We are thrilled to share the latest news on NGINX Gateway Fabric, which is our conformant implementation of the Kubernetes Gateway API. We recently updated it to version 1.2.0, with several exciting new features and improvements. This release focuses on enhancing the platform’s capabilities and ensuring it meets our users’ demands. We have included F5 NGINX Plus support and expanded our API surface to cover the most demanded use cases. We believe these enhancements will create a better experience for all our users and help them achieve their goals more efficiently.
 Figure 1: NGINX Gateway Fabric’s design and architecture overview
Figure 1: NGINX Gateway Fabric’s design and architecture overview
NGINX Gateway Fabric 1.2.0 at a glance:
- NGINX Plus Support – NGINX Gateway Fabric now supports NGINX Plus for the data plane, which offers improved availability, detailed metrics, and real-time observability dashboards.
- BackendTLSPolicy – TLS verification allows NGINX Gateway Fabric to confirm the identity of the backend application, protecting against potential hijacking of the connection by malicious applications. Additionally, TLS encrypts traffic within the cluster, ensuring secure communication between the client and the backend application.
- URLRewrite – NGINX Gateway Fabric now supports URL rewrites in Route objects. With this feature, you can easily modify the original request URL and redirect it to a more appropriate destination. That way, as your backend applications undergo API changes, you can keep the APIs you expose to your clients consistent.
- Product Telemetry – With product telemetry now present in NGINX Gateway Fabric, we can help further improve operational efficiency of your infrastructure by learning about how you use the product in your environment. Also, we are planning to share these insights regularly with the community during our meetings.
We’ll take a deeper look at the new features below.
What’s New in NGINX Gateway Fabric 1.2.0?
NGINX Plus Support
NGINX Gateway Fabric version 1.2.0 has been released with support for NGINX Plus, providing users with many new benefits. With the new upgrade, users can now leverage the advanced features of NGINX Plus in their deployments including additional Prometheus metrics, dynamic upstream reloads, and the NGINX Plus dashboard.
This upgrade also allows you the option to get support directly from NGINX for your environment.
Additional Prometheus Metrics
While using NGINX Plus as your data plane, additional advanced metrics will be exported alongside the metrics you would normally get with NGINX Open Source. Some highlights include metrics around http requests, streams, connections, and many more. For the full list, you can check NGINX’s Prometheus exporter for a convenient list, but note that the exporter is not strictly required for NGINX Gateway Fabric.
With any installation of Prometheus or Prometheus compatible scraper, you can scrape these metrics into your observability stack and build dashboards and alerts using one consistent layer within your architecture. Prometheus metrics are automatically available in the NGINX Gateway Fabric through HTTP Port 9113. You can also change the default port by updating the Pod template.
If you are looking for a simple setup, you can visit our GitHub page for more information on how to deploy and configure Prometheus to start collecting. Alternatively, if you are just looking to view the metrics and skip the setup, you can use the NGINX Plus dashboard, explained in the next section.
After installing Prometheus in your cluster, you can access its dashboard by running port-forwarding in the background.
kubectl -n monitoring port-forward svc/prometheus-server 9090:80
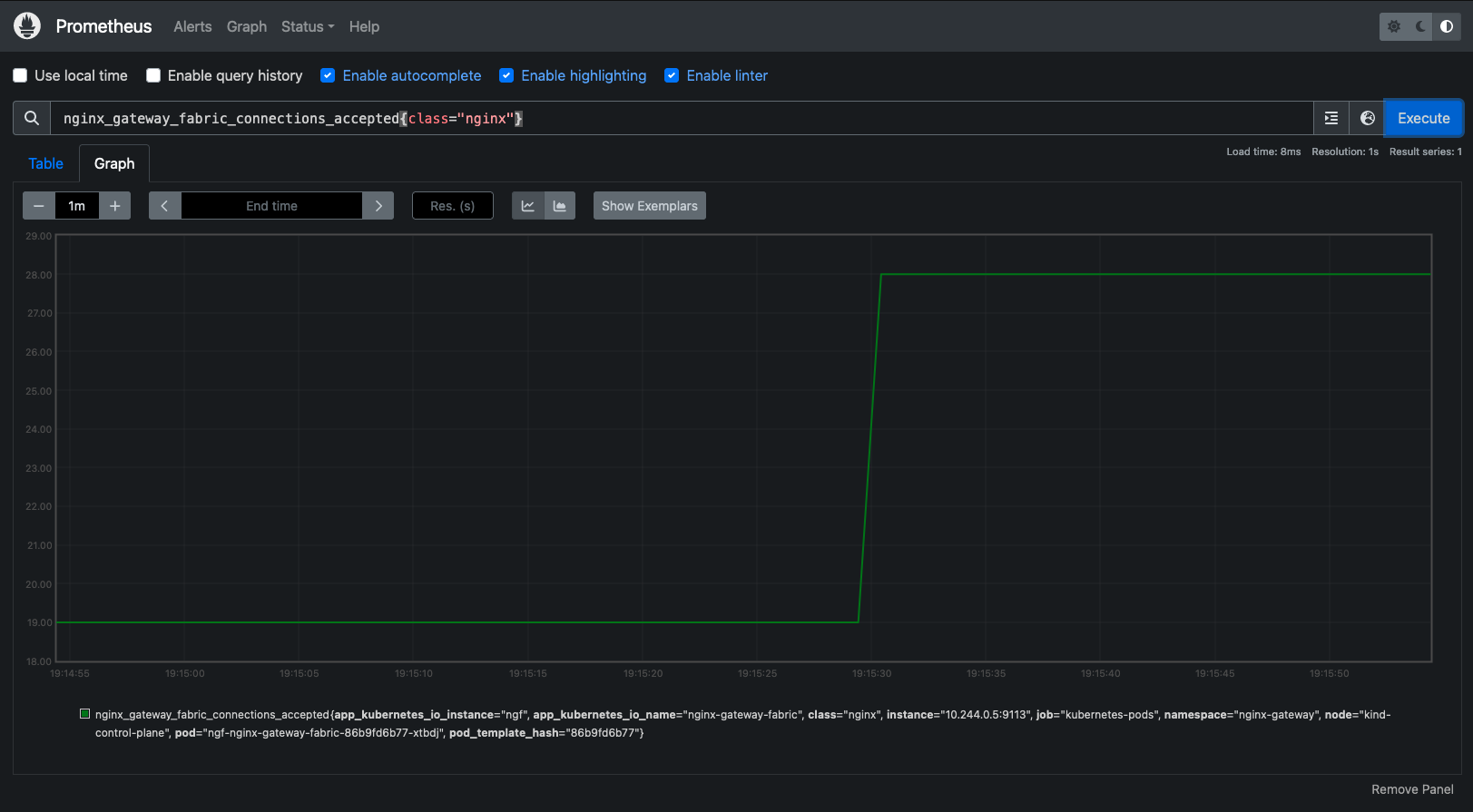 Figure 2: Prometheus Graph showing NGINX Gateway Fabric connections accepted
Figure 2: Prometheus Graph showing NGINX Gateway Fabric connections accepted
The above setup will work even if you are using the default NGINX Open Source as your data plane as well! However, you will not see any of the additional metrics that NGINX Plus provides. As the size and scope of your cluster grows, we recommend looking at how NGINX Plus metrics can help quickly resolve your capacity planning issues, incidents, and even backend application faults.
Dynamic Upstream Reloads
Dynamic upstream reloads, enabled by NGINX Gateway Fabric automatically when installed with NGINX Plus, allow NGINX Gateway Fabric to make updates to NGINX configurations without a NGINX reload.
Traditionally, when a NGINX reload occurs, the existing connections are handled by the old worker processes while the newly configured workers handle new ones. When all the old connections are complete, the old workers are stopped, and NGINX continues with only the newly configured workers. In this way, configuration changes are handled gracefully even in NGINX Open Source.
However, when NGINX is under high load, maintaining both old and new workers can create a resource overhead that may cause problems, especially if trying to run NGINX Gateway Fabric as lean as possible. The dynamic upstream reloads featured in NGINX Plus bypass this problem by providing an API endpoint for configuration changes that NGINX Gateway Fabric will use automatically if present, reducing the need for extra resource overhead to handle old and new workers during the reload process.
As you begin to make changes more often to NGINX Gateway Fabric, reloads will occur more frequently. If you are curious how often or when reloads occur in your current installation of NGF, you can look at the Prometheus metric nginx_gateway_fabric_nginx_reloads_total. For a full, deep dive into the problem, check out Nick Shadrin’s article here!
Here’s an example of the metric in an environment with two deployments of NGINX Gateway Fabric in the Prometheus dashboard:
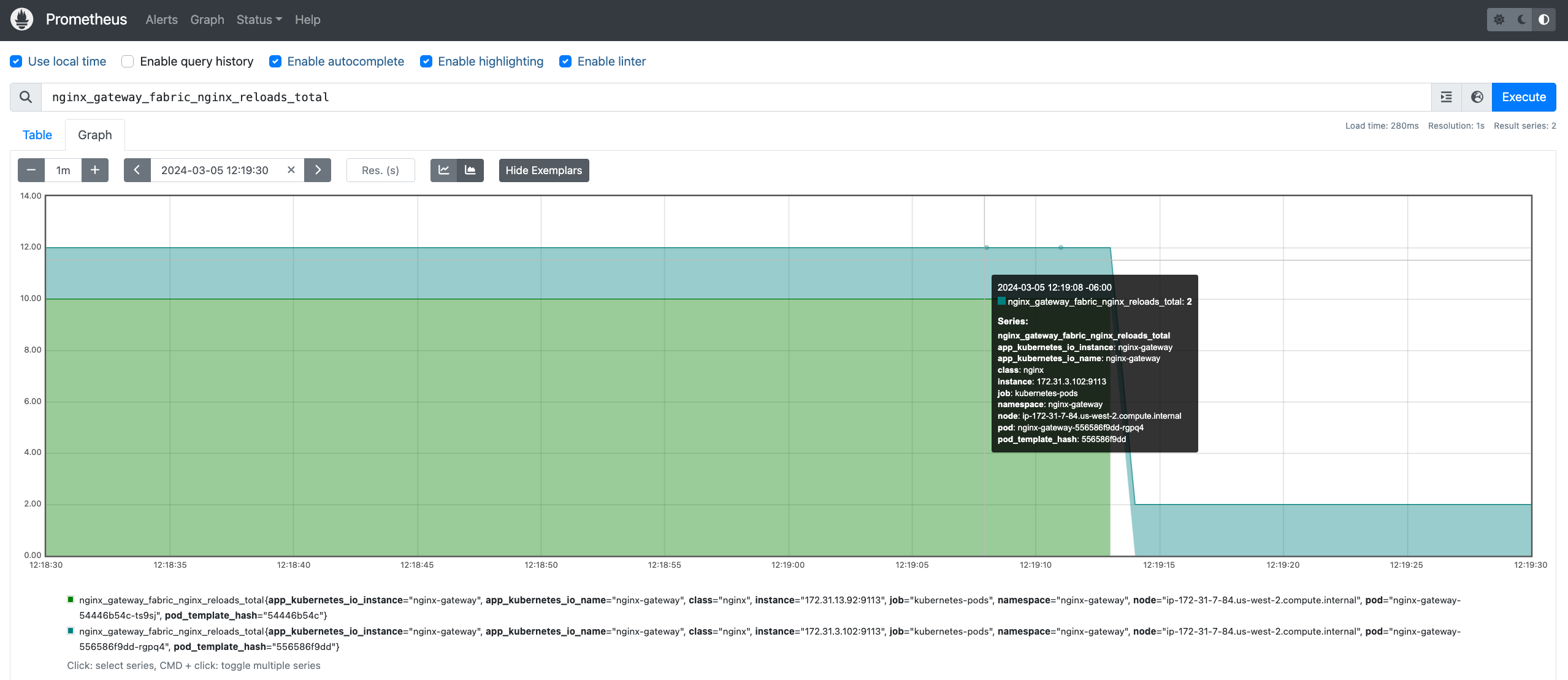 Figure 3: Prometheus graph showing the NGINX Gateway Fabric reloads total
Figure 3: Prometheus graph showing the NGINX Gateway Fabric reloads total
NGINX Plus Dashboard
As previously mentioned, if you are looking for a quick way to view NGINX Plus metrics without a Prometheus installation or observability stack, the NGINX Plus dashboard gives you real-time monitoring of performance metrics you can use to troubleshoot incidents and keep an eye on resource capacity.
The dashboard gives you different views for all metrics NGINX Plus provides right away and is easily accessible on an internal port. If you would like to take a quick look for yourself as to what the dashboard capabilities look like, check out our dashboard demo site at demo.nginx.com.
To access the NGINX Plus dashboard on your NGINX Gateway Fabric installation, you can forward connections to Port 8765 on your local machine via port forwarding:
kubectl port-forward -n nginx-gateway 8765:8765
Next, open your preferred browser and type http://localhost:8765/dashboard.html in the address bar.
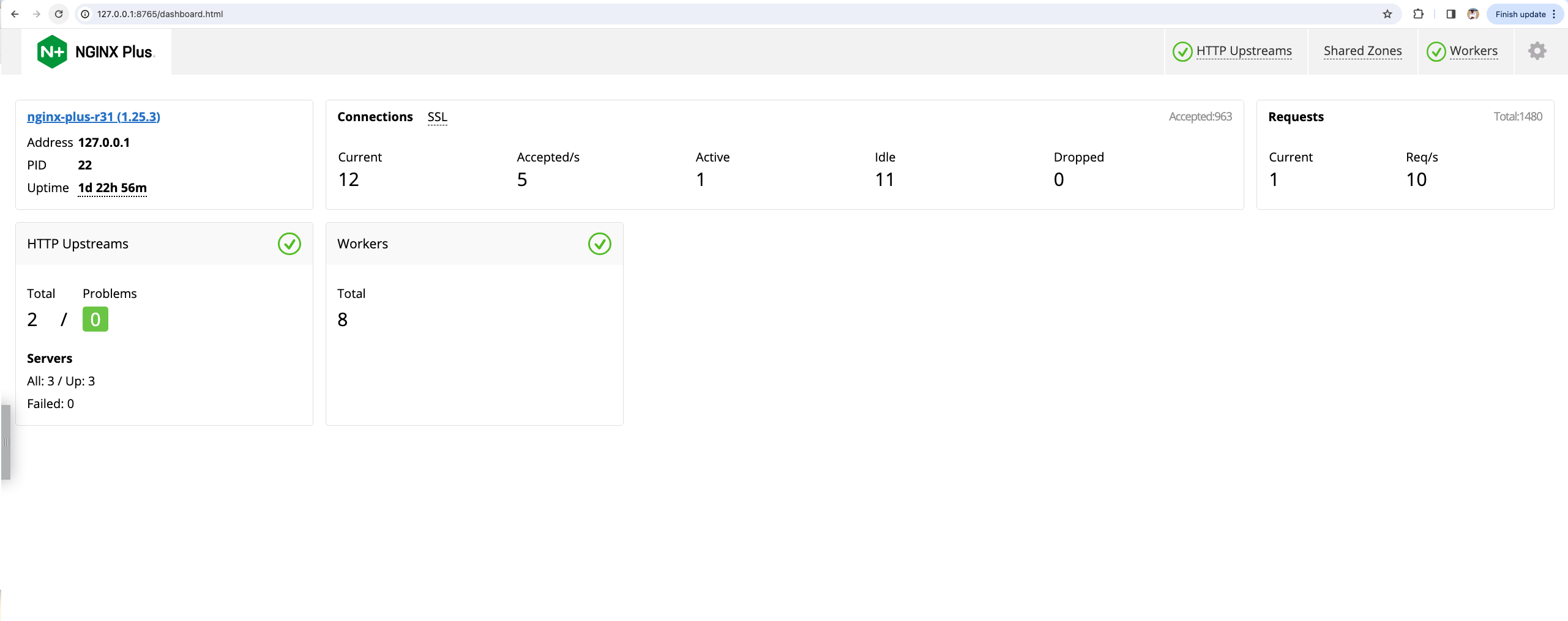 Figure 4: NGINX Plus Dashboard overview
Figure 4: NGINX Plus Dashboard overview
BackendTLSPolicy
This release now comes with the much-awaited support for the BackendTLSPolicy. The BackendTLSPolicy introduces encrypted TLS communication between NGINX Gateway Fabric and the application, greatly enhancing the communication channel’s security. Here’s an example that shows how to apply the policy by specifying settings such as TLS ciphers and protocols when validating server certificates against a trusted certificate authority (CA).
The BackendTLSPolicy enables users to secure their traffic between NGF and their backends. You can also set the minimum TLS version and cipher suites. This protects against malicious applications hijacking the connection and encrypts the traffic within the cluster.
To configure backend TLS termination, first create a ConfigMap with the CA certification you want to use. For help with managing internal Kubernetes certificates, check out this guide.
kind: ConfigMap
apiVersion: v1
metadata:
name: backend-cert
data:
ca.crt:
< -----BEGIN CERTIFICATE-----
-----END CERTIFICATE-----
>
Next, we create the BackendTLSPolicy, which targets our secure-app Service and refers to the ConfigMap created in the previous step:
apiVersion: gateway.networking.k8s.io/v1alpha2
kind: BackendTLSPolicy
metadata:
name: backend-tls
spec:
targetRef:
group: ''
kind: Service
name: secure-app
namespace: default
tls:
caCertRefs:
- name: backend-cert
group: ''
kind: ConfigMap
hostname: secure-app.example.com
URLRewrite
With a URLRewrite filter, you can modify the original URL of an incoming request and redirect it to a different URL with zero performance impact. This is particularly useful when your backend applications change their exposed API, but you want to maintain backwards compatibility for your existing clients. You can also use this feature to expose a consistent API URL to your clients while redirecting the requests to different applications with different API URLs, providing an “experience” API that combines the functionality of several different APIs for your clients’ convenience and performance.
To get started, let’s create a gateway for the NGINX gateway fabric. This will enable us to define HTTP listeners and configure the Port 80 for optimal performance.
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: cafe
spec:
gatewayClassName: nginx
listeners:
- name: http
port: 80
protocol: HTTP
Let’s create an HTTPRoute resource and configure request filters to rewrite any requests for /coffee to /beans. We can also provide a /latte endpoint that is rewritten to include the /latte prefix for the backend to handle (“/latte/126” becomes “/126”).
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: coffee
spec:
parentRefs:
- name: cafe
sectionName: http
hostnames:
- "cafe.example.com"
rules:
- matches:
- path:
type: PathPrefix
value: /coffee
filters:
- type: URLRewrite
urlRewrite:
path:
type: ReplaceFullPath
replaceFullPath: /beans
backendRefs:
- name: coffee
port: 80
- matches:
- path:
type: PathPrefix
value: /latte
filters:
- type: URLRewrite
urlRewrite:
path:
type: ReplacePrefixMatch
replacePrefixMatch: /
backendRefs:
- name: coffee
port: 80
The HTTP rewrite feature helps ensure flexibility between the endpoints on the client side and how they are mapped with the backend. It also allows traffic redirection from one URL to another, which is particularly helpful when migrating content to a new website or API traffic.
Although NGINX Gateway Fabric supports path-based rewrites, it currently does not support path-based redirects. Let us know if this is a feature you need for your environment.
Product Telemetry
We have decided to include product telemetry as a mechanism to passively collect feedback as a part of the 1.2 release. This feature will collect a variety of metrics from your environment and send them to our data collection platform every 24 hours. No PII is collected, and you can see the full list of what is collected here.
We are committed to providing complete transparency around our telemetry functionality. While we will document every field we collect, and you can validate what we collect by our code, you always have the option to disable it completely. We are planning to regularly review interesting observations based on the statistics we collect with the community in our community meetings, so make sure to drop by!
Resources
For the complete changelog for NGINX Gateway Fabric 1.2.0, see the Release Notes. To try NGINX Gateway Fabric for Kubernetes with NGINX Plus, start your free 30-day trial today or contact us to discuss your use cases.
If you would like to get involved, see what is coming next, or see the source code for NGINX Gateway Fabric, check out our repository on GitHub!
We have bi-weekly community meetings on Mondays at 9AM Pacific/5PM GMT. The meeting link, updates, agenda, and notes are on the NGINX Gateway Fabric Meeting Calendar. Links are also always available from our GitHub readme.