

NodePort, LoadBalancer, Ingress controller…oh my!
When we talk with customers and the community about making Kubernetes production‑grade, one of the most common questions is: do I need an Ingress controller? The answer to this question is rarely a simple yes or no, but instead involves some education on the different ways you can get traffic to your pods. In this blog, we cover the basics of Kubernetes networking so you can make an informed decision about if – and when – you need an Ingress controller.
Kubernetes supports several possible approaches and layers to routing external traffic to a pod – but they aren’t all created equal. The default model is kube-proxy, which is not actually a proxy and isn’t designed to load balance traffic, control APIs, or monitor service behaviors.
Fortunately, there are other way to manage external traffic, but before we continue, let’s do a quick review of Kubernetes components:
- Kubernetes deployments are made up of nodes, which are physical or virtual machines.
- Nodes join together to form a cluster.
- Each cluster manages pods, which are the lowest common denominator at the networking and infrastructure level in Kubernetes. One or more pods together make up a service.
- Inside each pod resides one or more containers (depending on the application size).
Kubernetes watches the pods that make up a service and scales them as necessary to match app requirements. But how do you get traffic to the pods? This is where two types of Kubernetes objects come in: services and Ingress controllers.
What’s a Kubernetes Service?
According to the Kubernetes docs, a service is “an abstract way to expose an app running on a set of Pods”. A service connects pods in a cluster or network of containers such that their location on a specific node is not relevant. This means external traffic can be routed to specific pods even as their locations change, or even when they are destroyed and restarted. In this way, a service acts much like a very basic reverse proxy.
There are multiple types of services and service object types relevant to routing external traffic into Kubernetes. They often get confused for each other, but in fact each does very different things, so it’s worth going over their functions, uses, and drawbacks.
ClusterIP
ClusterIP is the default service that provides a service within Kubernetes that other services within the cluster can access. It is not accessible from outside the cluster. The only way to expose a ClusterIP service is to use something like kube-proxy, but there are few scenarios where this makes sense. The limited examples include accessing a service on your laptop, debugging a service, or looking at some monitoring and metrics.
NodePort
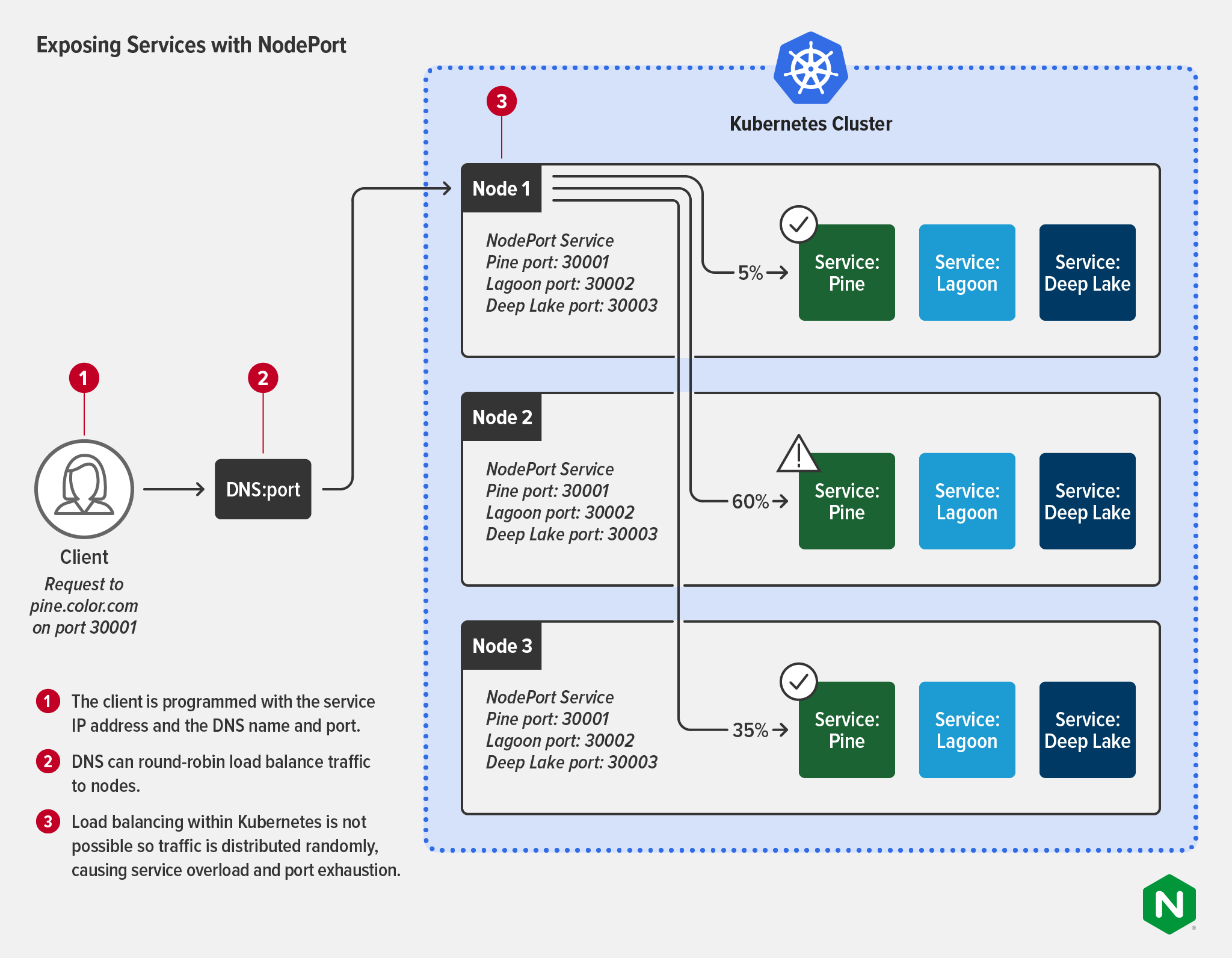
A NodePort service opens a specific port on every node in the cluster, and forwards any traffic sent to the node on that port to the corresponding app. This is a very basic way to get traffic to your apps and it has many limitations in actual traffic‑management use cases. You can have only one service per NodePort, and you can only use ports in the range 30000 through 32767. While 2768 ports may sound like a lot, organizations running Kubernetes at scale will quickly run out. Also, NodePort uses Layer 4 routing rules and the Linux iptables utility, which limits Layer 7 routing.
In addition to routing limitations, there are three other big drawbacks to using NodePort:
-
Downstream clients must know the IP address of each node to connect with it – this becomes problematic if the node’s IP address or virtual machine host changes.
-
NodePort cannot proxy traffic to multiple IP addresses.
-
As shown in the diagram, NodePort doesn’t provide load balancing within Kubernetes clusters, so traffic is distributed randomly across the services. This can result in service overload and port exhaustion.
LoadBalancer
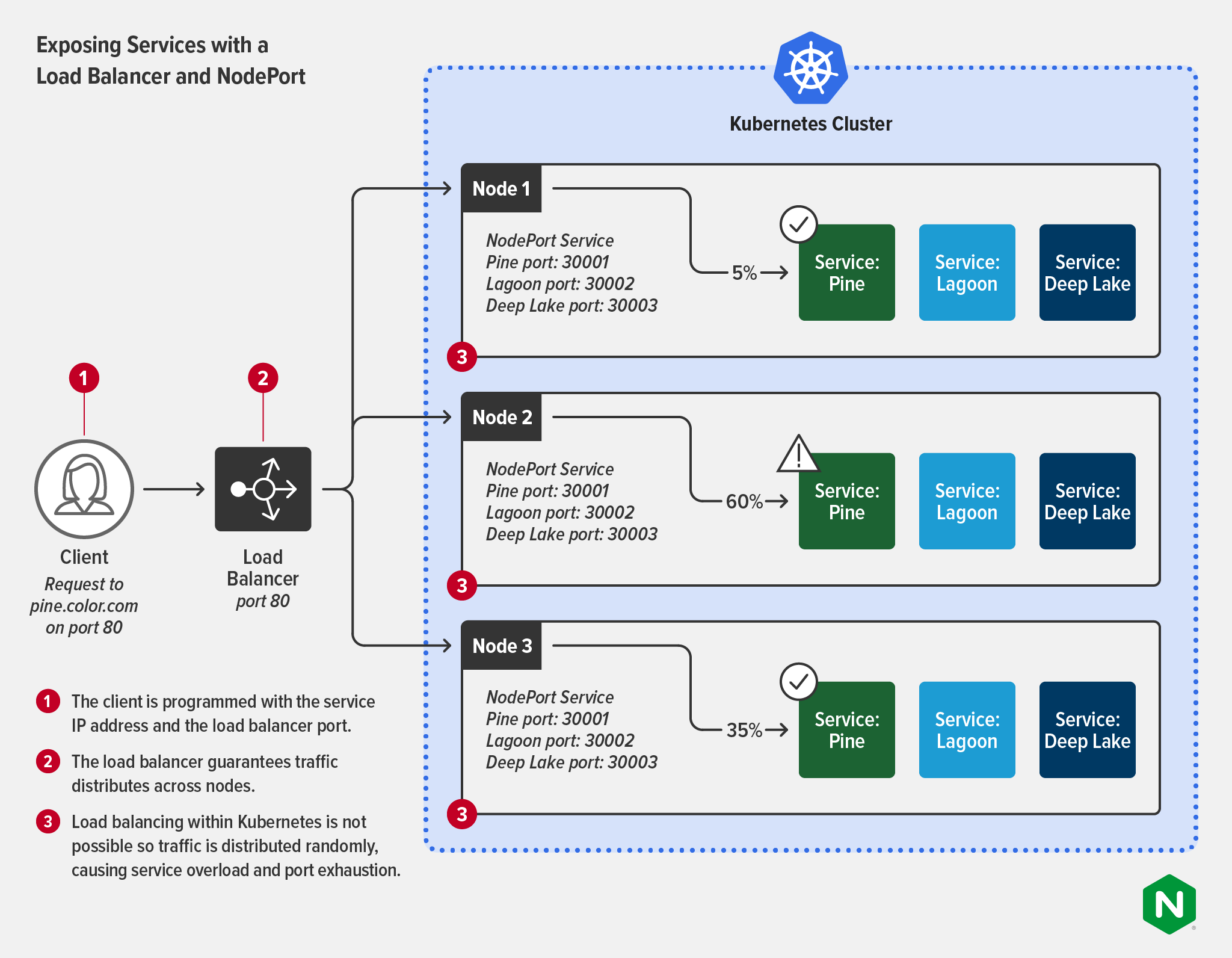
A LoadBalancer service accepts external traffic but requires an external load balancer as an interface for that traffic. This supports Layer 7 routing (to pod IP addresses), provided the external load balancer is properly tuned and reconfigured to map to running pods. LoadBalancer is one of the most popular ways to expose services externally. It’s most often used in a cloud platform and is a good choice for small, static deployments.
If you are using a managed Kubernetes service, you automatically get the load balancer selected by the cloud provider. For example, on Google Cloud Platform you can spin up a Network Load Balancer using the LoadBalancer service type, while Application Load Balancer (ALB) is the default in AWS. Each service you expose gets its own public IP address that forwards all traffic, but without any filtering or routing, meaning you can send almost any type of traffic (HTTP, TCP/UDP, WebSocket, etc). Alternatively, if you don’t want to use the cloud provider’s tooling – for example if you need greater functionality or a platform‑agnostic tool – you can replace it with something like F5 BIG-IP (as the external load balancer) and F5 Container Ingress Services (as an operator acting in the LoadBalancer capacity). For further discussion of this pattern, see Deploying BIG-IP and NGINX Ingress Controller in the Same Architecture on our blog.
Using LoadBalancer to expose your apps becomes challenging in dynamic environments where your app pods need to scale to meet changing levels of demand. Because each service gets its own IP address, a popular app can have hundreds – or even thousands – of IP addresses to manage. In most cases, the external load balancer connects to the services via NodePort as shown in the following diagram. While this guarantees traffic is distributed evenly across the nodes, load balancing to the services still isn’t possible, so you still encounter service overload and port exhaustion.
What’s a Kubernetes Ingress Controller?
According to the Kubernetes docs, “controllers are control loops that watch the state of your cluster, then make or request changes where needed. Each controller tries to move the current cluster state closer to the desired state.” Controllers are used to manage state in Kubernetes for many tasks: properly assigning resources, designating persistent storage, and managing cron jobs.
In the context of routing, an Ingress controller is the way to overcome the limitations of NodePort and LoadBalancer.
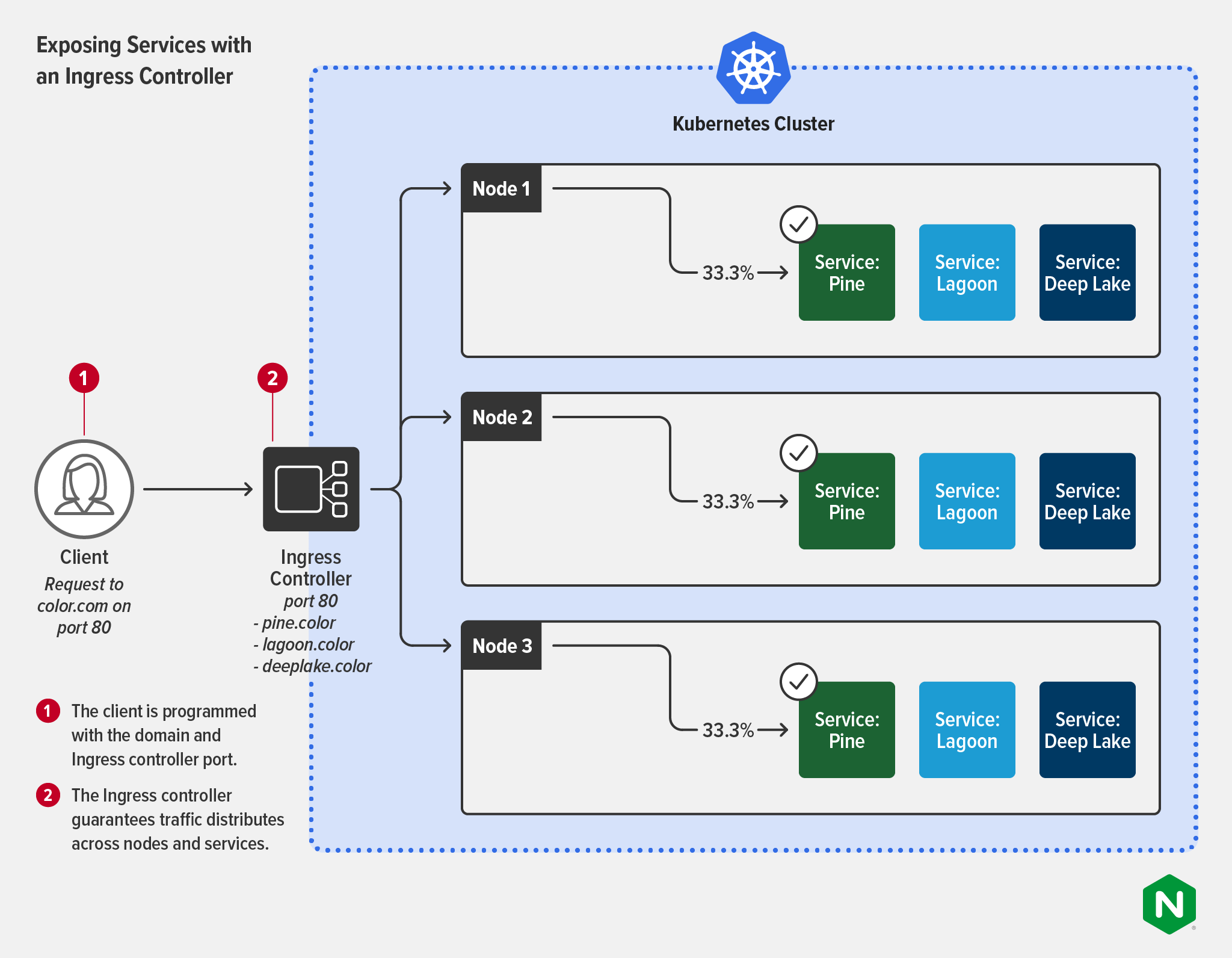
An Ingress controller is used to configure and manage external interactions with pods that are labeled to a specific service. Ingress controllers are designed to treat dynamic Layer 7 routing as a first‑class citizen. This means that Ingress controllers provide far more granular control and management with less toil. You can easily use an Ingress controller not only to control ingress traffic but also to deliver service‑level performance metrics and as part of a security policy. Ingress controllers have many features of traditional external load balancers, like TLS termination, handling multiple domains and namespaces, and of course, load balancing traffic. Ingress controllers can load balance traffic at the per‑request rather than per‑service level, a more useful view of Layer 7 traffic and a far better way to enforce SLAs.
And there’s another bonus! Ingress controllers can also enforce egress rules which permit outgoing traffic from certain pods only to specific external services, or ensure that traffic is mutually encrypted using mTLS. Requiring mTLS is crucial for delivering regulated services in industries such as healthcare, finance, telecommunications, and government – and it’s a key component in an end-to-end encryption (E2EE) strategy. Controlling outgoing traffic from the same tool also simplifies the application of business logic to services. It is far easier to set up appropriate resource rules when both ingress and egress are linked in the same control plane.
The following diagram shows how an Ingress controller reduces complexity for the client, which no longer needs to know a service’s IP address or port. Distribution of traffic across the services is guaranteed. Some Ingress controllers support multiple load‑balancing algorithms for more flexibility and control.
Deploying a Load Balancer with an Ingress Controller
As we discuss in Deploying BIG-IP and NGINX Ingress Controller in the Same Architecture, many organizations have use cases that benefit from deploying an external load balancer with an Ingress controller (or in most cases, multiple Ingress controller instances). This is especially common when organizations need to scale Kubernetes or operate in high‑compliance environments. The tools are typically managed by different teams and used for different purposes:
-
Load balancer (or ADC):
- Owner: A NetOps (or maybe SecOps) team
- Use case: Outside Kubernetes as the only public‑facing endpoint for services and apps delivered to users outside the cluster. Used as a more generic appliance designed to facilitate security and deliver higher‑level network management.
-
Ingress controller:
- Owner: A Platform Ops or DevOps team
- Use case: Inside Kubernetes for fine‑grained load balancing of north‑south traffic (HTTP2, HTTP/HTTPS, SSL/TLS termination, TCP/UDP, WebSocket, gRPC), API gateway functions, and centralized security and identity.
This diagram shows the load balancer handling distribution of the traffic across multiple clusters, while the clusters have Ingress controllers to ensure equal distribution to the services.

Next Steps
If you’ve read all this and are still scratching your head, check out the Linux Foundation webinar Why You Need An Ingress Controller and How to Pick One, where experts from NGINX provide a primer on Kubernetes networking, dive deep into Ingress controllers, and discuss the Ingress controller landscape.
For more on how you can use an Ingress controller – and how to choose one that works best for your requirements – read A Guide to Choosing an Ingress Controller, Part 1: Identify Your Requirements on our blog.


