


This post is adapted from a webinar by Floyd Smith of NGINX, Inc. and Sandeep Dinesh and Sara Robinson of Google. It is the second of two parts and focuses on NGINX Plus as a load balancer for multiple services on Google Cloud Platform (GCP). The first part focuses on deploying NGINX Plus on GCP.
You can view the complete webinar on demand. For more technical details on Kubernetes, see Load Balancing Kubernetes Services with NGINX Plus on our blog.
Table of Contents
14:47 Load Balancing Kubernetes

Sandeep Dinesh: We saw how we can launch NGINX Plus on Google Cloud Platform with the Cloud Launcher. [Editor – Google Cloud Launcher has been replaced by the Google Cloud Platform Marketplace.] Now let’s talk about load balancing Kubernetes with NGINX Plus.
Floyd did a really good job talking about microservices vs. monoliths and how a microservices architecture lets you break up your application into multiple endpoints that all work together. And when you have multiple things all working together, you need something to distribute traffic and do things like service discovery, so they all play nice together. This is where Kubernetes and NGINX Plus really comes into play.
15:19 What Is Kubernetes?

Kubernetes is a project that was started at Google. It’s 100% open source and it’s the Greek word for ‘helmsman’, which is also the root of the word ‘governor’. And what that means is it’s governing or orchestrating your containers in the cluster. So, it’s a container orchestrator. Basically, when you run Docker containers, you have to have a way to run them, deploy them, manage them, and Kubernetes makes it super easy to do that.
Instead of manually deploying your Docker containers, you instead manage a cluster. Kubernetes supports multiple clouds and bare‑metal environments because it is open source.
At Google, we’ve been running containers for the last ten years and we had to build a lot of tools internally to manage those containers, tools like Borg and Omega. Kubernetes is our third‑generation container orchestration tool, and we’ve decided to go open source with it. It’s written in Go. We think it’s pretty cool. You can check it out at kubernetes.io. Kubernetes’ mantra is “Manage applications, not machines”.
Let’s go through some high‑level Kubernetes concepts.
16:27 Pods
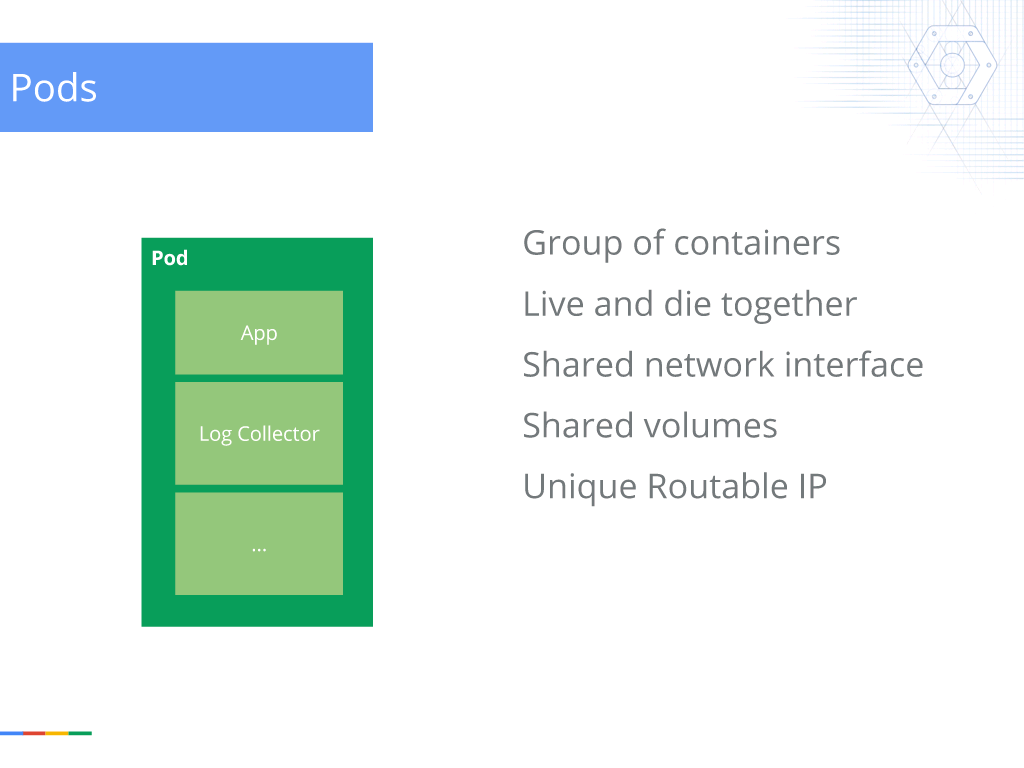
The lowest level of Kubernetes is something called a pod, a group of one or more containers that live and die together – so if one of the containers dies, the whole pod dies.
They have a shared network interface, so localhost is the same across all the pods, and they share volumes as well. So, you could think of this as the atom of Kubernetes. This is what we are managing.
16:57 Deployments
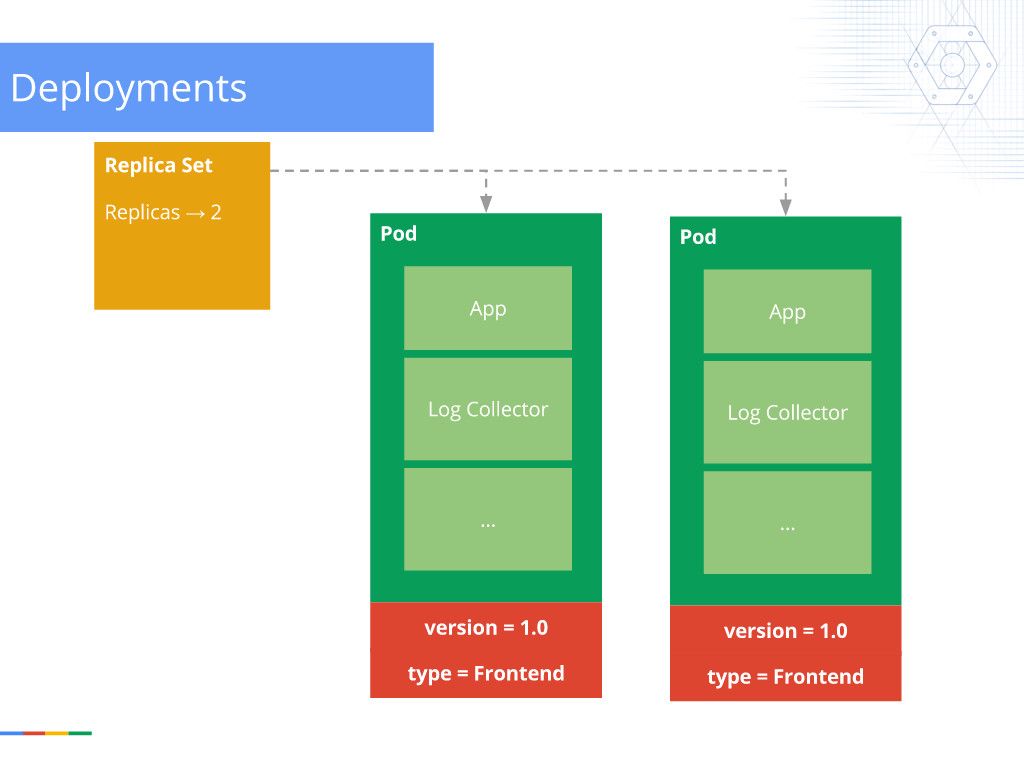
The next step is deployments, which are how you actually run your code in your cluster. So, with the deployment, you tell it what kind of pod you want to run and how many of it you want to run.
In this case, I want to run two pods. The version is 1.0 and the type is Frontend, which is just a simple label.
The cool thing about a deployment is that if one of the pods dies, the deployment automatically recognizes that only one pod is remaining and spins up another one somewhere else in the cluster. So, even if a full VM or machine goes down, the deployment automatically detects this and spins up additional workers on other resources.
The other really cool thing about deployments is they allow you to scale to new versions and roll back to old versions in production, live. Let’s say that you deploy a new version; it actually spins down the old version and spins up the new version in real time, allowing you to monitor and see what’s happening. And if you have a problem with that, you’re sort of panicking and kind of deployed the old version, you can just redeploy the older version directly from the deployment. And so, it spins back to that working old version without you having to worry about, “Did I change some code?” and things like that.
And there’s also a lot of to‑do things like scaling up and down, so from Replicas → 2 you can go to Replicas → 4 or Replicas → 0. Again, the simple API call.
18:29 Services
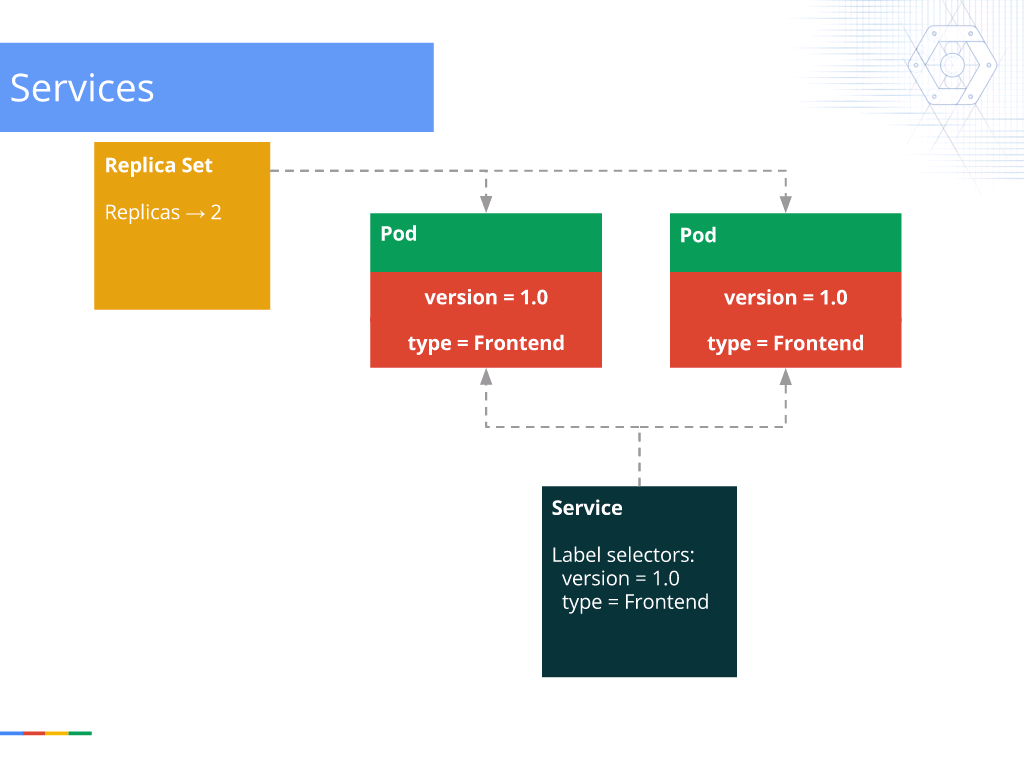
Finally, the last part of Kubernetes is the service.
With the deployment, you can have a variable number of pods running anywhere in your cluster. So, you have to be able to find where these workers are running. This is where services come in.
A service is a stable endpoint that load balances traffic to the pods. You don’t have to remember how many pods are running or where they’re running. As a user of the service, you just have to remember the service’s DNS name or IP address and you’re good to go.
This makes service discovery and load balancing very easy in a Kubernetes cluster.
19:05 An NGINX Load Balancer for Kubernetes Services
What we’re going to do in our demo, coming right up, is build an NGINX load balancer for Kubernetes services.
Let’s take a look at what that looks like.
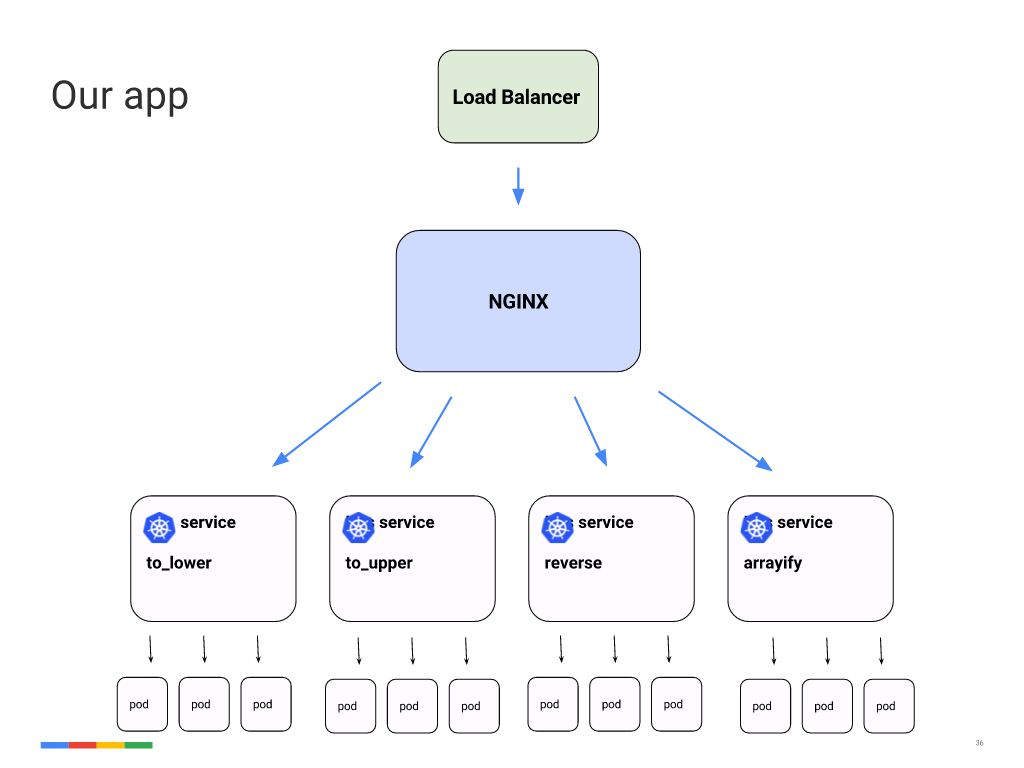
In our app, and this is a fairly typical use case, we’re going to have four microservices running in our cluster. They’ll be doing basic [text] manipulation, so [make all the letters in a string] lowercase or uppercase, reverse [their order], and “arrayify” [add them to an array].
We’re going to have an external load balancer – a Google Cloud Platform network load balancer – that’s going to forward traffic to NGINX Plus, and then NGINX Plus is going to do intelligent Layer 7 load balancing based on the URL that we’re giving it, and it’s going to proxy traffic to one of the four services. And each of the four services is going to have three copies of the worker running for high availability.
20:17 Demo
So now let’s go into our demo, which we’ll run through with Sara.
Demo – The Four Services
Sara Robinson: I’m going to share my screen, and the first thing we’ll do is take a look at the code for each of the Kubernetes services.
I’ve opened up Sublime to give a quick overview of the architecture of our app. Here you can see we have the four services that Sandeep mentioned, which do various string manipulations: arrayify, reverse, to_lower, and to_upper. [As she says this, she is mousing over the names of the four services in the left‑hand navigation bar of the Sublime window.] We wrote those all in different languages, just to show you that the services can act pretty independently of each other.
Let’s take a look at each of these services.
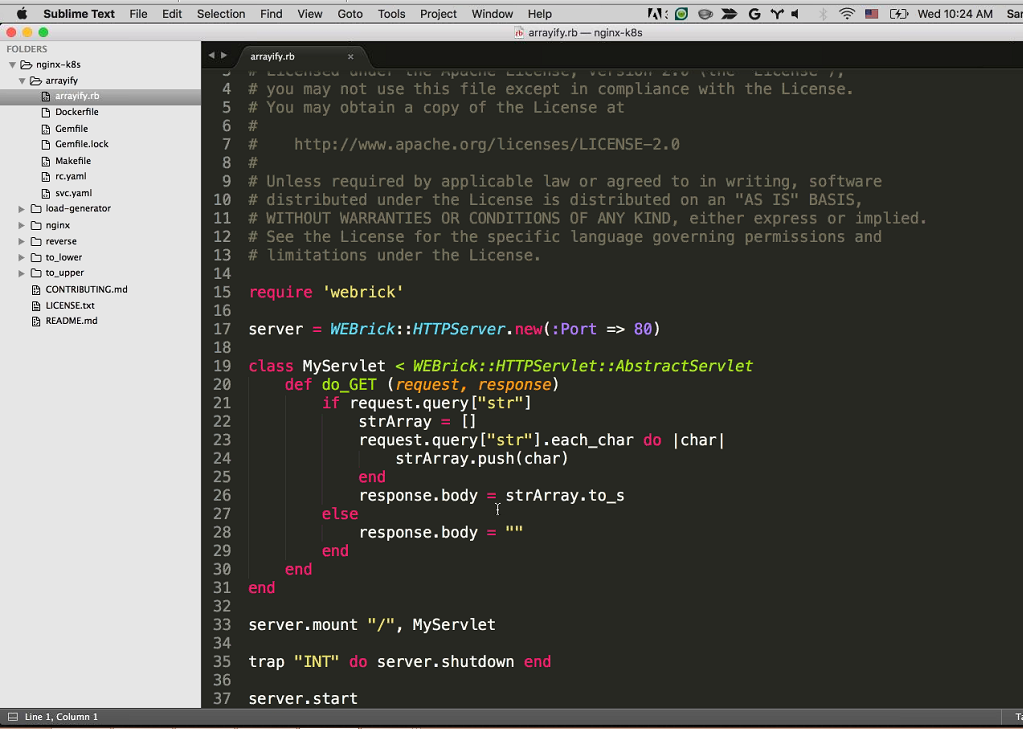
Here we have arrayify, which is written in Ruby. We’re starting up a WEBrick server and we’re just listening for the string query. Once we get a request with a string, we’re getting the value of the string and just appending each character into an array. Pretty simple.
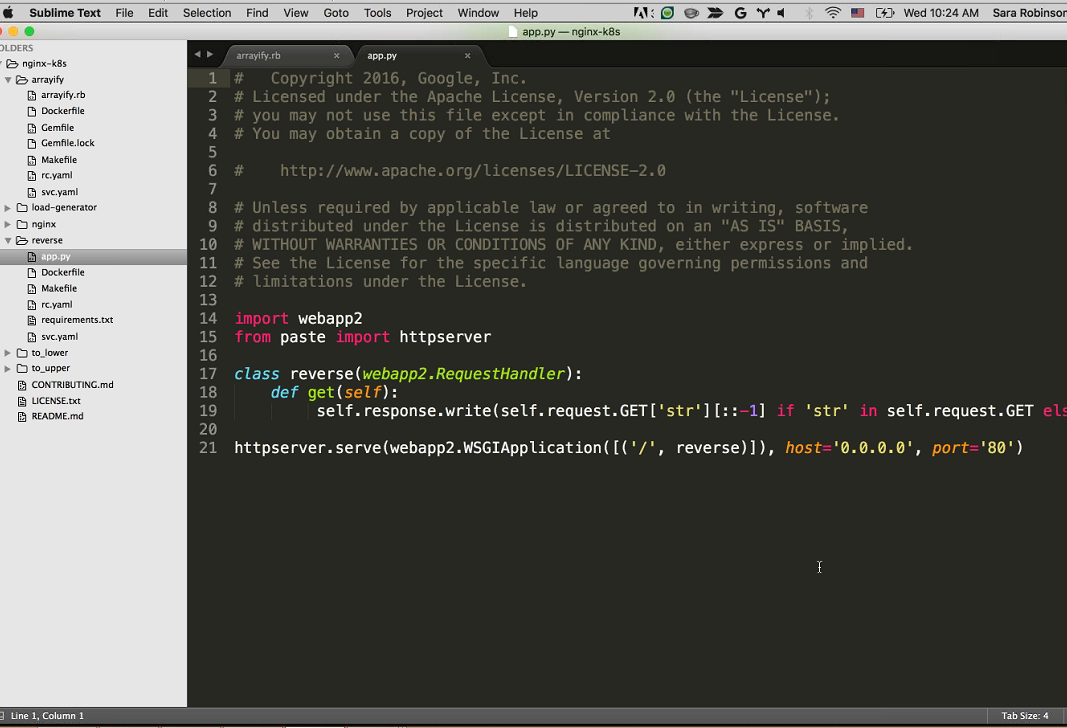
Sandeep: Here is the reverse service in Python. It’s just taking that requested string, the request query, and then reversing it using Python.
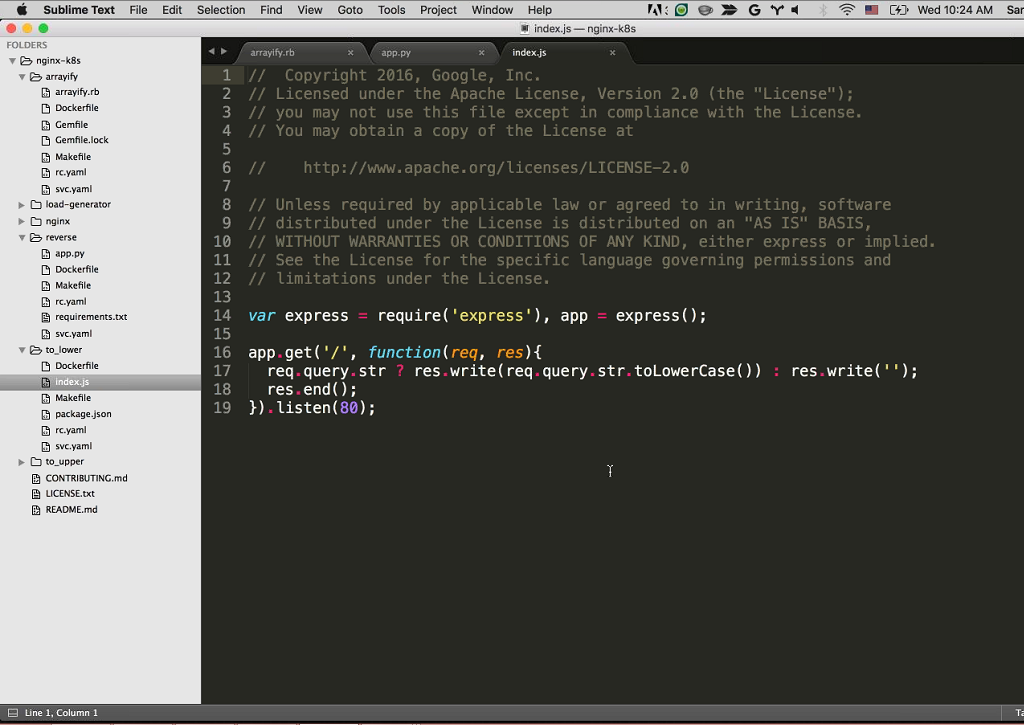
Sara: Then we have to_lower, which is written in Node. So, basically just converting the string to lowercase and listening on port 80.
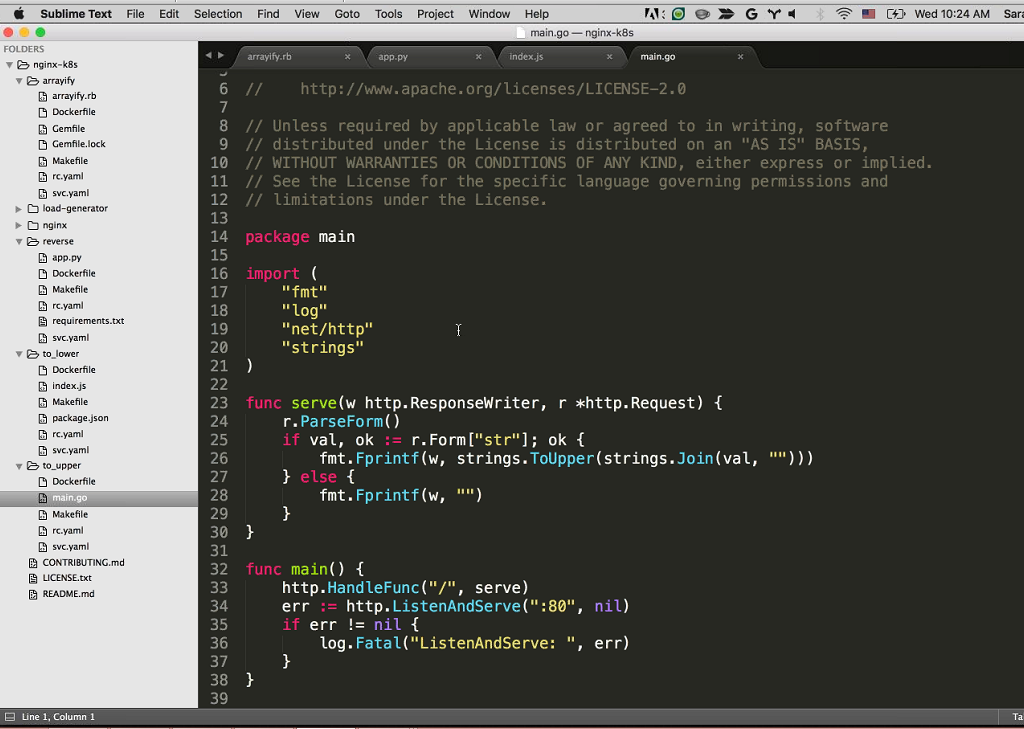
Sandeep: And then here we have to_upper which is written in Go. Again, it just makes the letters uppercase.
These are four independent services, which can be completely broken apart through microservices. They’re written in completely different languages, but they’re running on the same cluster on the same machine and Kubernetes is managing them all. Let’s take a look at how Kubernetes does that.
Demo – Deploying Service Instances
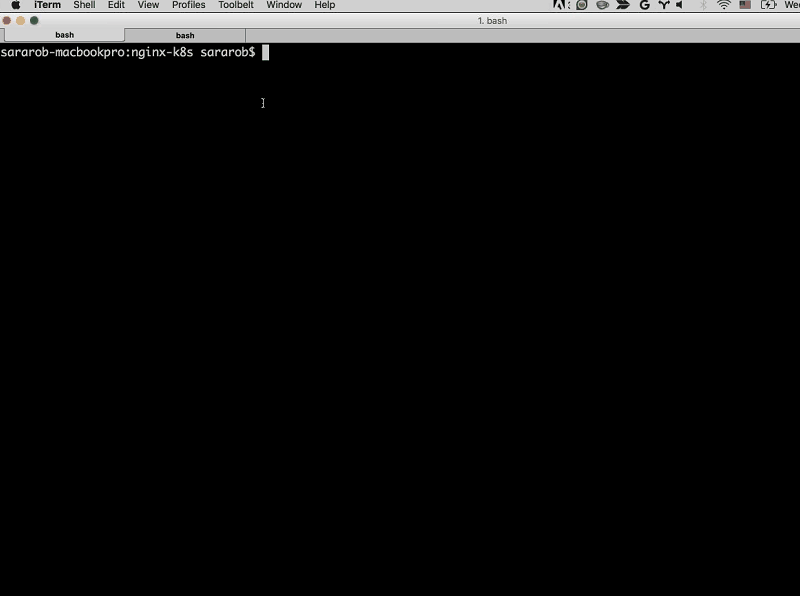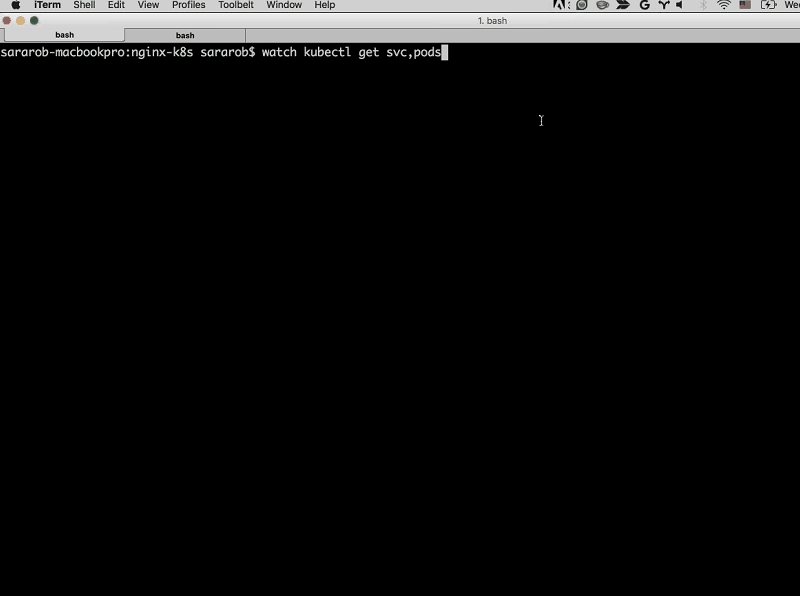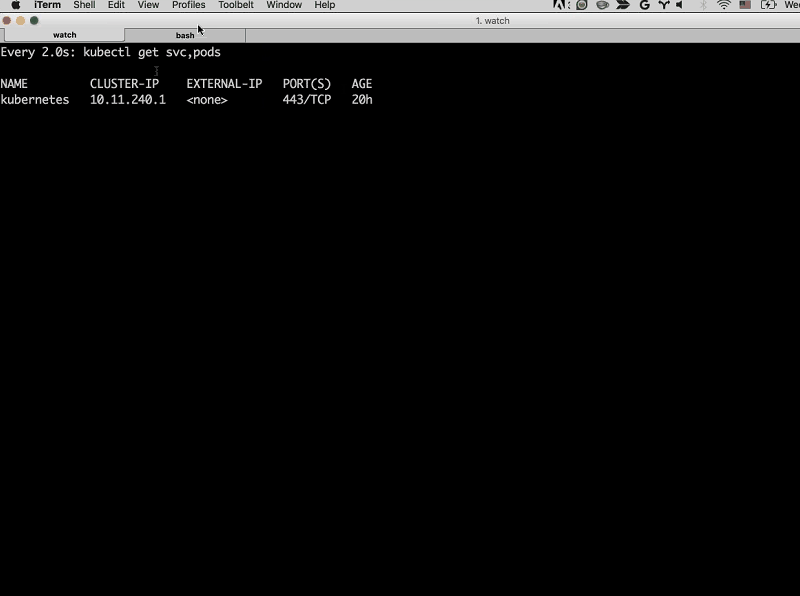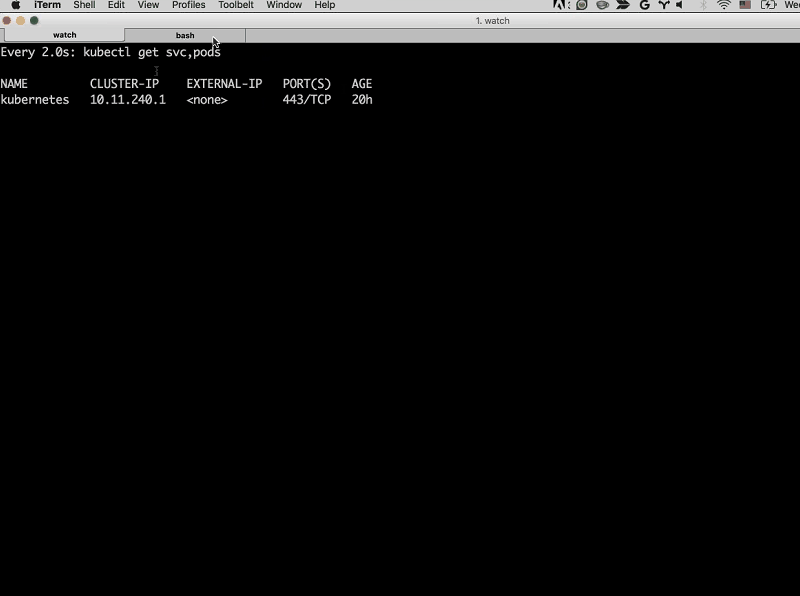
Sara: The first thing we’ll do is deploy each of these services. I’m going to open up the command line here, and I’m going to run a watch command so that we can watch every time a new service or pod is started.
Right now, as you can see, we don’t have any of the services deployed.
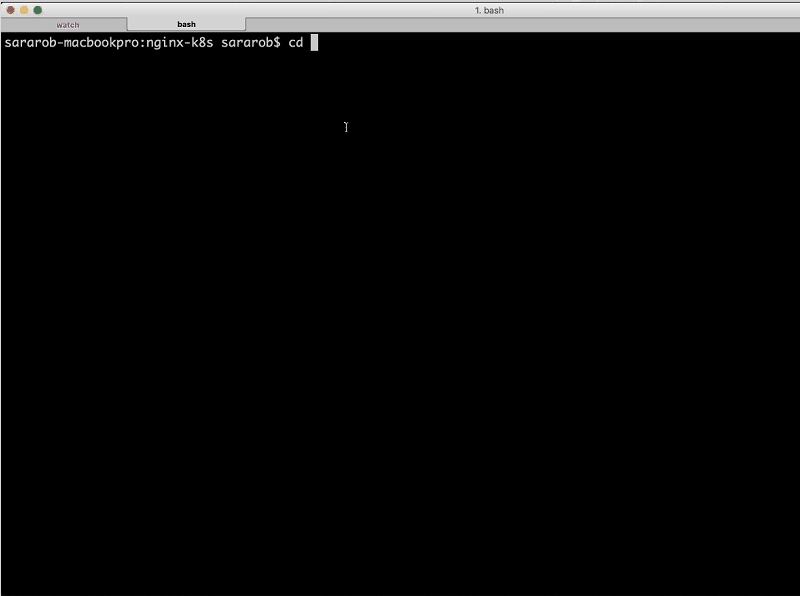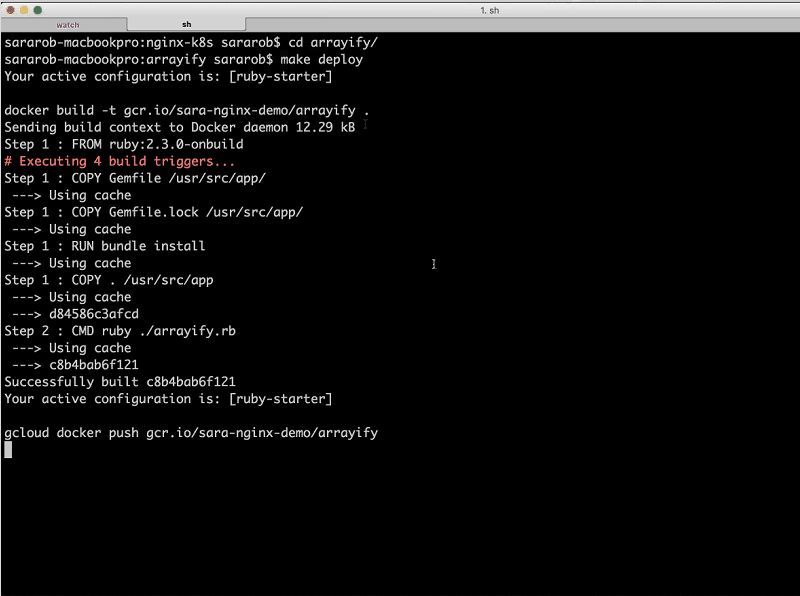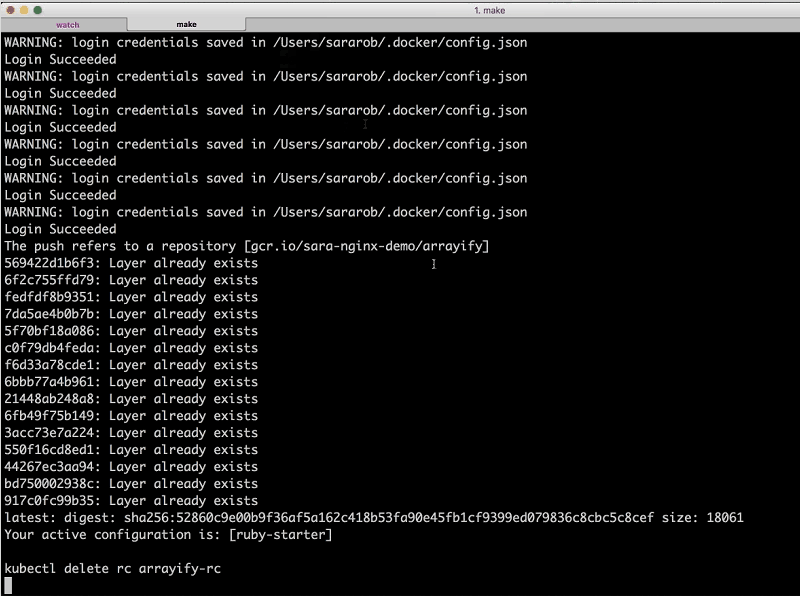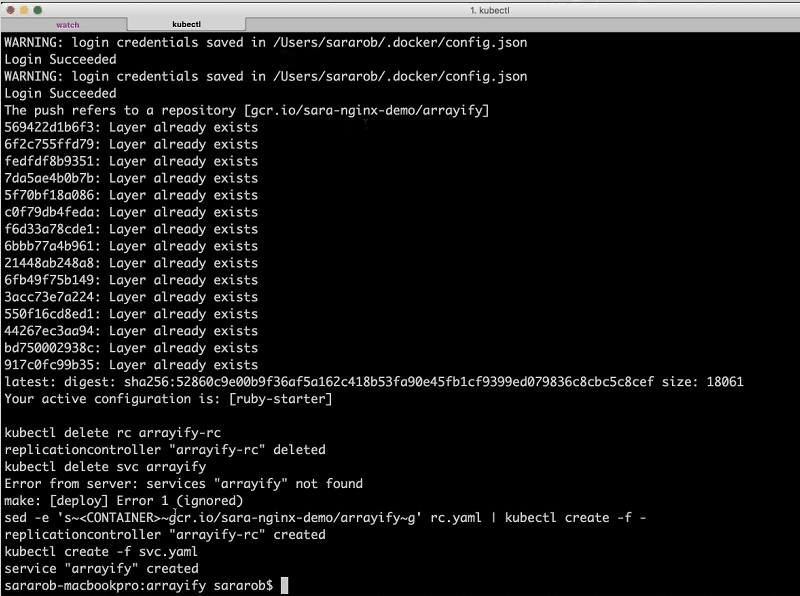
Now I’m going to go over to this tab [a second terminal window] and I’ll start by deploying the arrayify service. I’m going to cd into the arrayify directory, and the only thing I need to do to deploy the service is run the command make deploy.
Sandeep: make deploy does a few things. First it runs a Docker build command that’s actually building our Docker image, and then it’s pushing it up to Google Container Registry (GCR), which is like a private Docker Hub that lives in Google Cloud Storage. Finally, it creates the replication controller and the service.
Sara, you want to show them what the replication controller looks like?

Sara: Yes. This is the replication controller here. You can see that we want three replicas.
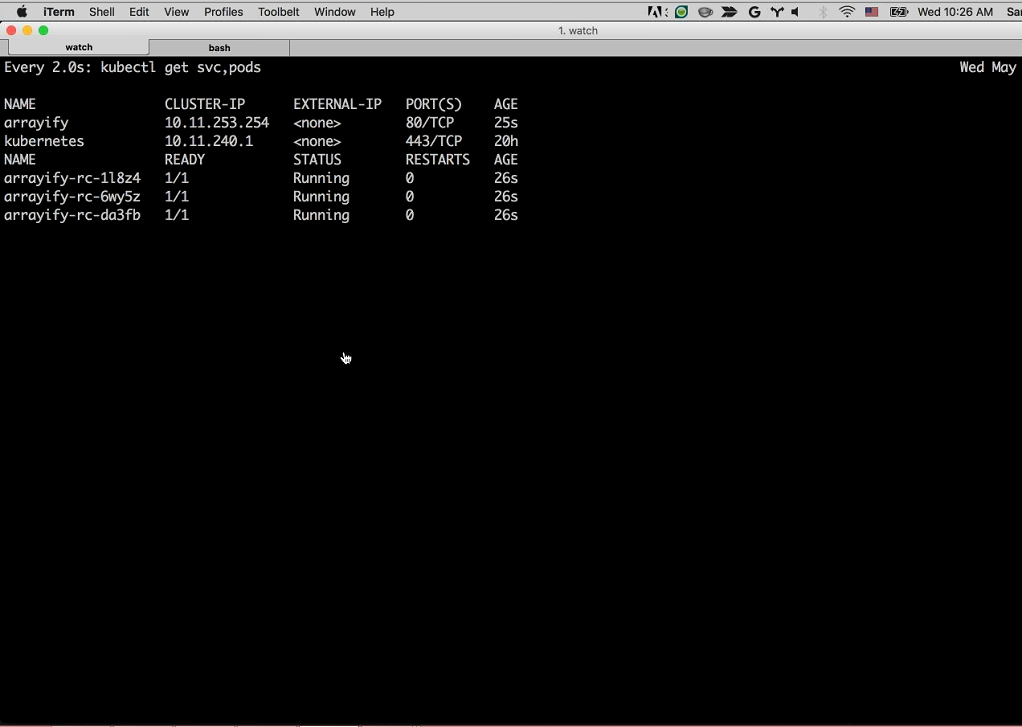
If we go back to our watch command we can see … that three instances of arrayify [have already been deployed] and are running. Now let’s take a look at the Dockerfile.
Pretty simple – it’s just grabbing the latest Ruby Docker image.
Next I’m going to deploy the reverse service.
Sandeep: And I’m going to deploy the to_upper and to_lower services as well, while she’s doing that.
[The relevant commands do not appear in the screenshot, but the lower and then upper instances appear in turn along with their associated controllers.]
Sara: Let’s go back and take a look at the watch [output]. As we deploy those services on his end, we should see three more instances of each added.
There goes lower; that replication controller is ready, up, and running.
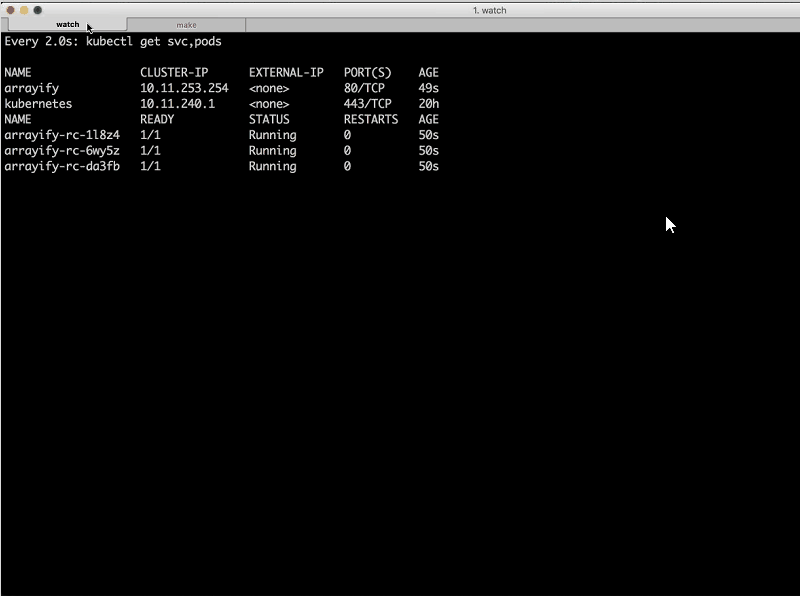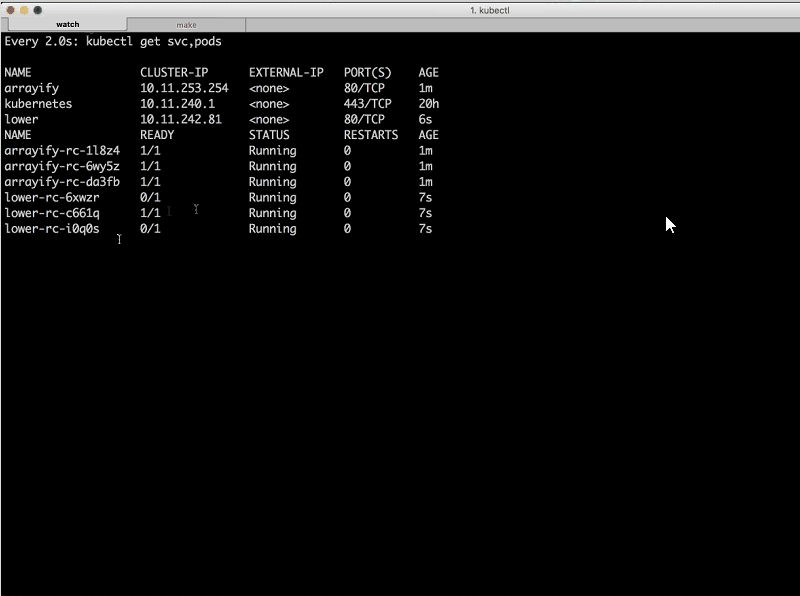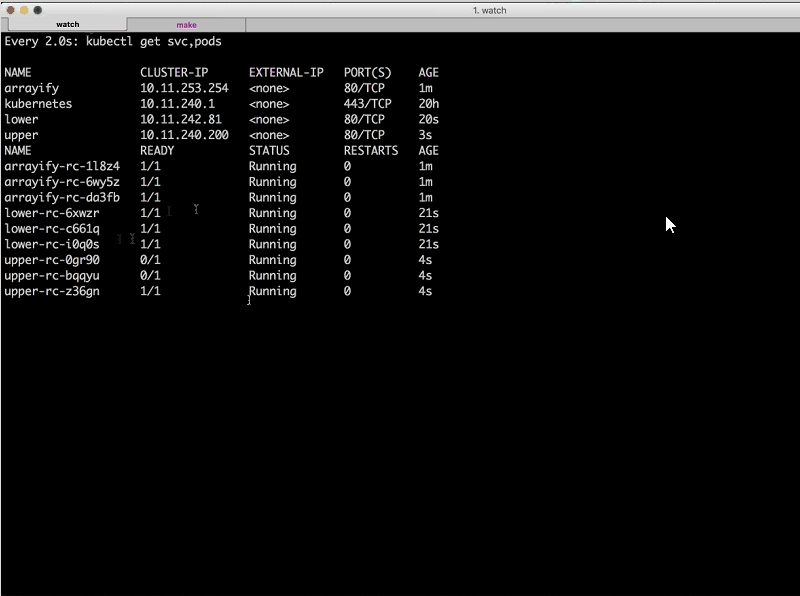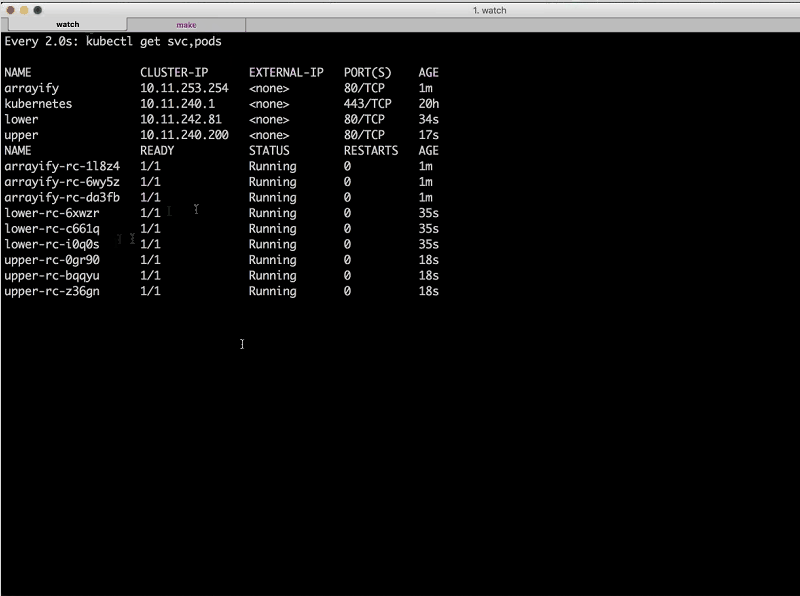
Sandeep: Now I’m going to start running upper so we should have all four [services running] in our cluster pretty soon.
You might notice that we have both the service [instances] and the replication controllers in this dashboard that Sara’s showing [the watch window]. We have three instances of each service (lower, upper, and arrayify [the reverse instances don’t appear in the sreenshot]) and then we have [entries for the] services on top [displayed above the list of instances]. Each service has its own cluster IP address.
These are internal cluster IP addresses and internal DNS names – arrayify, lower, and upper – that our microservices can use to talk to each other. They are not exposed to the external world, so what we need to do is expose them and then put NGINX in front to load balance them intelligently.
Demo – Deploying NGINX Plus
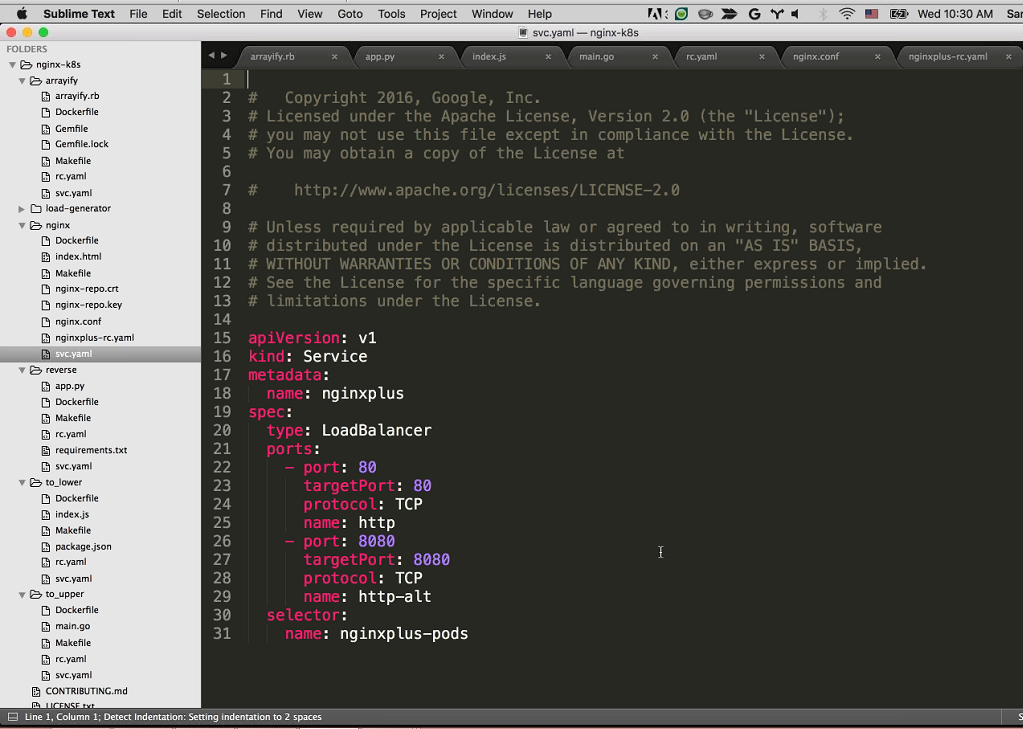
Sara: To do that, let’s take a look at the NGINX Plus configuration file we have in our nginx directory.
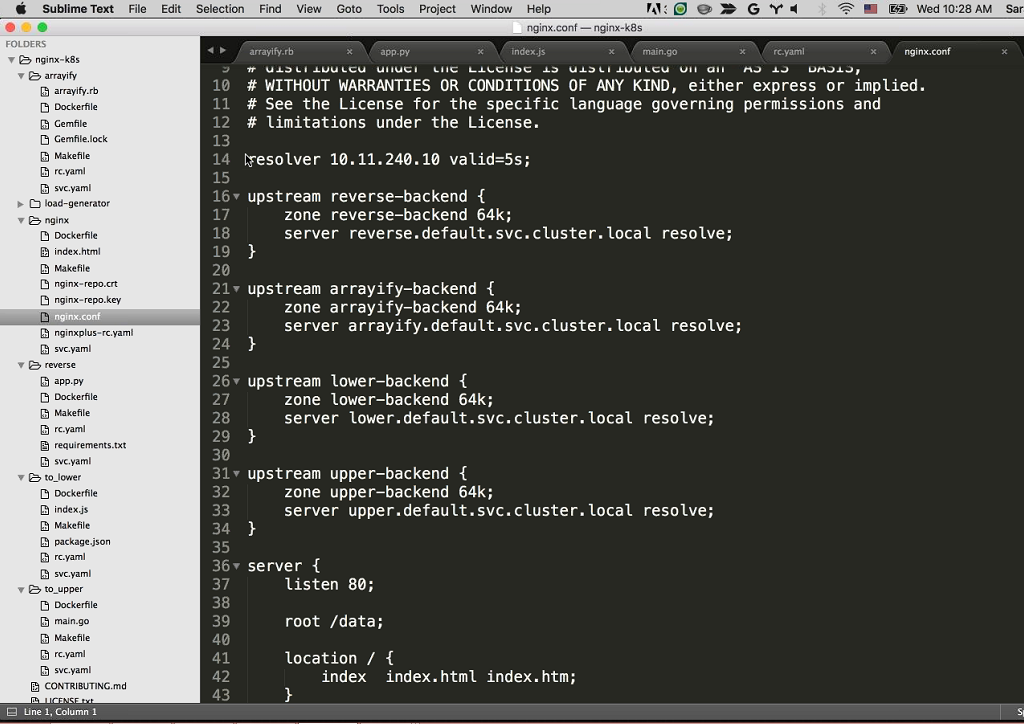
We can see we also have our NGINX certificate and key in here for NGINX Plus [she mouses over nginx-repo.crt and nginx-repo.key in the navigation bar]. Sandeep’s going to talk a little bit about our NGINX Plus configuration.
Sandeep: Sure. On line 14 is the restart. This is our resolver and it’s using the internal DNS built into Kubernetes [at 10.11.240.10] to do DNS resolution. So, we’re actually using the Kubernetes DNS server to find where our microservices are. This gives us service discovery without having to hardcode the IP addresses of our different upstreams.
Speaking of upstreams, we have four, because we have four services. There’s reverse-backend, arrayify-backend, lower-backend, and upper-backend, and all they’re doing is using the DNS built into Kubernetes, so upper.default.svc.cluster.local is the uppercase service’s DNS endpoint. I’m using the resolver [that is, the DNS server specified by the resolver directive] to resolve that.
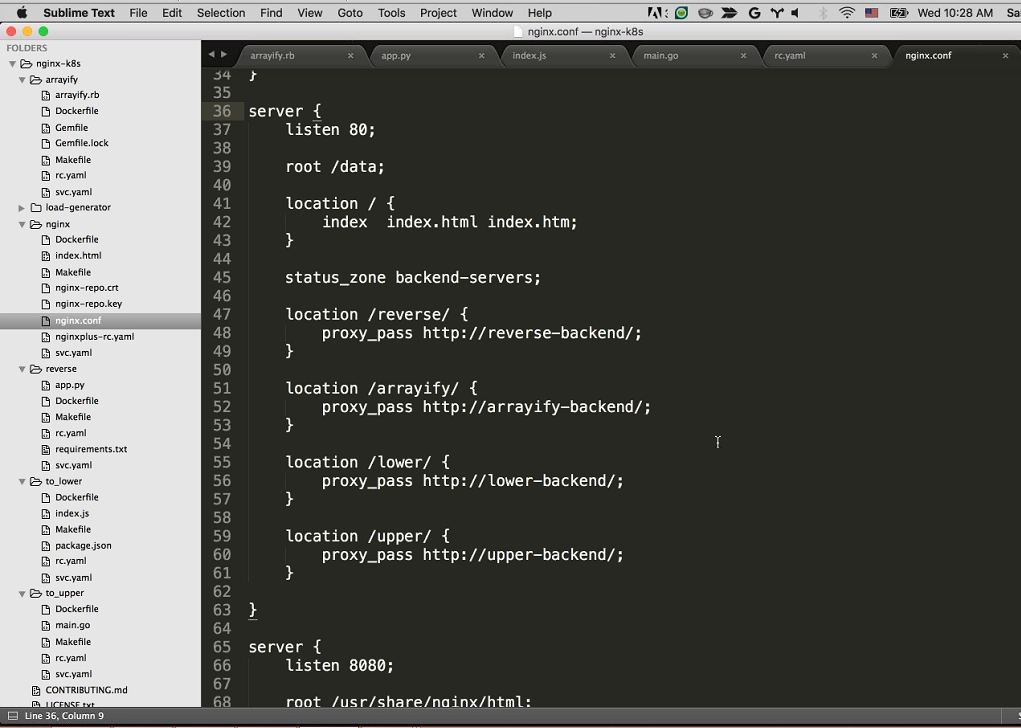
We’re listening on port 80 and all we have to do is use proxy_pass to proxy the different paths to our appropriate backend. The /reverse, /arrayify, /lower, and /upper locations proxy respectively to reverse-backend, arrayify-backend, lower-backend, and upper-backend backend. Makes a lot of sense.
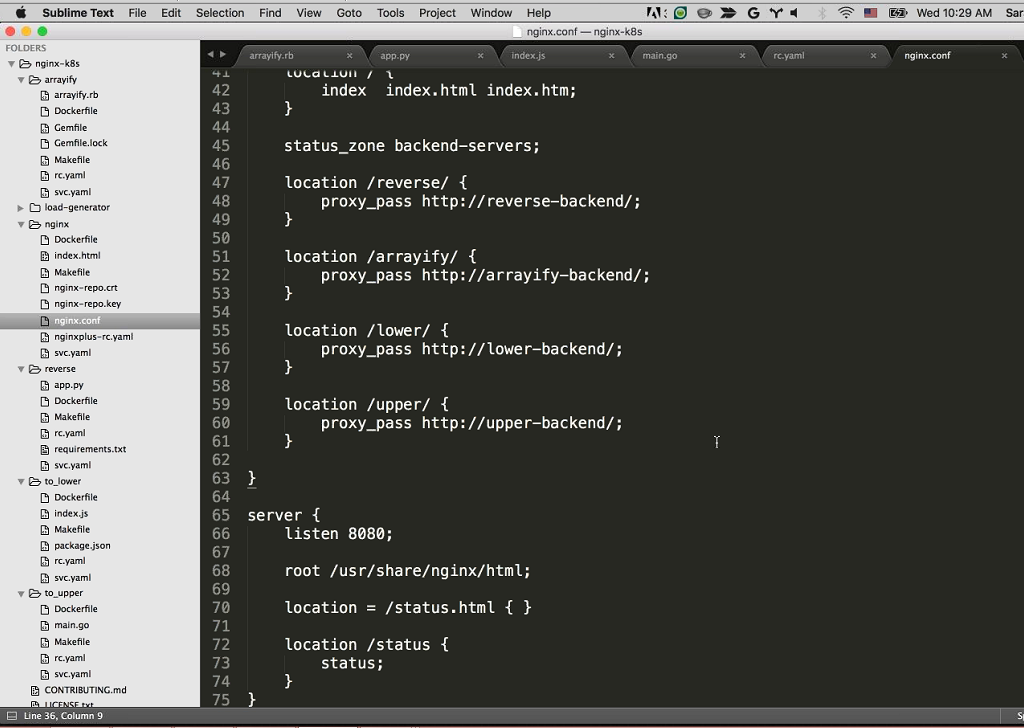
And finally, on port 8080 we’re running the NGINX Plus dashboard to show what’s happening in real time.
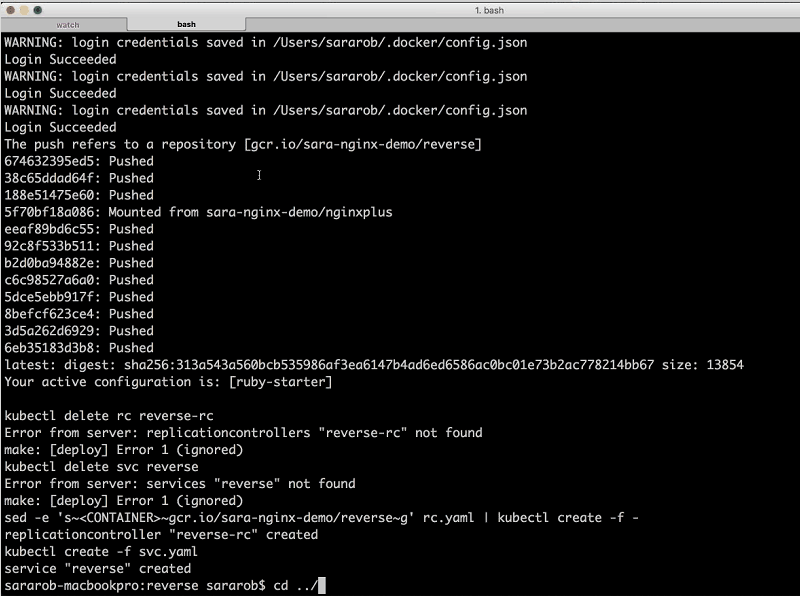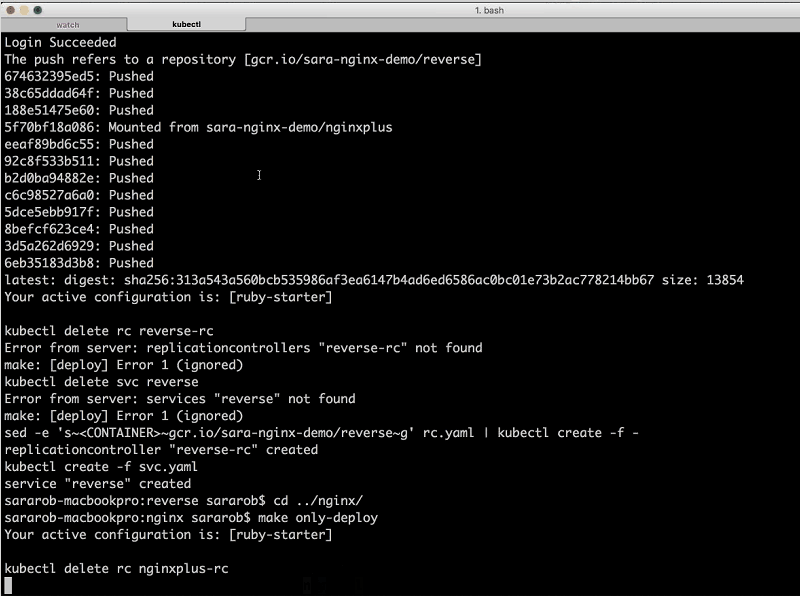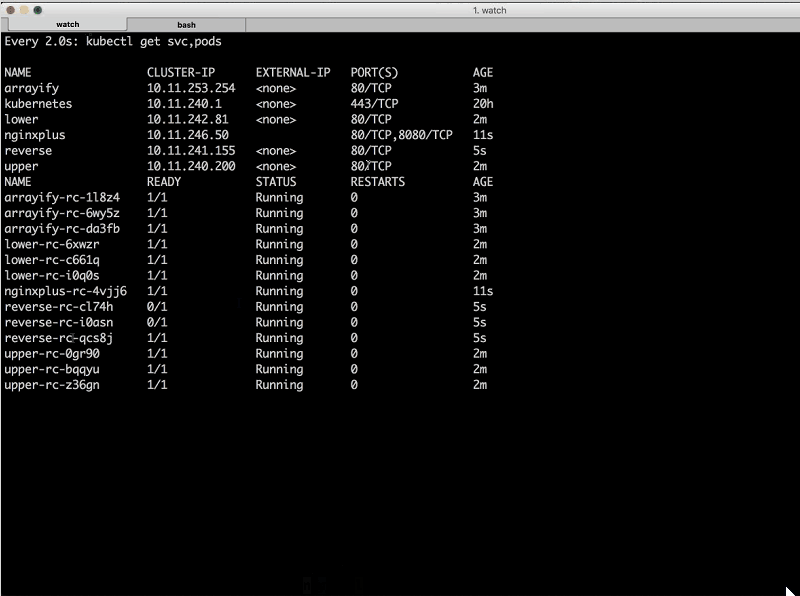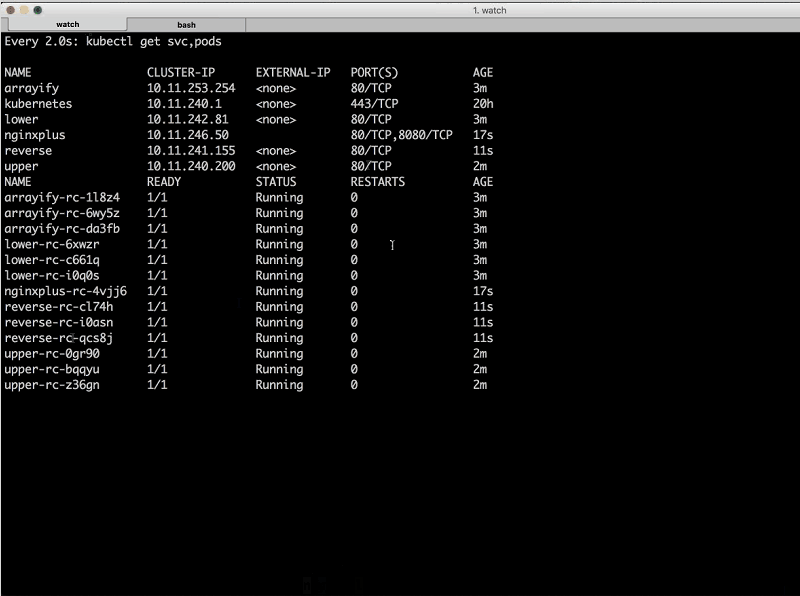
Sara: Now, we can deploy NGINX Plus, so I’m going to cd into the nginx directory and run make only-deploy….We can see that the service was just created, and soon we’ll get the external IP address. And we have reverse running now as well.
Sandeep: Now we have all four of our microservices, and like Sara said, we just deployed the nginxplus replication controller and [single associated] service [instance].
And the thing to notice with the nginxplus service is that we have this thing called type: LoadBalancer. So, this will actually spin up a network load balancer on Google Cloud Platform.

And if we go back to our terminal, we can see that the external IP address for all the other services say <none>, but nginxplus has a blank. And in a few seconds, the network load balancer in Google Cloud Platform will spin up an external IP address for us automatically.
We’re going to give that a few seconds … and there it is!
Sara: We’ll be routing all of our traffic through this external load balancer. So, I’m going to go ahead and open that up in a browser.
Sandeep: The cool thing is that one IP address can hit all four of our microservices.

Sara: Now I can see that NGINX is running and it’s serving up our index.html file.
Now we can try out our different services.
First, I’ll try out arrayify. I type /arrayify, pass it a test string. Now we can see that it did indeed arrayify our string.
Let’s check out all the different services. We’ve got reverse, let’s reverse our string. And then we have upper and then we’ll try out lower with an uppercase string.
So, we can see that all of our services are running. [The tests of the four services do not appear in the screenshot.]
Demo – NGINX Plus Live Activity Monitoring Dashboard
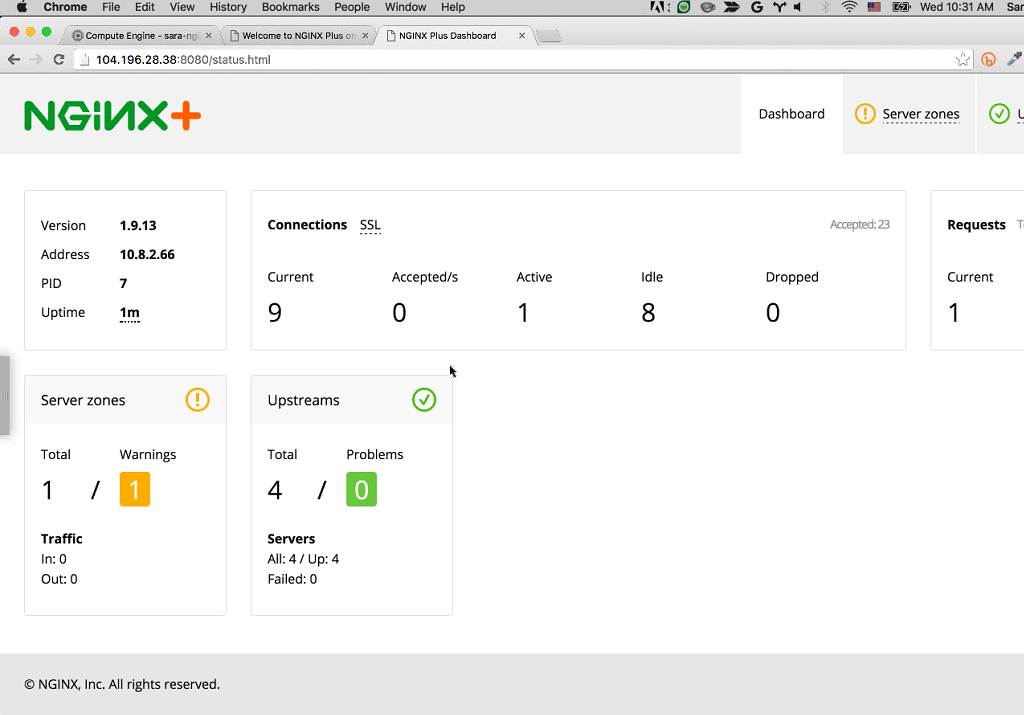
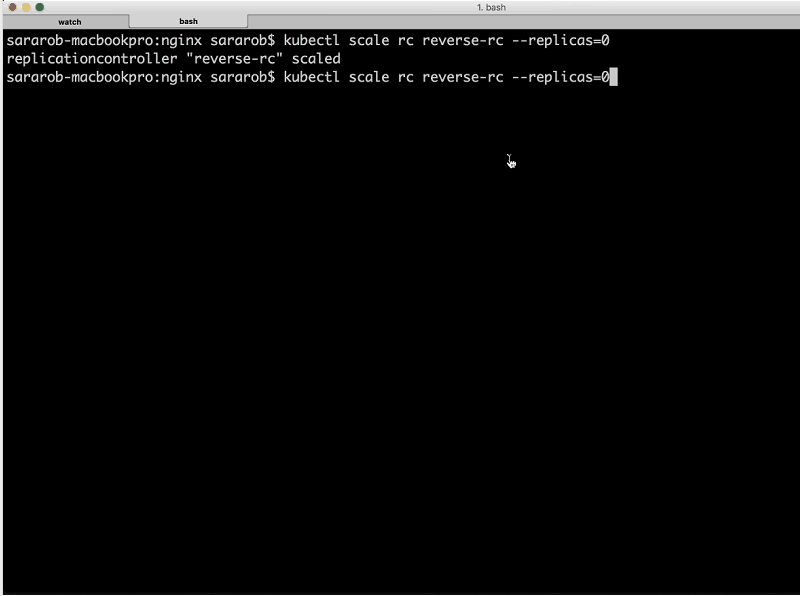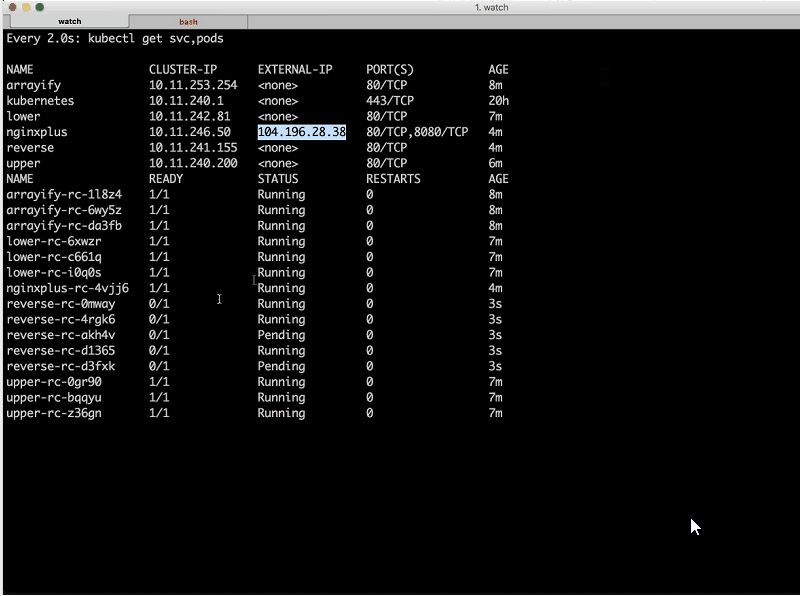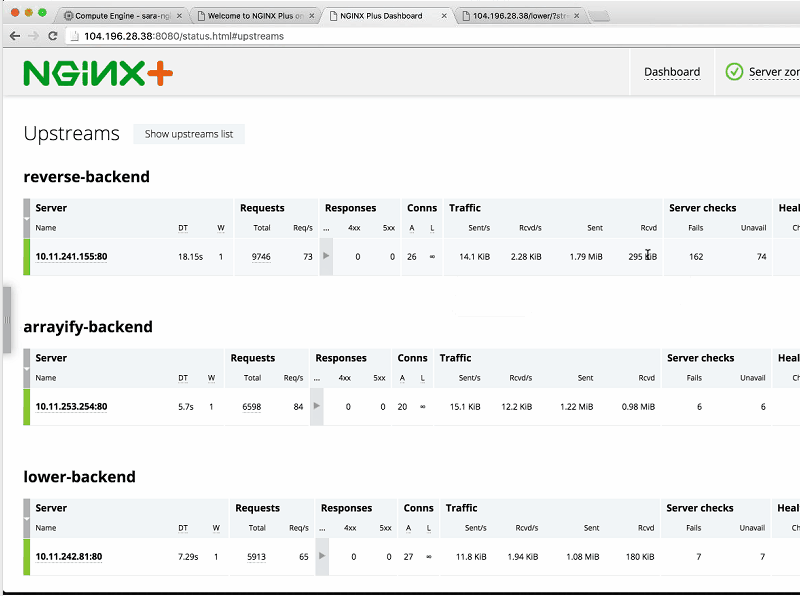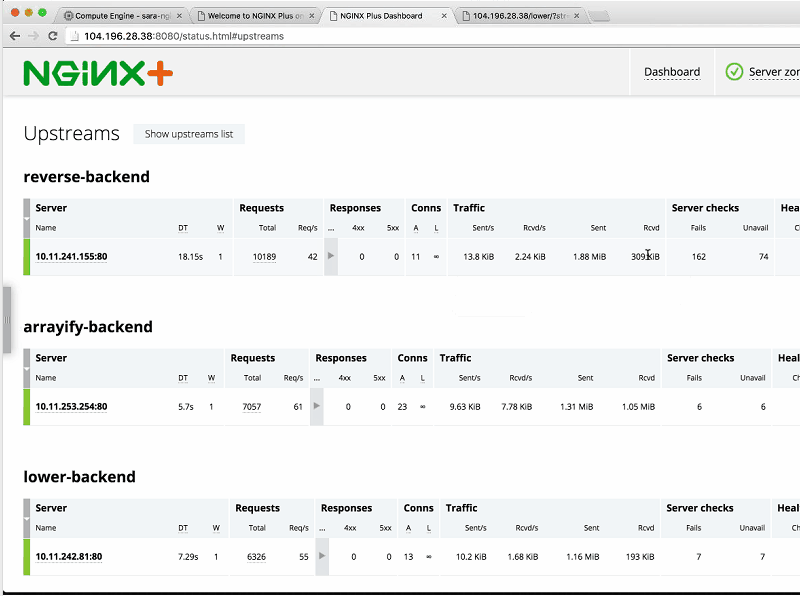
The next thing we want to take a look at is the NGINX Plus status page which Sandeep mentioned. This is at status.html on port 8080 and will give us a real‑time dashboard of all the requests we’re getting. Now Sandeep is going to generate a lot of load on our backends.
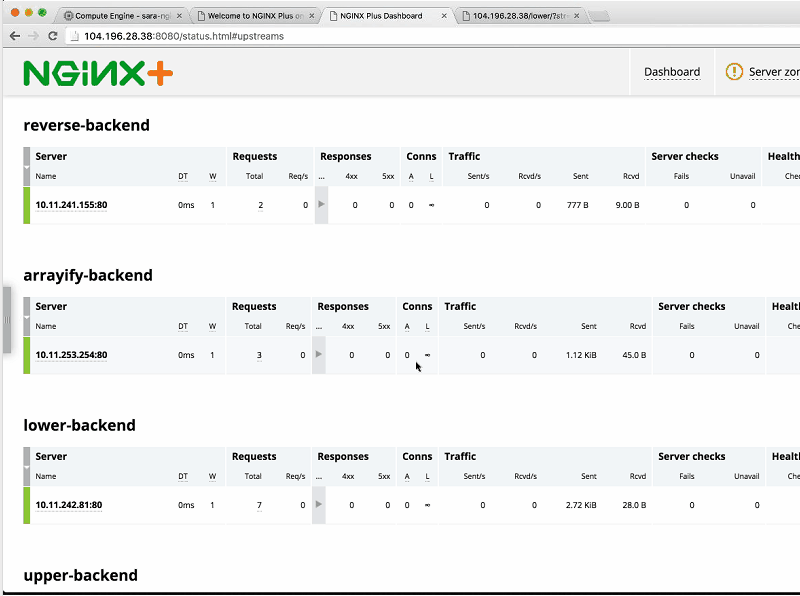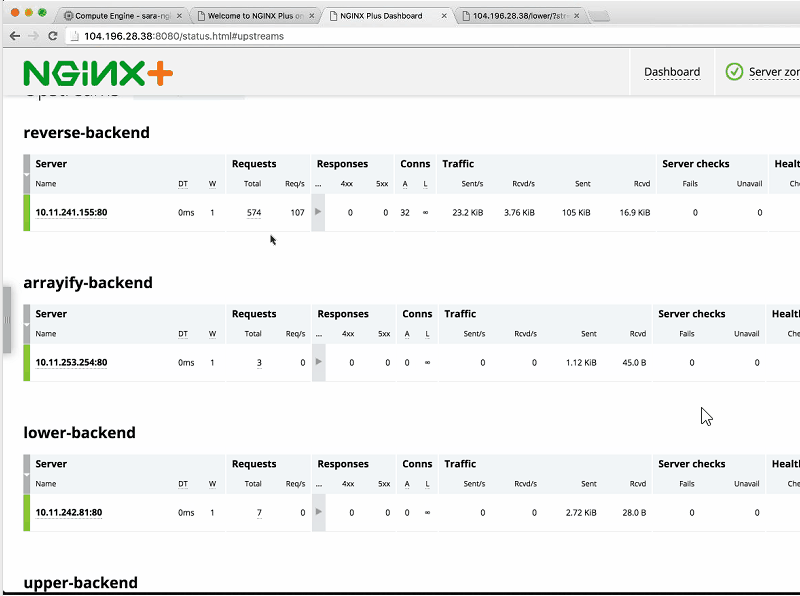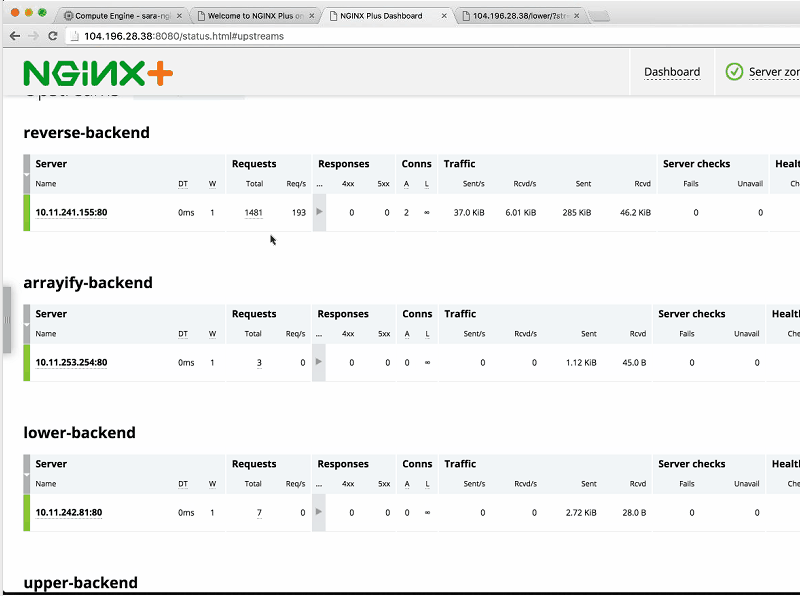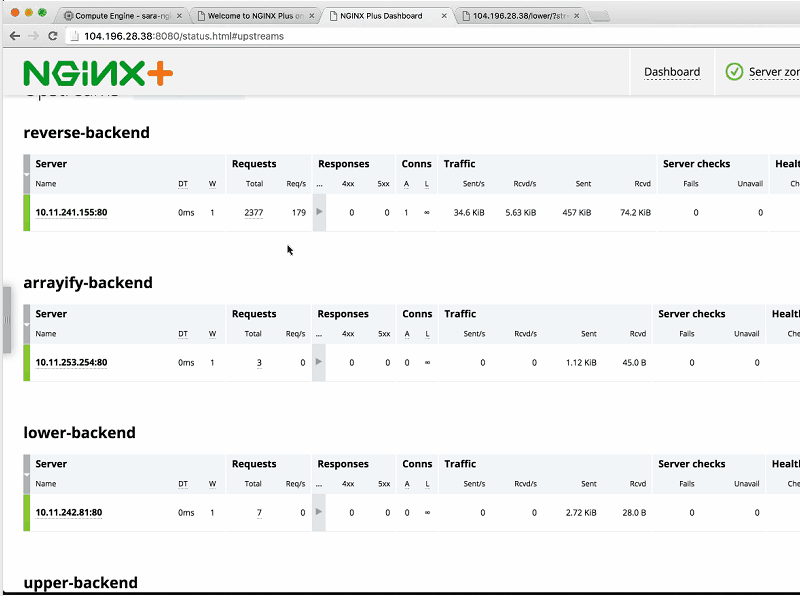
Sandeep: I’m going to generate a lot of load on reverse-backend. You can see that all of a sudden, the load spikes up [visible in the Requests column that the arrow cursor is pointing at in the screenshot] and NGINX handles this quite well. You can see it all happening in real time on the NGINX Plus dashboard.
Now I’m going to generate a bunch of load on the backends.
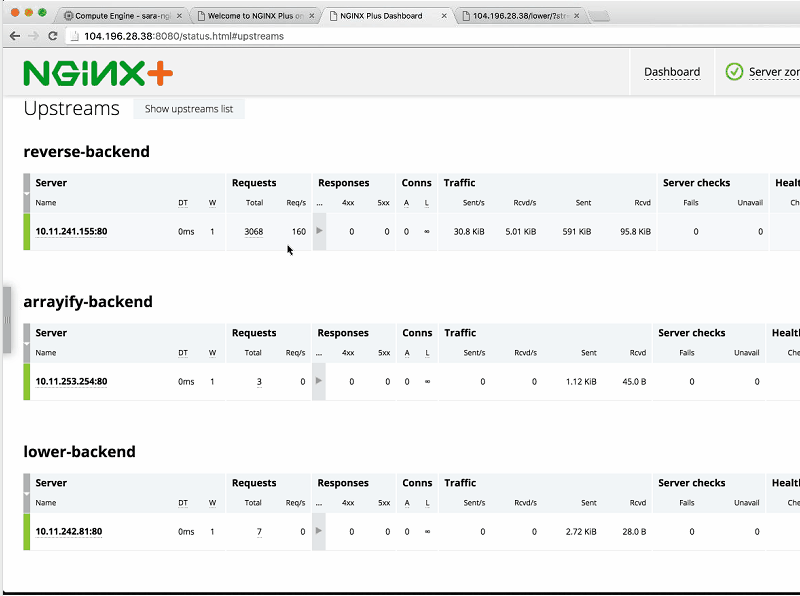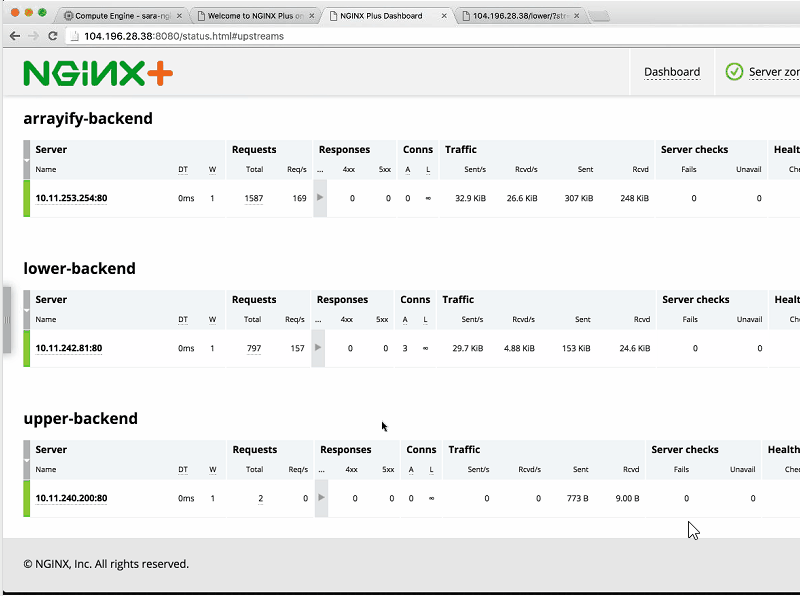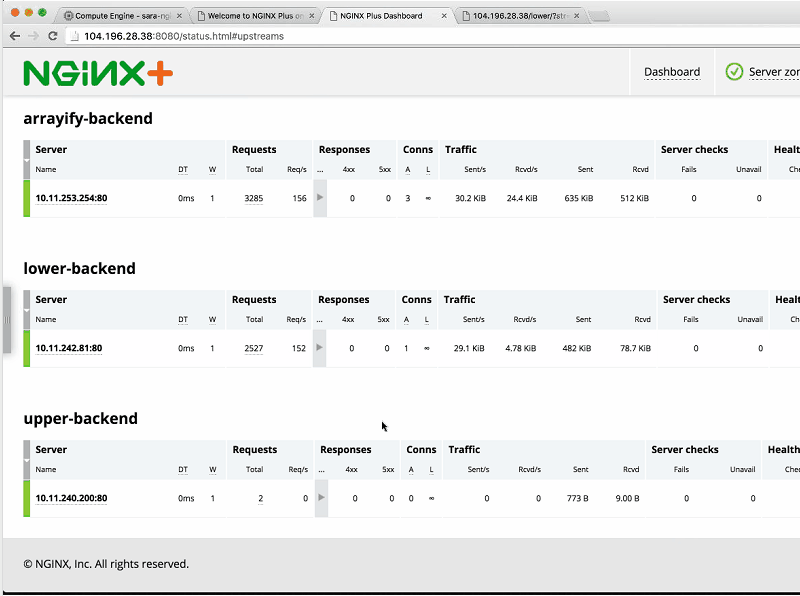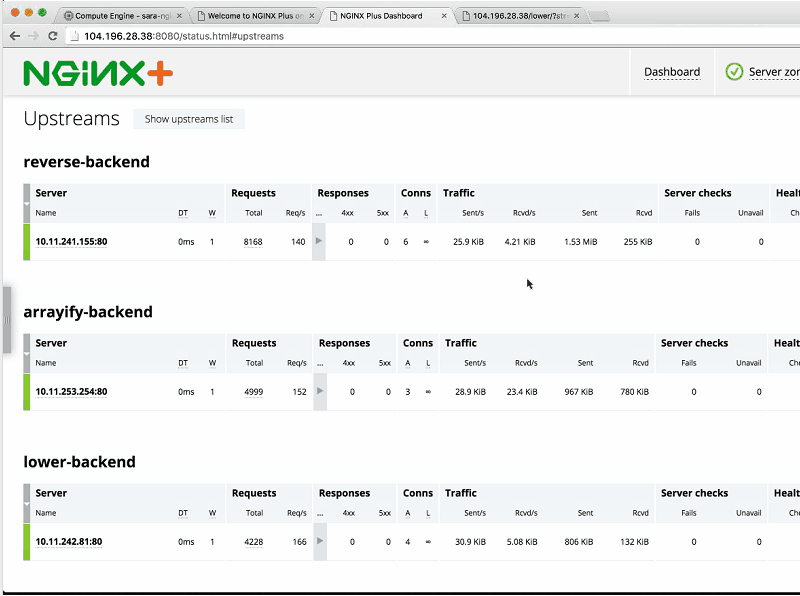
Sara: Now, we can see the number of requests increasing as Sandeep continues to generate load on all the different backends.
Sandeep: I generated load on three backends – all but upper-backend – just to show you that you don’t have to hit all at the same rate.
Demo – Scaling Services Up and Down
Now what we’re going to do is show you what happens if we start removing the backend services completely.
Sara: We’re going to set the number of replicas for reverse to zero. So, we’ll run:
kubectl scale rc reverse-rc --replicas=0Now, if we go back here [the second terminal window] and we should see that it’s terminating those [the value in the STATUS column changes to Terminating for the three instances of reverse.]
And if we take a look at our status page …
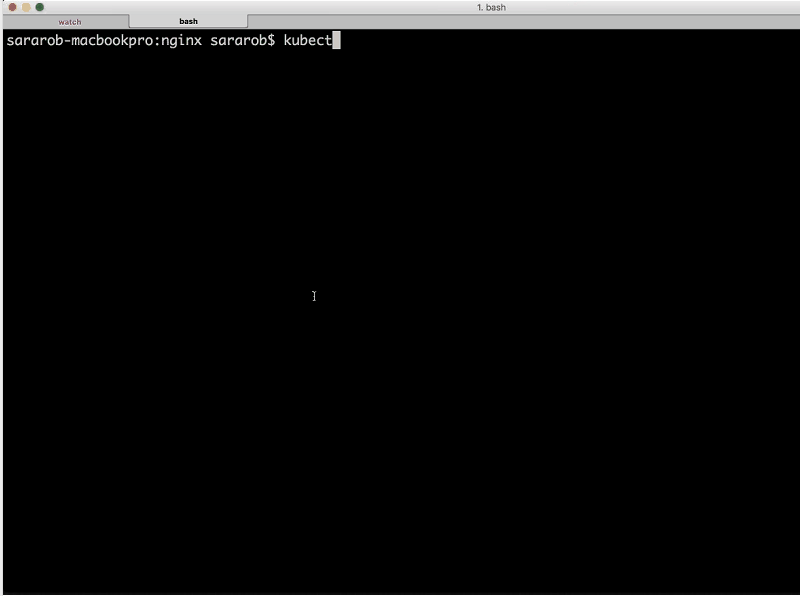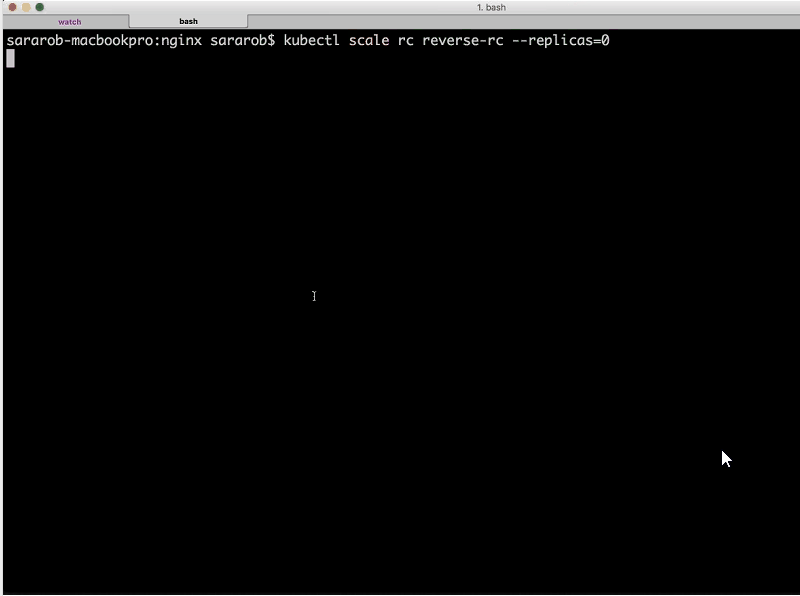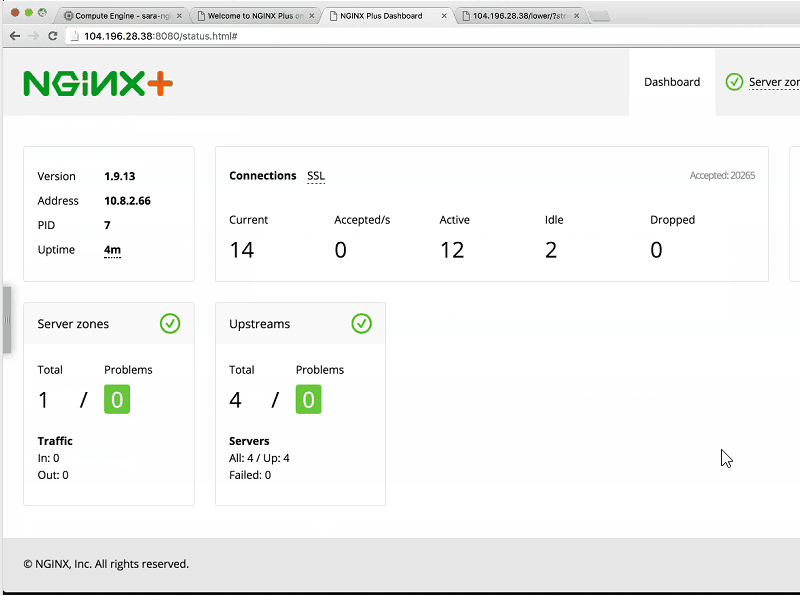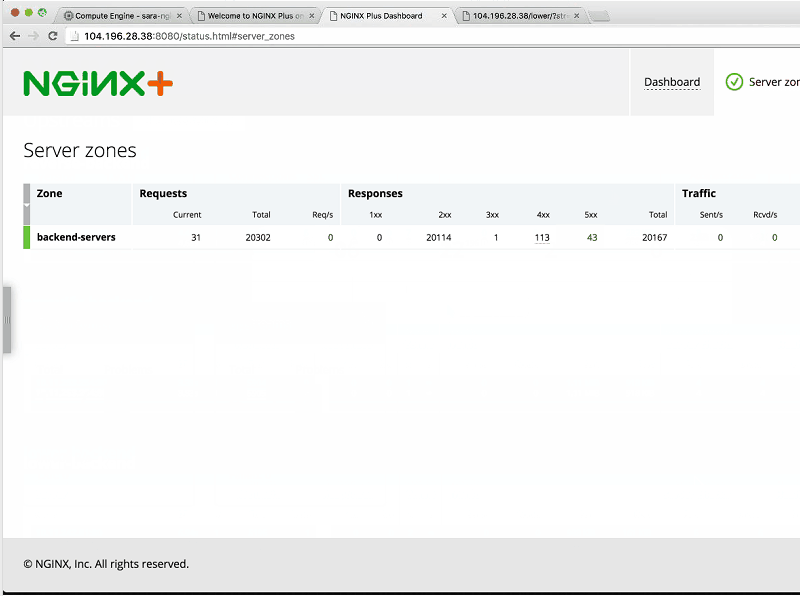
Sandeep: You can see that the server checks are failing, the server zones are giving alerts [the backend-servers zone on the Server zones tab of the dashboard]. So yes, things are bad.
Of courser, you should not scale your production services to zero. That’s always a bad idea, but NGINX Plus detects that almost immediately and starts giving us warnings.
So now, we can always scale it back up to three or even four, right? Let’s just scale it to five, why not?
Sandeep: Boom, no more failures. And so, this makes it super easy to monitor, make sure, scale, all that kind of stuff, and we didn’t have to ssh into a single machine. All this was done using the Kubernetes API to deploy Docker containers and things like that.
This makes managing all of these microservices a lot easier because you’re not manually doing all of these steps. You’re using an API and a cluster manager to do it for you.
31:33 Resources from Google
Sara: Awesome. Now, we’re going to go back to the slides.
We’ve got some resources we want to just share with you if you want to build something similar, or learn more about NGINX Plus or Kubernetes.
If you go to bit.ly/nginx-launcher, you can learn more about launching NGINX Plus using Cloud Launcher [now replaced by the Google Cloud Platform Marketplace] to run it on Google Compute Engine.
There’s a great post [on the NGINX blog] about load balancing Kubernetes on NGINX which we referenced a lot while we’re doing this demo.
Kubernetes also has great documentation and information available. If you’re new to it, you can find that and some Getting Started guides at kubernetes.io.
We also have a Google Cloud Platform podcast which has a bunch of episodes on Kubernetes. So definitely check that out, give it a listen if you want to learn more about other Google Cloud Platform products. We have a bonus link for you as well.
Sandeep: Yes. I did a 360‑degree tour on YouTube of a Google data center. So, you just put on a Google Cardboard or an Oculus Rift or something like that, and it really feels like you’re inside the data center. We don’t really allow people to come in inside our data center, so it’s a pretty cool thing. Definitely go check it out if you have five minutes to spare.
32:46 Resources from NGINX

Floyd Smith: Yes. I’ll talk about some of our resources in NGINX and then I have a couple of questions for my co‑presenters here.
There’s a seven part series on microservices, and actually the most enlightening one for me, or the best entry point was the seventh post which tells you how to refactor a monolith into microservices.
If you’re already familiar with monolithic architecture as most of us are, I highly recommend that as a starting point. If any of the language we’re using today is news to you, if you either haven’t heard it before or you’ve heard it but you haven’t actually used some of these concepts, this seven‑part series will really take you into depth on how to make your microservices work for large production application.
We’ve got a post on deploying NGINX and NGINX Plus with Docker, which has been an extremely popular thing to do. Those two things go really well together, and as soon as you have more than one container, you’re going to start thinking about managing them and that’s where Kubernetes comes in.
We have Make your Containers Production‑Ready, more towards the same concept, and we have some internal expertise. It’s really nice. We also have a great post on using NGINX Plus for Layer 7 and Layer7nbsp;4 load balancing with Kubernetes.
In addition, we have webinars on Microservices and Docker, a great question and answer session, and Kubernetes at the edge of your deployment with NGINX Plus.
35:25 Questions and Answers
Q: How do you guys engage with developer users of GCP? How do people interact with you and what do you find yourself doing for them?
Sandeep: Online, I think one easy way is through Slack. We have a Slack channel at bit.ly/gcp-slack. You’re welcome to join.
We have a ton of different channels all the way from App Engine, Kubernetes, Ruby, Node.js, Go, covering the whole spectrum of everything we have at Google Cloud. And there’s a ton of people in there, Googlers and non‑Googlers alike who really love answering questions and just talking about technology. So, it’s a really great place for online collaboration.
Sara: Yes. Slack’s probably the best way to get in touch with us. There’s usually someone on our team hanging in there at any point in time.
You can also follow Google Cloud on Twitter. All the developer advocates are pretty active on Twitter so we can answer your questions about different Google Cloud products on there as well.
Q: What problems does NGINX Plus solve for users that would be challenging for them without it?
Sandeep: In Google Cloud, we do have network and HTTP/HTTPS load balancing, but again it’s not as sophisticated as something like NGINX Plus. The power that NGINX Plus gives you is a little bit higher than the vanilla tools that we give you.
In Google Cloud, we do have globally available Layer 7 load balancing. We create one IP address and use global load balancing, but we don’t have all of the nitty‑gritty features like geolocation, all those things Floyd showed in NGINX Plus, those more advanced features.
So, the basics are covered by the platform, but something like NGINX Plus really gives that fully featured tool set that you need to run a very sophisticated application.
Q: What problems does Kubernetes then solve for people?
Sandeep: Kubernetes really solves the problem of managing Docker containers.
When you move from a monolith to microservices, all you’re really doing is moving the complexity from your code into your operations.
But I think – because we automate operations so much better than code – until AI comes along that will write code for us, managing code will be a very complicated process, while managing operations has been automated over the years to the point where we can do it with simple APIs.
Kubernetes lets you automate that operation. The complexity is still there, but because you’re automating it, it’s hidden from you. That’s what Kubernetes really allows you to do, is automate your operations and make your microservices deployment way easier.
Floyd: Yes. Part of the advantage too for both of these tools is that if you’re using Kubernetes and you’re using NGINX Plus together, you’re gaining intellectual capital that is easy redeployable across different cloud platforms and bare metal.
Q: Should you use multiple instances of NGINX Plus to ensure availability?
Floyd: Yes. We always deploy NGINX Plus in pairs to back each other up. That also provides a certain amount of scalability, but of course you want to always have the ability to get twice as many instances as you’re actually using for complete high availability. I would mention that in a microservices world, we’re finding that there’s a lot of resilience, once you architect things properly.
Sandeep: In our demo, we just had one replica but Sara’s going to share her screen again and show you how easy it is to just deploy two. Literally, it’s just one command.
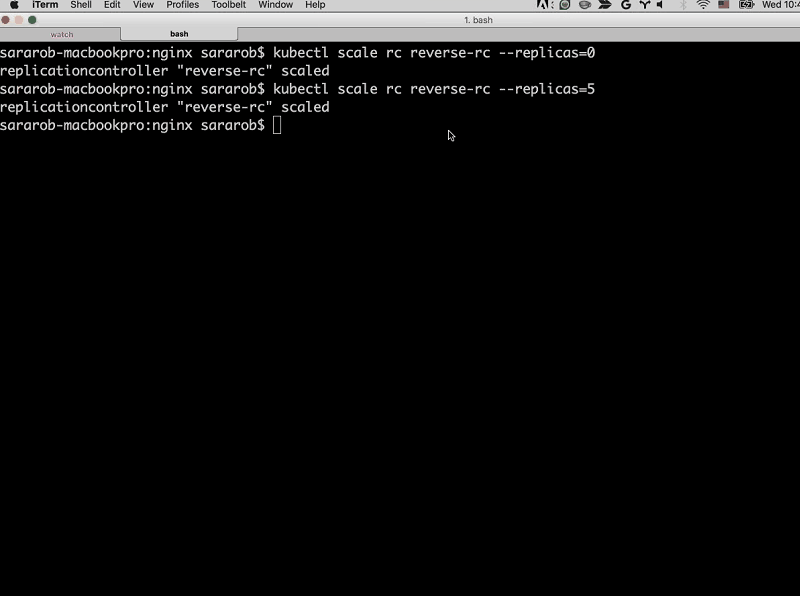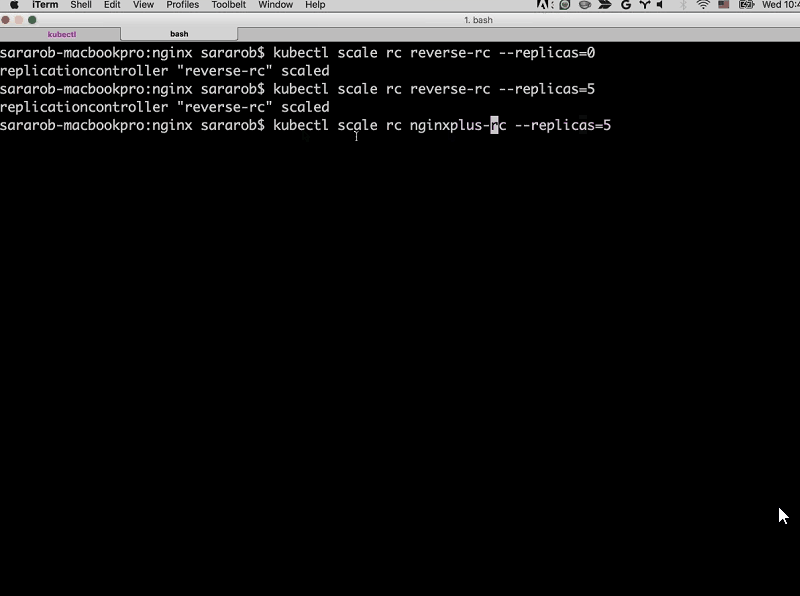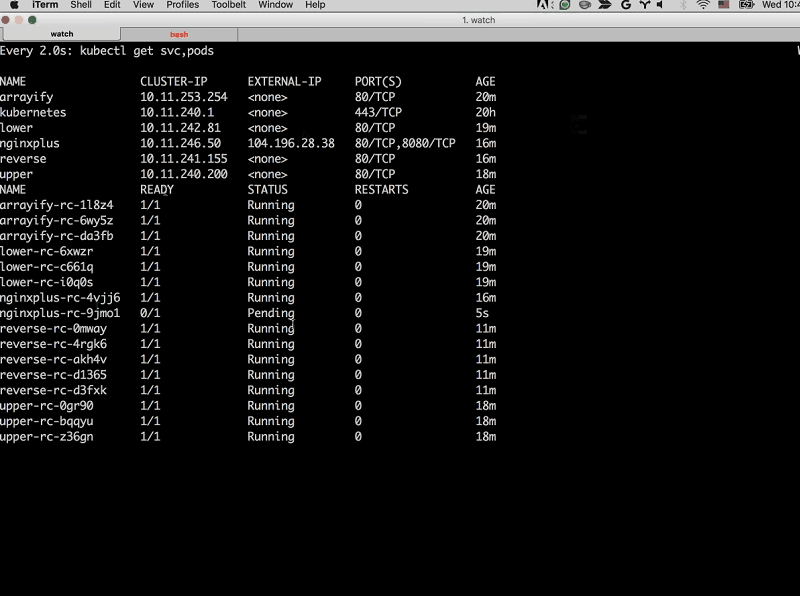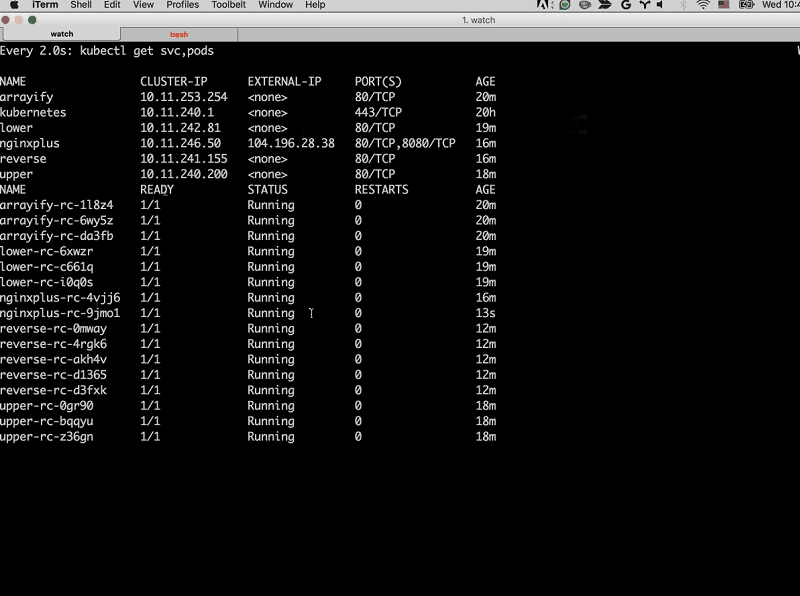
Sara: I’m going to do the same thing with my nginxplus replication controller, so instead of reverse it’s going to be nginxplus and we’ll say replica=2. And now, if we go to watch over here, we should see another instance of NGINX Plus.
Sandeep: Boom, and that’s how easy it was to run two instances. And the cool thing about Kubernetes is that if one of those [NGINX Plus instances] goes down, it’ll actually spin it up again automatically without you having to do anything.
Q: Would one use Kubernetes along with other orchestration tools such as Puppet and Chef?
Sandeep: Definitely. People use Puppet and Chef to bootstrap Kubernetes clusters. I think that’s a very typical use case.


