from numerous articles that missing metrics types in OpenTelemetry can cause problems, but our use cases don’t need those types, so the compromise was acceptable.
We discovered one interesting thing about the OpenTelemetry Collector: even though we had configured it to receive traces via OTLP and metrics via the Prometheus API, it can still be configured to send both types of data to an external data receiver using OTLP or any other supported protocol. This allowed us to easily try our application with LightStep.
Overall, coding metrics in Java was rather simple because we wrote them to conform with the Micrometer API which has numerous examples and tutorials available. Probably the most difficult thing for both metrics and tracing was getting the Maven dependency graph in the pom.xml file for telemetry-common just right.
Implementing Error Aggregation
The OpenTelemetry project doesn’t include error aggregation in its mission per se, and it doesn’t provide as elegant an implementation of error tagging as solutions like Sentry or Honeybadger.io. Nonetheless, we decided to use OpenTelemetry for error aggregation in the short term rather than add another tool. With a tool like Jaeger, we can search for error=true to find all traces with an error condition. This at least gives us a sense of what is commonly going wrong. In the future, we may look at adding Sentry integration.
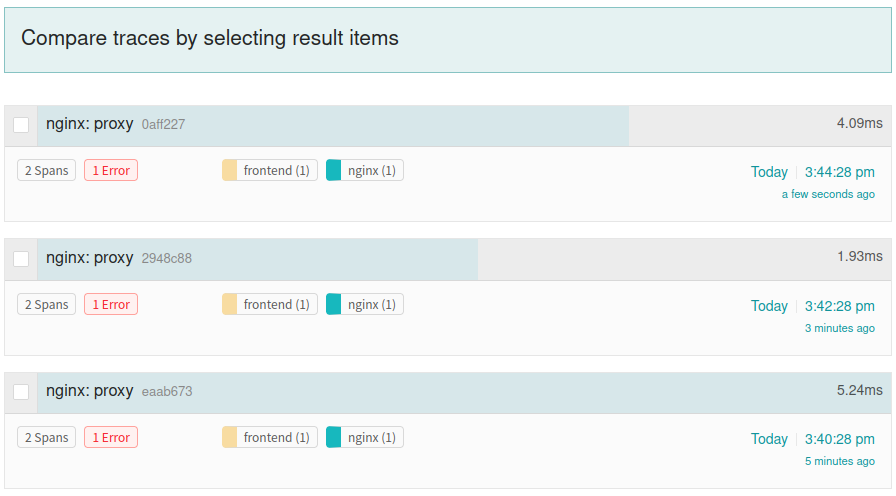
Implementing Health Checks and Runtime Introspection
In the context of our application, health checks let Kubernetes know if a service is healthy or has completed its startup phase. In cases where the service is not healthy, Kubernetes can be configured to terminate or restart instances. In our application, we decided not to use OpenTelemetry health checks because we found the documentation insufficient.
Rather, for the JVM services we use a Spring project called Spring Boot Actuator which provides not only health‑check endpoints, but also runtime introspection and heap‑dump endpoints. For the Python services, we use the Flask Management Endpoints module which provides a subset of Spring Boot Actuator features. Currently, it provides only customizable application information and health checks.
Spring Boot Actuator hooks into the JVM and Spring to provide introspection, monitoring, and health‑check endpoints. Moreover, it provides a framework for adding custom information to the default data it presents at its endpoints. Endpoints provide runtime introspection into things like cache state, runtime environment, database migrations, health checks, customizable application information, metrics, periodic jobs, HTTP session state, and thread dumps.
Health‑check endpoints as implemented by Spring Boot Actuator have a modular configuration such that a service’s health can be composed of multiple individual checks that are categorized as either liveness or readiness. A full health check that displays all the check modules is also available and typically looks like this.
The informational endpoints are defined in a JSON document as a single high‑level JSON object and a series of hierarchical keys and values. Typically, the document specifies the service name and version, architecture, hostname, OS information, process ID, executable name, and details about the host such as a machine ID or unique service ID.
Implementing Heap and Core Dumps
You might recall from the table in Comparing Tool Features Against the Wishlist that none of the tools support runtime introspection or heap/core dumps. However, Spring as our underlying framework supports both – though it took some work to wire the observability features into the application. As detailed in the previous section, for runtime introspection we use a Python module in conjunction with Spring Boot Actuator.
Likewise, for heap dumps we use the thread‑dump endpoints provided by Spring Boot Actuator to accomplish a subset of the features we wanted. We can’t get core dumps on demand nor heap dumps of the JVM at the ideally fine level of granularity, but we get some of the desired functionality with little additional effort. Core dumps for the Python services unfortunately will require a fair bit of additional work which we have postponed until a later date.
Summary
After much crying and questioning our life choices, we have converged on using the following technologies for observability in the MARA (in the following, OTel stands for OpenTelemetry):
- Logging (for all containers) – Filebeat → Elasticsearch / Kibana
- Distributed Tracing
- Java – Spring Cloud Sleuth → Spring Cloud Sleuth exporter for OTel → OTel Collector → pluggable exporters like Jaeger, Lightstep, Splunk, etc.
- Python – OTel Python libraries → OTel Collector → pluggable store
- NGINX and NGINX Plus (NGINX Ingress Controller is not yet supported) – NGINX OTel module → OTel Collector → pluggable exporter
- Metrics Collection
- Java – Micrometer via Spring → Prometheus exporter → OTel Collector
- Python – No implementation yet
- Python WSGI – GUnicorn StatsD → Prometheus (via StatsD / ServiceMonitor)
- NGINX – Prometheus endpoint → Prometheus (via ServiceMonitor)
- Error Aggregation – OTel distributed traces → pluggable exporter → exporter’s search functionality for finding traces marked with
error - Health Checks
- Java – Spring Boot Actuator → Kubernetes
- Python – Flask Management Endpoints module → Kubernetes
- Runtime Introspection
- Java – Spring Boot Actuator
- Python – Flask Management Endpoints module
- Heap/Core Dumps
- Java – Spring Boot Actuator support for thread dumps
- Python – No support yet
This implementation is a snapshot in time. It will definitely change and evolve as development continues. Soon we will be running the application through extensive load testing. We expect to learn a lot about the shortcomings of our observability approach and add additional observability features.
Please try out the Modern Apps Reference Architecture and sample application (Bank of Sirius). If you have ideas on how we can do better, we welcome your contributions at our GitHub repo!
Related Posts
This post is part of a series. As we add capabilities to MARA over time, we’re publishing the details on the blog:
- A New, Open Source Modern Apps Reference Architecture
- Integrating OpenTelemetry into the Modern Apps Reference Architecture – A Progress Report (this post)
- MARA: Now Running on a Workstation Near You
- Announcing Version 1.0.0 of the NGINX Modern Apps Reference Architecture



