

The Internet of Things (IoT) is a growing segment of the technology market today. NGINX and NGINX Plus are often at the core of IoT deployments because of their small footprint, high performance, and ease of embedding into various devices. We see NGINX and NGINX Plus installed both on the server side and on the device side very often.
IoT installations can use a variety of popular protocols, including HTTP, HTTP/2, MQTT, and CoAP. We’ve covered the use of our products with HTTP protocols in many blog posts, and MQTT use cases in two recent posts:
- NGINX Plus for the IoT: Load Balancing MQTT
- NGINX Plus for the IoT: Encrypting and Authenticating MQTT Traffic
But NGINX and NGINX Plus are equally suited for special‑purpose protocols such as the Hyper Text Coffee Pot Control Protocol (HTCPCP). This is the first of series of blog posts where we plan to cover development, deployment, and monitoring of HTCPCP applications.
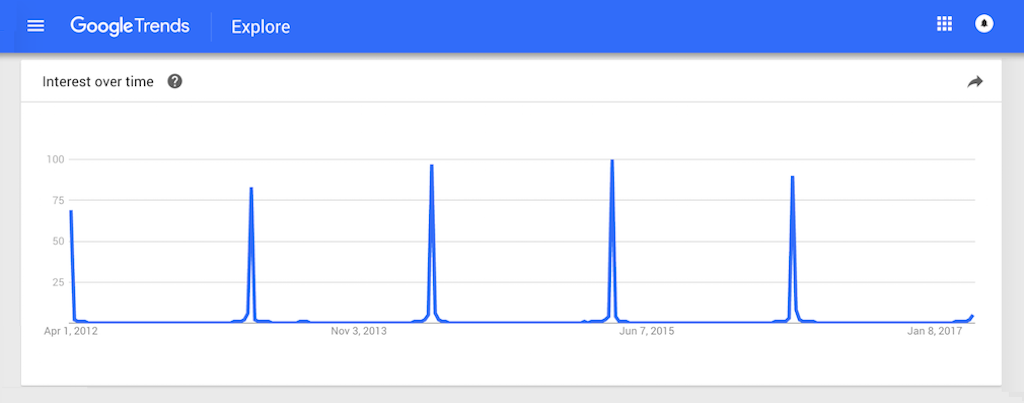
Installation of HTCPCP‑enabled devices is steadily growing every year, with a seasonal spike at the beginning of April.
Reference Architecture
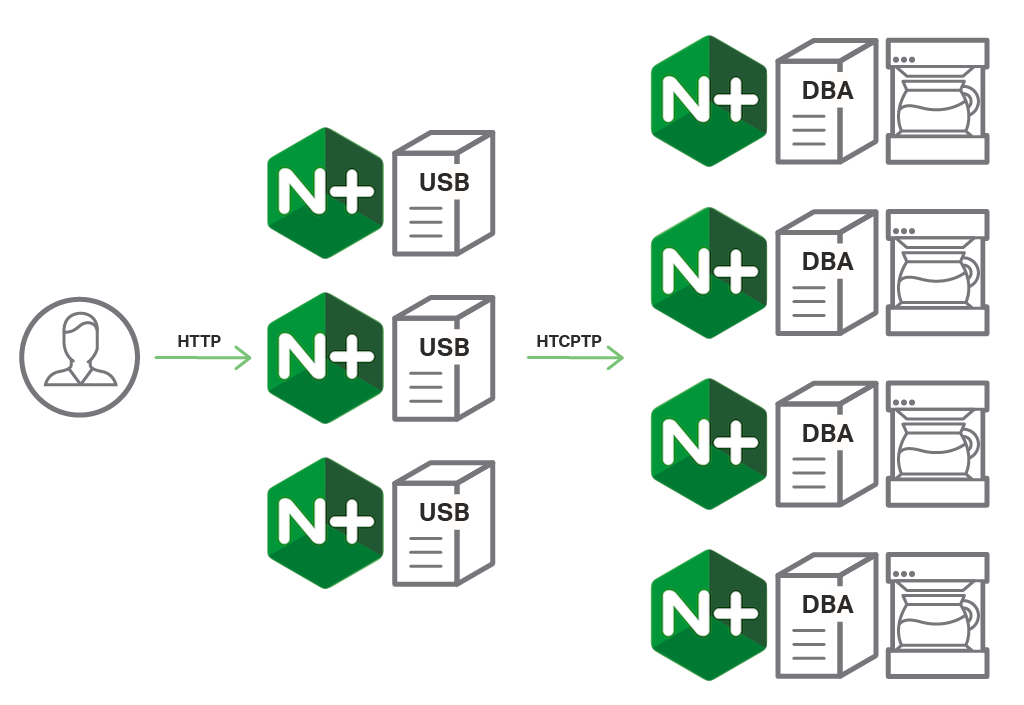
HTCPCP architecture in a large‑scale installation is different from a standard web application. In a standard web application, we usually see a lightweight client side communicating with a heavier set of backend applications. The architecture of HTCPCP applications is fundamentally different. In this case, the HTCPCP server is designed to work on the device (namely, a connected coffee pot) and the clients connect to these machines using either special command‑line clients (modified curl commands) or a proxy infrastructure.
The microservices approach fits HTCPCP deployments very well. Service discovery, load balancing, cloud deployments, and API gateways are all applicable here.
The main parts of a microservices architecture for HTCPCP are DBAs, DPI, and USB.
DBAs
The Distributed Backend Applications (DBAs) are usually deployed on the coffee‑making devices, and can be implemented in various languages and application platforms. There are multiple commercial and open source examples, including:
- An implementation on Python for Raspberry Pi
(https://github.com/HyperTextCoffeePot/HyperTextCoffeePot) - An implementation in JavaScript for Node.JS
(https://github.com/stephen/node-htcpcp) - A high‑performance implementation in C
(https://github.com/madmaze/HTCPCP)
DPI
The Distributed Proxy Infrastructure (DPI) in our HTCPCP deployment is NGINX or NGINX Plus instances embedded in the IoT devices. DBAs usually don’t require a DPI in a smaller installation. In a large enterprise, however, the following features are crucial for reliable service in the HTCPCP deployment:
- Rate limiting and overflow protection
- Health checks
- Traffic monitoring and logging
- Traffic encryption and security controls
- Authentication
NGINX Plus is the most popular DPI in enterprise‑class HTCPCP deployments.
USB
In a development system or small‑scale installation (up to five coffee machines), the clients can connect to a DPI instance or even directly to the DBA. In a larger enterprises, however, we usually see a Unified Scalable Backend (USB) developed and deployed either on premises or as a scalable cloud service. The USBs usually perform functions like:
- Coffee machine discovery, which is similar to service discovery in conventional microservices (read more about service discovery on our blog)
- Protocol conversion from HTTP to HTCPCP
- Web interface
- End‑user authentication and access control
Most highly loaded web applications today are using NGINX and NGINX Plus as a load balancer, reverse proxy, and cache, and HTCPCP USB is no exception.
Monitoring HTCPCP Applications
A large‑scale installation of HTCPCP requires a set of monitoring tools that have to be more sophisticated than a generic monitoring system for a simple microservice. In an HTCPCP deployment we see more protocol conversions and more different types of devices where the monitoring agent needs to be deployed. In addition, organizations impose tight SLAs for preparation of a cup of coffee, because this directly impacts productivity of their employees.
The Infrastructure Department for IoT (IDIoT) at every company is constantly looking for ways to effectively monitor HTCPCP installations.
At NGINX, Inc. we’ve developed NGINX Amplify, the monitoring and configuration assistance system that suits an HTCPCP deployment just as well as a complex HTTP deployment.
To start using NGINX Amplify in your infrastructure, you need to install the NGINX Amplify Agent together with your NGINX instance on all DPIs and USBs. The beauty of our solution starts with the fact that it’s absolutely agnostic to the underlying architecture. While USBs might be located on large enterprise servers or containers in the cloud, you usually own the hardware that runs the DBAs and DPIs. NGINX and NGINX Amplify fit equally well in the cloud and on your hardware.
In the screenshot below you can see a small portion of NGINX Inc.’s own HTCPCP installation, with multiple machines connected through various instances of NGINX and NGINX Plus.
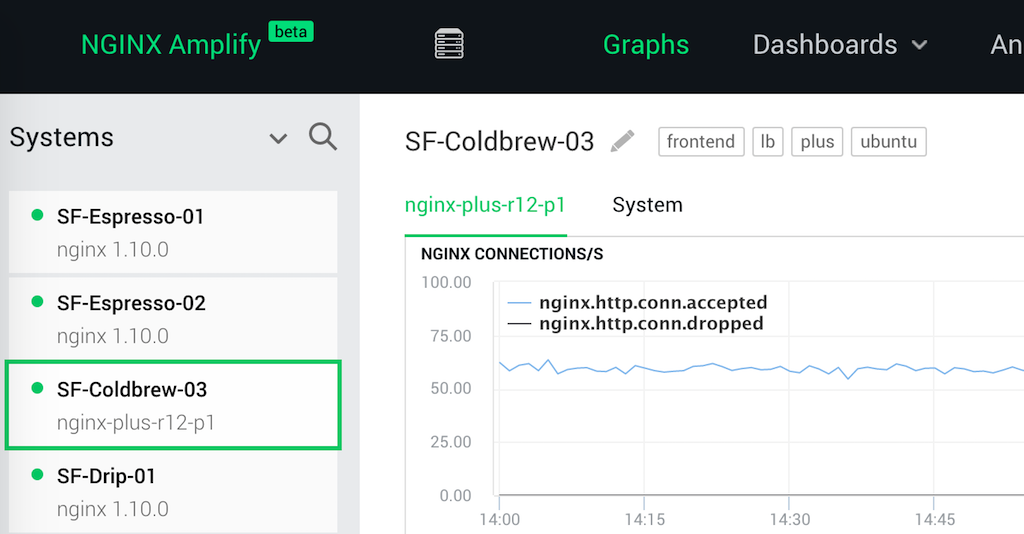
NGINX DevOps engineers are dedicated to providing infrastructure that is resilient to any issues with electricity, the network, or grind inconsistency. In our recent blog post we described how the advanced graphs and dashboards help our own infrastructure team to maintain the highest standards of uptime and reliability.
In addition to standard HTTP monitoring, you can use NGINX Amplify to monitor the specific issues that arise only in an HTCPCP deployment.
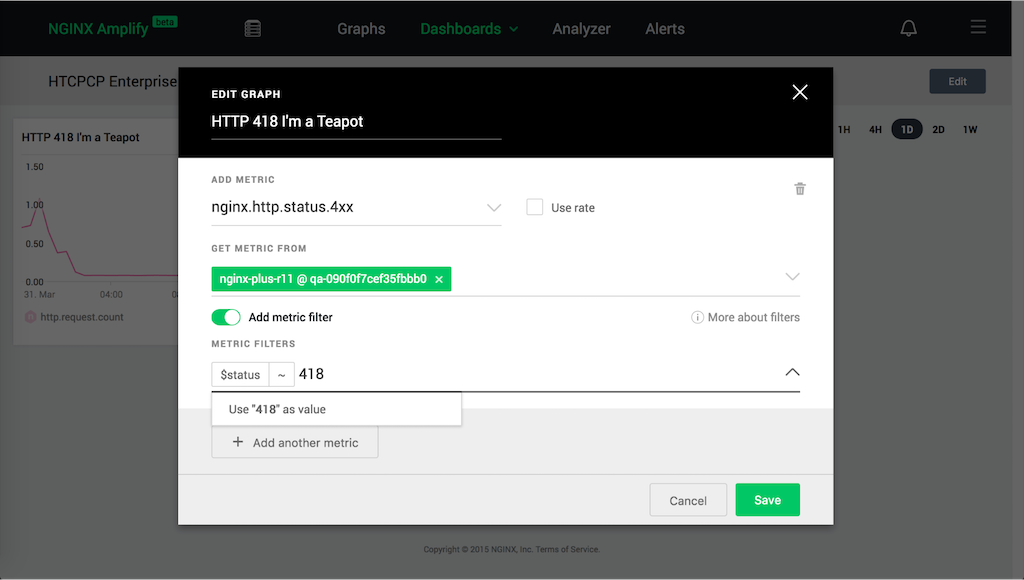
NGINX and NGINX Plus produce logs which can be configured to report a lot of internal data. The NGINX Amplify Agent can read those logs, or receive them using the syslog interface. As an example, let’s monitor one of the most devastating status codes that can affect your HTCPCP deployment: 418 I'm a Teapot. This status code is returned if the type of your IoT device is mismatched: the DBA produces tea, but the USB requested a coffee drink.
Fortunately, even in a caffeine‑deprived state it’s easy to create the appropriate NGINX Amplify filter:
- Create a new graph in your custom dashboard
- Select the metric
nginx.http.status.4xx - Create a filter for
$status~418, optionally with additional criteria
Once the filtered graph is created, the agents start to apply this filter to the logs, and report the resulting metrics to NGINX Amplfiy Cloud.
The following screenshot shows the daily rate of 418 errors across a large corporate office in Europe.
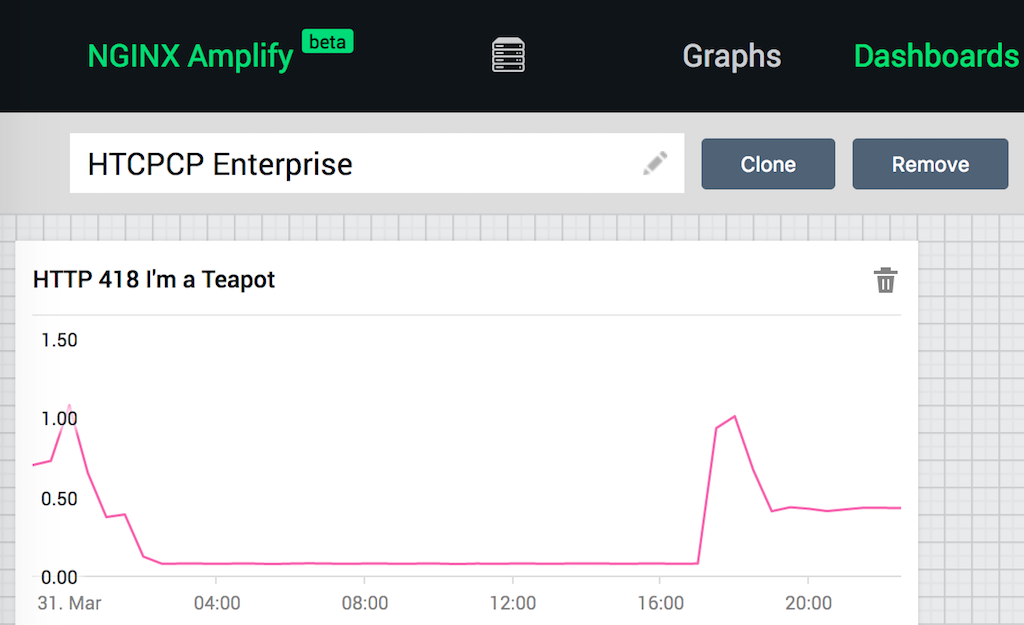
Learn more about NGINX Amplify filters and dashboards on our blog.
Conclusion
NGINX, NGINX Plus, and NGINX Amplify are the de facto standard for microservices applications and IoT deployments. If your deployment involves the use of HTCPCP protocol at enterprise scale, you need tools that are up to the task. As always, you can count on NGINX, NGINX Plus, and NGINX Amplify.
Get your HTCPCP deployment perking with NGINX Plus – start your free 30-day trial today or contact us to discuss your caffeination schedule. And since you’re wide awake anyway, you’ll want to keep a close eye on your HTCPCP apps with NGINX Amplify – sign up now.


