We’re happy to announce the availability of NGINX Plus Release 31 (R31). Based on NGINX Open Source, NGINX Plus is the only all-in-one software web server, load balancer, reverse proxy, content cache, and API gateway.
New and enhanced features in NGINX Plus R31 include:
- Native NGINX usage reporting – NGINX Plus now has native support for reporting on NGINX deployments across your organization, enabling a consolidated view of your NGINX infrastructure in NGINX Instance Manager. This feature enables enhanced governance of NGINX instances for compliance purposes.
- Enhancements to SNI configuration – Previously, the server name that passed through Server Name Identification (SNI) used the proxy_ssl_name directive and was used by all the servers in the upstream group. NGINX Plus R31 enables this SNI to be set to a selected upstream server.
- Periodic task execution with NGINX JavaScript – NGINX JavaScript introduces the js_periodic directive to allow running content at periodic intervals. This enhancement eliminates the need to set up a cron job and can be configured to run on all or specific worker processes for optimal performance.
- A better NGINX startup experience – NGINX Plus R31 brings in improvements in the overall NGINX startup experience in cases where there are a high number of “locations” in the configuration.
- QUIC+HTTP/3 optimizations and improvements – NGINX Plus R31 adds many enhancements and performance optimizations to the QUIC implementation, including support for path maximum transmission unit (MTU) discovery, congestion control improvements, and the ability to reuse the cryptographic context across your entire QUIC session.
Rounding out the release are new features and bug fixes inherited from NGINX Open Source and updates to the NGINX JavaScript module.
Important Changes in Behavior
Note: If you are upgrading from a release other than NGINX Plus R30, be sure to check the Important Changes in Behavior section in previous announcement blogs for all releases between your current version and this one.
Deprecation of the OpenTracing Module
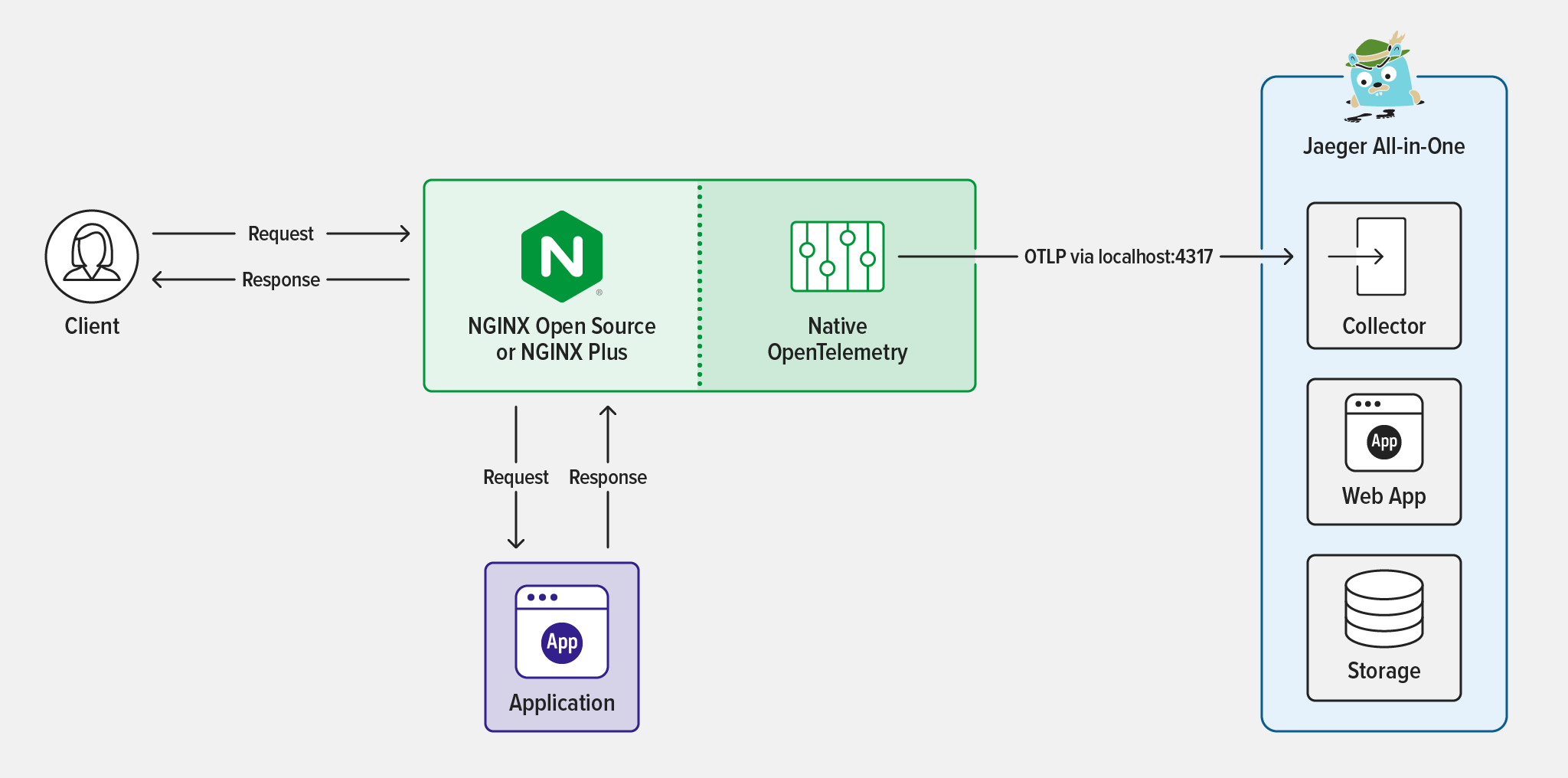
The OpenTracing module that was introduced in NGINX Plus R18 is now being deprecated. It is marked to be removed starting in the future release of NGINX Plus R34. The package will be made available with all NGINX Plus releases until then. It is strongly advised to use the OpenTelemetry module that was introduced in NGINX Plus R29.
Warning Message for Not Reporting NGINX Usage
NGINX Plus users are required to report their NGINX usage to F5 for compliance purposes. With the release of NGINX Plus R31, the ability to report your NGINX usage to NGINX Instance Manager is natively present and is enabled by default. A warning message is logged if the NGINX instance is not able to provide its usage information to NGINX Instance Manager for any reason.
Refer to the Native NGINX Usage Reporting section for details on how to configure this feature in your environment.
Changes to Platform Support
New operating systems supported:
Older operating systems removed:
- Alpine 3.15, which reached end-of-life (EOL) on Nov 1, 2023
Older operating systems deprecated and scheduled for removal in NGINX Plus R32:
- FreeBSD 12 which will reach EOL on Dec 31, 2023
New Features in Detail
Native NGINX Usage Reporting
NGINX Plus R31 introduces native communication with NGINX Instance Manager on your network to automate licensing compliance. If you participate in the F5 Flex Consumption Program, you will no longer need to manually track your NGINX Plus instances.
By default, NGINX Plus will attempt to discover NGINX Instance Manager on startup via a DNS lookup of the nginx-mgmt.local hostname. While the hostname is configurable, we suggest (for simplicity) to add an A record to your local DNS, associating the default hostname with the IP address of the system running NGINX Instance Manager. NGINX Plus will then establish a TLS connection to NGINX Instance Manager, reporting its version number, hostname, and unique identifier every thirty minutes.
For an added layer of security, we also suggest provisioning this connection with mTLS by using the optional mgmt configuration block. At a regular cadence, NGINX Instance Manager will then report the total usage of NGINX Plus instances to an F5 service.
You will see a warning message in your error log if NGINX Plus experiences any problems resolving the nginx-mgmt.local hostname or communicating with NGINX Instance Manager.
This is an example of an error message indicating that the NGINX Plus instance is unable to resolve nginx-mgmt.local:
2023/12/21 21:02:01 [warn] 3050#3050: usage report: host not found resolving endpoint "nginx-mgmt.local”
And here is an example of an error message indicating that the NGINX Plus instance is experiencing difficulties communicating with NGINX Instance Manager:
2023/12/21 21:02:01 [warn] 3184#3184: usage report: connection timed out
Customizing the mgmt Configuration Block Settings
If you prefer to fine tune how your NGINX Plus instance communicates with NGINX Instance Manager, you may opt to use the new mgmt configuration block and associated directives. Doing so allows you to define a custom resolver, use an IP address or alternate hostname to identify your NGINX Instance Manager system, specify TLS options, use mTLS for enhanced security, and specify other custom parameters.
The following is a sample custom configuration:
mgmt {
usage_report endpoint=instance-manager.local interval=30m;
resolver 192.168.0.2; # Sample internal DNS IP
uuid_file /var/lib/nginx/nginx.id;
ssl_protocols TLSv1.2 TLSv1.3;
ssl_ciphers DEFAULT;
ssl_certificate client.pem;
ssl_certificate_key client.key;
ssl_trusted_certificate trusted_ca_cert.crt;
ssl_verify on;
ssl_verify_depth 2;
}
For additional details on these directives, please see the product documentation.
For more information on downloading and installing NGINX Instance Manager, see the installation guide.
Note: If you are using an earlier version of NGINX Plus, you can still report your instances by following these instructions.
Enhancements to SNI Configuration
Prior to this release, NGINX Plus assumed that all servers in an upstream group were identical. This means they needed to be able to answer the same requests, respond to the same SNI name (when proxy_ssl_server_name is used), and return SSL certificates matching the same name.
However, scenarios exist where this behavior is not sufficient. For ex. if multiple virtual servers are shared behind an upstream server and need to be distinguished by a different SNI and/or host header to route requests to specific resources. It’s also possible that the same certificate can’t be used on all servers in the upstream group or there are limitations to put upstream servers into separate upstream groups.
NGINX Plus R31 introduces support for SNI to be configured per upstream server. The variable $upstream_last_server_name refers to the name of the selected upstream server, which can then be passed to the proxied server using the proxy_ssl_server_name and proxy_ssl_name directives.
Here is how you set proxy_ssl_server_name to on, enabling a server name to pass through SNI:
proxy_ssl_server_name on;
And this is how to pass the selected upstream server name using proxy_ssl_name:
proxy_ssl_name $upstream_last_server_name;
Periodic Task Execution with NGINX JavaScript
NGINX JavaScript v0.8.1 introduced a new directive js_periodic that is available in both the http and stream contexts. This directive allows specifying a JavaScript content handler to run at regular intervals. This is useful in cases where custom code needs to run at periodic intervals and might require access to NGINX variables. The content handler receives a session object as an argument and also has access to global objects.
By default, the content handler runs on worker process 0, but it can be configured to run on specific or all worker processes.
This directive is available in the location context:
example.conf:
location @periodics {
# to be run at 15 minute intervals in worker processes 1 and 3
js_periodic main.handler interval=900s worker_affinity=0101;
resolver 10.0.0.1;
js_fetch_trusted_certificate /path/to/certificate.pem;
}
example.js:
async function handler(s) {
let reply = await ngx.fetch('https://nginx.org/en/docs/njs/');
let body = await reply.text();
ngx.log(ngx.INFO, body);
}
For syntax and configuration details, please refer to the NGINX JavaScript docs.
A Better NGINX Startup Experience
In scenarios where an NGINX configuration contains a high number of “locations,” your NGINX startup time may take a considerable amount of time. In many cases, this might not be acceptable. The root issue exists in the sorting algorithm that is used to sort the list of locations.
NGINX R31 introduces an enhancement that swaps out the existing sorting algorithm from insertion sort, which has a time complexity of O(n2), to merge sort with a time complexity of O(n*log n).
In a test configuration with 20,000 locations, it was observed that the total startup time was reduced from 8 seconds to 0.9 seconds after this update.
QUIC+HTTP/3 Optimizations and Improvements
NGINX Plus R31 introduces several enhancements and performance optimizations to the QUIC+HTTP/3 implementation, such as:
- Path maximum transmission unit (MTU) discovery when using QUIC+HTTP/3 – Path MTU is a measurement in bytes of the largest size frame or data packet that can be transmitted across a network. Prior to this change, the QUIC implementation used a path MTU of 1200 bytes for all datagrams. NGINX Plus now has support to discover the path MTU size, which is then used for all outgoing datagrams.
- Reuse cryptographic context across the entire QUIC session – This optimization relates to the encryption and decryption behavior of QUIC packets. Previously, a separate cryptographic context was created for each encryption or decryption operation. Now, the same context gets used across the whole QUIC session, resulting in better performance.
Additional performance optimizations include reducing potential delays when sending acknowledgement packets, putting acknowledgement (ACK) frames in the front of the queue to reduce frame retransmissions and delays in delivery of ACK frames, and improvements to the congestion control behavior in Generic Segmentation Offload (GSO) mode.
Other Enhancements and Bug Fixes in NGINX Plus R31
Additional mgmt Module
In NGINX Plus R31, ngx_mgmt_module enables you to report NGINX usage information to NGINX Instance Manager. This information includes the NGINX hostname, NGINX version, and a unique instance identifier.
The module provides several directives to fine tune how your NGINX instance communicates with NGINX Instance Manager. For a complete list of available directives and configuration options, refer to the NGINX Docs.
Bug Fixes in the MQTT Module
Message Queuing Telemetry Transport (MQTT) support was introduced in NGINX Plus R29 and this release contains a few bug fixes for issues observed in the MQTT module.
One important fix addresses an issue of CONNECT messages being rejected when a password was not provided. Previously, we unconditionally expected that the username field would be followed by password. There are, however, special cases in the MQTT specification – such as anonymous authentication – where providing a password is not mandatory. The fix conditionally checks if the password is expected or not by looking at the cflags field of the packet. If the flag is not set, it implies that the password is not mandatory.
Another bug fix stops the parsing of MQTT CONNECT messages when the message length is less than the number of bytes received.
HTTP/3 server_tokens support with variables
NGINX Plus R31 adds support for missing server_tokens variables for HTTP/3 connections. The string field can be used to explicitly set the signature on error pages and the “Server” response header field value. If the string field is empty, it disables the emission of the “Server” field.
Changes Inherited from NGINX Open Source
NGINX Plus R31 is based on NGINX Open Source 1.25.3 and inherits functional changes, features, and bug fixes made since NGINX Plus R30 was released (in NGINX 1.25.2 and 1.25.3).
Features
- Path MTU discovery when using QUIC – Previously, a default size of 1200 MTU was used for all datagrams. As part of the QUIC+HTTP/3 improvements, we added support to discover the path MTU size which is then used for all outgoing datagrams.
- Performance optimizations in QUIC – NGINX mainline version 1.25.2 introduced optimizations in the QUIC implementation to reuse the cryptographic context for the entire QUIC session. This reduces delays in sending ACK packets and puts ACK frames in the front of the queue to lessen frame retransmissions and delays in delivery of ACK frames.
- Support for the
TLS_AES_128_CCM_SHA256 cipher suite when using HTTP/3 – This enhancement adds TLS_AES_128_CCM_SHA256 support to QUIC, which currently is the only cipher suite not supported by the NGINX QUIC implementation. It’s disabled by default in OpenSSL and can be enabled with this directive: ssl_conf_command Ciphersuites TLS_AES_128_CCM_SHA256;
- Provide
nginx appName while loading OpenSSL configs – When using the OPENSSL_init_ssl() interface, instead of checking OPENSSL_VERSION_NUMBER, NGINX now tests for OPENSSL_INIT_LOAD_CONFIG to be defined and true. This ensures that the interface is not used with BoringSSL and LibreSSL, as they do not provide additional library initialization settings (notably, the OPENSSL_INIT_set_config_appname() call).
Changes
- Change to the NGINX queue sort algorithm – As detailed above, NGINX now uses merge sort, which has a time complexity of
O(n*log n). This creates a better NGINX startup experience, especially when there is a very high number of “locations” in the configuration.
- HTTP/2 iteration stream handling limit – This improvement ensures early detection of flood attacks on NGINX by imposing a limit on the number of new streams that can be introduced in one event loop. This limit is twice the value and is configured using
http2_max_concurrent_streams. It is applied even if the maximum threshold of allowed concurrent streams is never reached to account for cases when streams are reset immediately after sending the requests.
Bug Fixes
- Fixed buffer management with HTTP/2 autodetection – As part of HTTP/2 autodetection on plain TCP connections, initial data is first read into a buffer specified by the
client_header_buffer_size directive that does not have state reservation. This caused an issue where the buffer could be overread while saving the state. The current fix allows reading only the available buffer size instead of the fixed buffer size. This bug first appeared in NGINX mainline version 1.25.1 (NGINX Plus R30).
- Incorrect transport mode in OpenSSL compatibility mode – Prior to this release, the OpenSSL Compatibility Layer caused the connection to delay, in the event that an incorrect transport parameter was sent by the client. The fix effortlessly handles this behavior by first notifying the user about the incorrect parameter and subsequently closing the connection.
- Fixed handling of tatus headers without reason-phrase – A status header with an empty “reason phrase” like
Status: 404 was valid per Common Gateway Interface (CGI) specification but lost the trailing space during parsing. This resulted in an HTTP/1.1 404 status line in the response, which violates HTTP specification due to a missing trailing space. With this bug fix, only the status code is used from such short Status header lines, so NGINX will generate the status line itself with the space and appropriate reason phrase if available.
- Fixed memory leak on configuration reloads with PCRE2 – This issue occurred when NGINX was configured to use PCRE2 in version 1.21.5 or higher.
For the full list of new changes, features, bug fixes, and workarounds inherited from recent releases, see the NGINX CHANGES file.
Changes to the NGINX JavaScript Module
NGINX Plus R31 incorporates changes from the NGINX JavaScript (njs) module version 0.8.2. Here is the list of noticeable changes in njs since 0.8.0 (which was the part of NGINX Plus R30 release).
Features
- Introduced console object. These methods were introduced:
error(), info(), log(), time(), timeEnd(), and warn().
- Introduced the
js_periodic directive for http and stream that allows specifying a JS handler to run at regular intervals.
- Implemented
items() method of a shared dictionary. This method returns all the non-expired key-value pairs.
Changes
- Extended the “fs” module. Added
existsSync() method.
Bug Fixes
- Fixed the “xml” module. Fixed broken XML exception handling in
parse() method.
- Fixed
RegExp.prototype.exec() with global regular expression (regexp) and Unicode input.
- Fixed
size(), and keys() methods of a shared dictionary.
- Fixed erroneous exception in
r.internalRedirect() that was introduced in 0.8.0.
- Fixed incorrect order of keys in
Object.getOwnPropertyNames().
- Fixed HEAD response handling with large Content-Length in fetch API.
- Fixed
items() method for a shared dictionary.
For a comprehensive list of all the features, changes, and bug fixes, see the njs Changes log.
Upgrade or Try NGINX Plus
If you’re running NGINX Plus, we strongly encourage you to upgrade to NGINX Plus R31 as soon as possible. In addition to all the great new features, you’ll also pick up several additional fixes and improvements, and being up to date will help NGINX to help you if you need to raise a support ticket.
If you haven’t tried NGINX Plus, we encourage you to check it out. You can use it for security, load balancing, and API gateway use cases, or as a fully supported web server with enhanced monitoring and management APIs. Get started today with a free 30-day trial.