

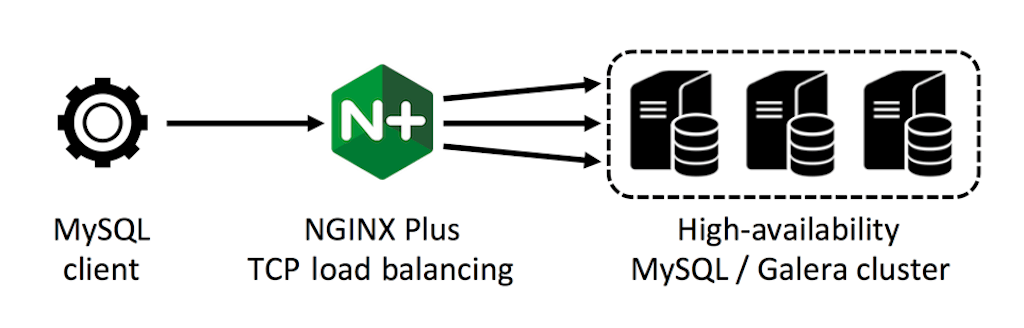
In this article, we create and test a high‑availability database cluster using MySQL, Galera Cluster, and the TCP load balancing capability introduced in NGINX Plus Release 5 (R5). We demonstrate the appropriate MySQL load balancing configuration with NGINX Plus, and techniques for handling conflicting writes and failures across the database cluster.
Introducing Galera Cluster
[Editor – As of November 2021, the two linked web pages in this section that are marked with an asterisk are no longer available at their original location, but are available at web.archive.org. The links have been updated accordingly.]
Galera Cluster is a synchronous replication solution for clusters of MySQL database servers. Database writes are immediately replicated across all nodes in the Galera cluster, and all database servers act as the primary (source) node. With a few caveats* and careful performance testing, a load‑balanced Galera cluster can be used in place of a single MySQL database for critical business data that requires very high availability.
The example in this article uses stock MySQL, following these installation instructions* to deploy three database servers (db1, db2, and db3) on Ubuntu 14.04 images running on DigitalOcean. Installation and cluster bootstrapping should be performed with care, with the end goal of creating a stable cluster of three database servers where each replicates from its two peers. Galera Cluster also supports MariaDB and Percona XtrDB Cluster.
We start with a simple database table (test.data) containing an autoindex id, a value (string), and a count (integer) which is incremented each time the same value is inserted into the table:
CREATE TABLE data (
id INTEGER NOT NULL AUTO_INCREMENT,
value CHAR(30),
count INTEGER,
PRIMARY KEY (value),
KEY (id)
);We execute this CREATE on one database instance and verify that the table is replicated to the peer instances.
Configuring NGINX Plus for MySQL Load Balancing
We configure NGINX Plus to load balance database connections across the three servers in a round‑robin fashion (the default):
stream {
upstream db {
server db1:3306;
server db2:3306;
server db3:3306;
}
server {
listen 3306;
proxy_pass db;
proxy_connect_timeout 1s; # detect failure quickly
}
}Then we connect to the databases through NGINX Plus and use an SQL query to determine which instance we’re connected to:
# mysql -u galera -p --protocol=tcp
Enter password: ********
mysql> SHOW VARIABLES WHERE Variable_name = 'hostname';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| hostname | db2 |
+---------------+-------+To confirm that NGINX Plus is load balancing our connections across the three servers in round‑robin fashion, we can reconnect repeatedly.
Testing the Database Cluster
To test the database cluster, we insert entries into the table and deliberately provoke collisions. New entries begin with a count of 1, and duplicates (collisions) increment the count.
mysql> INSERT INTO data (value, count) VALUES ( '$value', 1 )
ON DUPLICATE KEY UPDATE count=count+1;The attached simple Perl script (query1.pl) inserts or increments 100 entries, and prints the name of the instance to which each transaction was sent:
$ ./query1.pl
db3
db1
db2
db3
...
mysql> SELECT * FROM data;
+-----+-----------+-------+
| id | value | count |
+-----+-----------+-------+
| 3 | value-000 | 1 |
| 4 | value-001 | 1 |
...
| 101 | value-098 | 1 |
| 102 | value-099 | 1 |
+-----+-----------+-------+
100 rows in set (0.04 sec)We observe that the UPDATEs were round‑robin load balanced across the databases, and that when we run more UPDATEs in series, the count is correctly updated:
$ ./query1.pl ; ./query1.pl ; ./query1.pl
...
mysql> SELECT * FROM data;
+-----+-----------+-------+
| id | value | count |
+-----+-----------+-------+
| 3 | value-000 | 4 |
| 4 | value-001 | 4 |
...
| 101 | value-098 | 4 |
| 102 | value-099 | 4 |
+-----+-----------+-------+
100 rows in set (0.04 sec)Handling Problems with Parallel UPDATEs
We start again with a fresh database table:
mysql> DROP TABLE data;
mysql> CREATE TABLE data ( id INTEGER NOT NULL AUTO_INCREMENT, value CHAR(30),
count INTEGER, PRIMARY KEY (value), KEY (id) );We perform the UPDATEs in parallel (20 instances):
$ for i in {1..20} ; do ( ./query1.pl& ) ; doneThere are occasional errors from the database:
DBD::mysql::st execute failed: Deadlock found when trying to get lock; try
restarting transaction at ./query1.pl line 42.Inspecting the table shows that very few entries have been incremented all the way to 20:
mysql> SELECT * FROM data;
+------+-----------+-------+
| id | value | count |
+------+-----------+-------+
| 1 | value-000 | 14 |
| 31 | value-001 | 15 |
...
| 2566 | value-098 | 18 |
| 2601 | value-099 | 20 |
+------+-----------+-------+
100 rows in set (0.03 sec)This is a consequence of the Galera replication process; when UPDATEs to the same record are executed in parallel across databases, a deadlock can occur and the database rejects the transaction.
In some situations, this behavior is acceptable. If an application is unlikely to submit conflicting updates in parallel, and the application code can gracefully handle these very infrequent rejected transactions (by returning an error to the user, for example), then it might not be a serious issue.
If this behavior is not acceptable, the simplest solution is to designate a single primary database instance in the upstream server group, by marking the others as backup and down:
upstream db {
server db1:3306;
server db2:3306 backup;
server db3:3306 down;
}With this configuration, all transactions are routed to db1. If db1 fails, current connections are dropped and NGINX Plus fails over to db2 for new connections. Note that db3 acts as a silent partner in the cluster, and only receives updates from db1 and db2.
If you test this configuration, you’ll observe that on each database instance, all entries are present and have the correct count value of 20. However, if db1 fails during the test, a small number of transactions will be lost.
A Better Solution for MySQL High Availability
Transactions can fail for a variety of reasons. If we need a very high degree of protection, we need to ensure that our application can detect and retry failed transactions appropriately. NGINX Plus and Galera can take care of the rest.
In our test client, it’s sufficient to catch failures and wrap database transactions in an exception handler that restarts the transaction after a short pause, as illustrated by query2.pl:
my $backoff = 0.1; # exponential backoff, in seconds
TRY:
eval {
... YOUR CODE HERE ...
... perform DB operations, and call die() on failure
} or do {
print "Failed: $@";
select( undef, undef, undef, $backoff );
$backoff *= 1.5;
goto TRY;
};With this modification, we can return to the original load‑balancing approach (three active databases) and test parallel updates again. The frequent deadlock errors are detected and the corresponding transactions retried. Counts are correctly incremented and the system is demonstrated to be reliable with multiple active primary nodes:
mysql> SELECT * FROM data;
+------+-----------+-------+
| id | value | count |
+------+-----------+-------+
| 1 | value-000 | 20 |
| 33 | value-001 | 20 |
...
| 2964 | value-098 | 20 |
| 2993 | value-099 | 20 |
+------+-----------+-------+
100 rows in set (0.04 sec)Resilience against Database Failure
This system is also resilient against database failure. We can simulate failures by shutting down one or more of the database servers while submitting multiple parallel updates to the cluster. Note that we reduce the value of proxy_connect_timeout to 1 second (1s) in our NGINX server configuration so that NGINX can detect connect failures quickly.
As expected, the client code receives a range of errors as the databases are shut down and restarted mid‑transaction:
Failed: Can't connect to DBI:mysql:test:dev: Lost connection to MySQL server at
'reading initial communication packet', system error: 0 at ./query2.pl line 28.
Failed: Can't execute 'SHOW VARIABLES WHERE Variable_name = 'hostname';': Lost
connection to MySQL server during query at ./query2.pl line 33.
Failed: Can't execute 'INSERT INTO data (value, count) VALUES ( 'value-020', 1 )
ON DUPLICATE KEY UPDATE count=count+1': Unknown command at ./query2.pl line 45.Despite these errors, throughout extensive testing not a single transaction was dropped or executed twice, and the three databases remained consistent. The combination of appropriate application logic, NGINX Plus load balancing, and Galera Clustering delivers a solid, high‑performance, and above all, 100% reliable MySQL database cluster.
To try out NGINX Plus for MySQL load balancing in your own environment, start your free 30-day trial today or contact us to discuss your use cases.


