

Have you ever benchmarked a server in the lab and then deployed it for real traffic, only to find that it can’t achieve anything close to the benchmark performance? CPU utilization is low and there are plenty of free resources, yet clients complain of slow response times, and you can’t figure out how to get better utilization from the server.
What you’re observing is one effect of what we can call “HTTP heavy lifting”. In this blog post, we investigate how HTTP operates and how common HTTP servers process HTTP transactions. We look at some of the performance problems that can occur, and see how NGINX’s event‑driven model makes it a very effective accelerating proxy for these HTTP servers. With NGINX, you can transform your real‑world performance so it’s back to the level of your local benchmarks.
For pointers on tuning Linux and NGINX to improve the speed and scalability of your applications, see Tuning NGINX for Performance on our blog.
An Introduction to HTTP and Keepalive Connections
HTTP keepalive connections are a necessary performance feature that reduce latency and allow web pages to load faster.
HTTP is a simple, text‑based protocol. If you’ve not done so before, take a look at the output from an HTTP debugging tool such as the one in your web browser, and check out the standard request and response structure:

In its simplest implementation, an HTTP client creates a new TCP connection to the destination server, writes the request, and receives the response. The server then closes the TCP connection to release resources.

This mode of operation can be very inefficient, particularly for complex web pages with a large number of elements or when network links are slow. Creating a new TCP connection requires a ‘three‑way handshake’, and tearing it down also involves a two‑way shutdown procedure. Repeatedly creating and closing TCP connections, one for each message, is akin to hanging up and redialing after each person speaks in a phone conversation.
HTTP uses a mechanism called keepalive connections to hold open the TCP connection between the client and the server after an HTTP transaction has completed. If the client needs to conduct another HTTP transaction, it can use the idle keepalive connection rather than creating a new TCP connection.

Clients generally open a number of simultaneous TCP connections to a server and conduct keepalive transactions across them all. These connections are held open until either the client or the server decides they are no longer needed, generally as a result of an idle timeout.
Modern web browsers typically open 6 to 8 keepalive connections and hold them open for several minutes before timing them out. Web servers may be configured to time these connections out and close them sooner.
What Is the Effect of Keepalives on the HTTP Server?
If lots of clients use HTTP keepalives and the web server has a concurrency limit or scalability problem, then performance plummets once that limit is reached.
The approach above is designed to give the best possible performance for an individual client. Unfortunately, in a ‘tragedy of the commons’‑like scenario, if all clients operate in this way, it can have a detrimental effect on the performance of many common web servers and web applications.
The reason is that many servers have a fixed concurrency limit. For example, in common configurations, the Apache HTTP Server can only process limited numbers of concurrent TCP connections: 150 with the worker multiprocessing module (MPM) and 256 with the prefork MPM. Each idle HTTP keepalive connection consumes one of these concurrency slots, and once all of the slots are occupied, the server cannot accept any more HTTP connections.
Conventional wisdom says to turn off keepalives on the web server, or limit them to a very short lifetime. They provide a very simple vector for the SlowHTTPTest and Slowloris denial-of-service attacks (for a quick solution, see Protecting against Keep‑Dead Denial of service at serverfault.com).
Furthermore, these web and application servers typically allocate an operating system thread or process for each connection. A TCP connection is a very lightweight operating system object, but a thread or process is very heavyweight. Threads and processes require memory, they must be actively managed by the operating system, and ‘context switching’ between threads or processes consumes CPU. Assigning each connection its own thread or process is hugely inefficient.
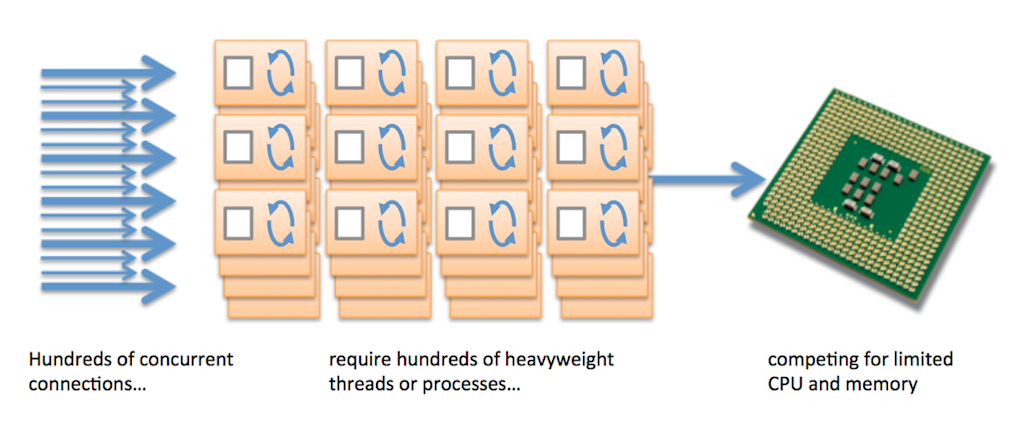
The large number of concurrent client connections and the assignment of a thread or process to each connection produces the phenomenon known as “HTTP heavy lifting”, where a disproportionately large effort is required to process a lightweight HTTP transaction.
What Does This Mean in Practice?
It does not take many clients to exhaust the concurrency limit in many contemporary web and application servers.
If a client opens 8 TCP connections and keeps each alive for 15 seconds after the last use, the client consumes 8 concurrency slots for 15 seconds. If clients arrive at your website at the rate of 1 per second, 120 concurrency slots are continually occupied by idle keepalive connections. If the rate is 2 clients per second, 240 concurrency slots are occupied. Once the slots are exhausted, new clients cannot connect until the existing connections time out.
This can result in very uneven levels of service. Clients who successfully acquire a keepalive connection can browse your service at will. Clients who try to connect when the concurrency slots are all occupied are locked out and have to wait in a queue.
Why Do You Not See These Effects During Benchmark Testing?
These problems only manifest themselves in slow networks with many clients. They don’t appear when benchmarking with a single client over a fast local network.
There are a couple of reasons why you may not see these effects in a benchmark.
- If you don’t enable keepalives during the benchmark, the client creates a new TCP connection for each transaction (and the connection is torn down after the transaction completes). Because you’re most likely running the benchmark over a fast, local network, the benchmark succeeds and you don’t see the performance problems created by not using keepalives.
- If you do enable keepalives, then most likely you can run fewer concurrent connections than your server’s limit, and your benchmark client saturates each connection (uses it repeatedly), driving your server to its maximum capacity. However, this does not resemble the real‑world profile for connections.
Note that most benchmark tools only report on successful transactions. Connections that are stalled because of resource exhaustion might not be reported, or might appear to be only a tiny fraction of the successful connections. This conceals the true nature of the problem with real‑world traffic.
How Common Is The Problem?
Any thread‑ or process‑based web or application server is vulnerable to concurrency limitations.
This problem is inherent to any web or application platform that assigns a thread or process to each connection. It’s not easy to detect in an optimized benchmark environment, but it manifests itself as poor performance and excessive CPU utilization in a real‑world environment.
There are several measures you can take to address this problem:
- Increase the number of threads or processes – This is a very short‑term measure. Threads and processes are heavyweight operating system objects and incur a rapidly increasing management overhead as more and more are spawned.
- Disable or limit the use of HTTP keepalives – This postpones the concurrency limit, but results in much poorer performance for each client.
- Use specialized keepalive processing – The Apache HTTP Server (web server) has a relatively new event MPM that moves connections between worker threads and a dedicated event thread when they move between ‘active’ and ‘idle keepalive’ states. This may be an option if the other modules you use support this MPM; note that SSL/TLS connections are still processed entirely in dedicated threads.
- Use a more efficient processing model – By far the simplest and most effective measure you can take is to put an efficient HTTP proxy in front of your web or application servers. An event‑driven proxy like NGINX does not have the concurrency limitations described above. It laughs in the face of slow connections and idle keepalives. Furthermore, it effectively translates slow client‑side connections with multiple idle keepalive connections into the fast, local, highly efficient benchmark‑style connections that extract the best possible performance from your web and application servers.
Use NGINX as an Accelerating HTTP Proxy
NGINX uses a different architecture that does not suffer from the concurrency problems described above. It transforms slow client connections to optimized benchmark‑like connections to extract the best performance from your servers.
NGINX uses a highly efficient event‑driven model to manage connections.
Each NGINX process can handle multiple connections at the same time. When a new connection is accepted, the overhead is very low (consisting of a new file descriptor and a new event to poll for), unlike the per‑process or per‑thread model described above. NGINX has a very effective event loop:
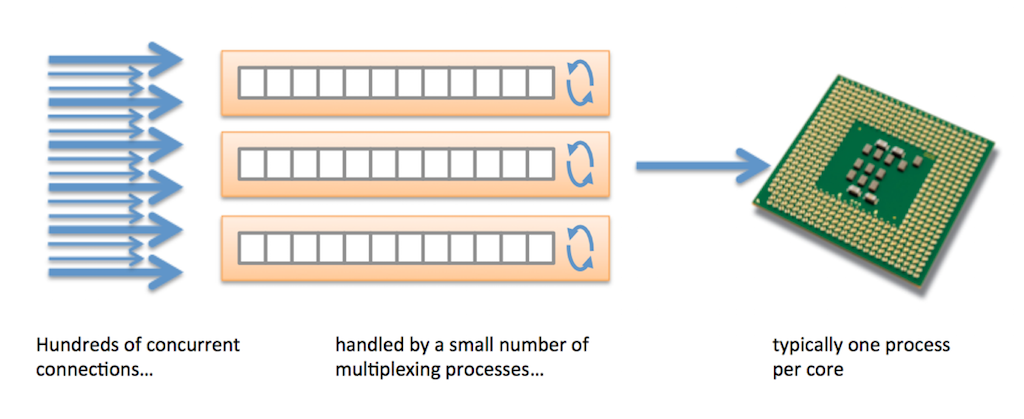
This allows each NGINX process to easily scale to tens, thousands, or hundreds of thousands of connections simultaneously.
NGINX then proxies the requests to the upstream server, using a local pool of keepalive connections. You don’t incur the overhead from opening and closing TCP connections, and the TCP stacks quickly adapt to the optimal window size and retry parameters. Writing requests and reading responses is much more rapid over the local, optimized network:
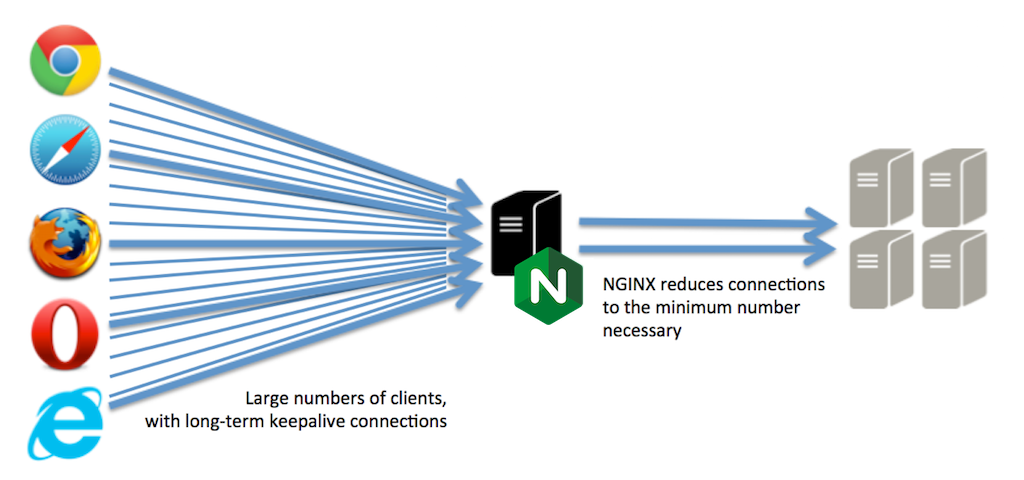
The net effect is that the upstream server finds itself talking to a single local client (NGINX) over a fast network, and it’s a client that makes optimal use of HTTP keepalive connections to minimize connection setup without holding connections open unnecessarily. This puts the server back into its optimal, benchmark‑like environment.
With NGINX acting as an HTTP proxy, you see:
- Better utilization of existing resources. Your web and application servers can process more transactions per second because they no longer perform HTTP heavy lifting.
- Reduced error rates. HTTP timeouts are much less likely because NGINX acts as a central scheduler for all clients.
- Better end‑user performance. Servers run more efficiently and service connections faster.
Other Ways NGINX Can Accelerate Services
Removing the burden of HTTP heavy lifting is only one of the performance‑transforming measures that NGINX can bring to bear on your overloaded application infrastructure.
NGINX’s HTTP‑caching feature can cache responses from the upstream servers, following standard cache semantics to control what is cached and for how long. If several clients request the same resource, NGINX can respond from its cache and not burden upstream servers with duplicate requests.
NGINX can also offload other operations from the upstream server. You can offload the data compression operations for reducing bandwidth usage, centralize SSL/TLS encryption and decryption, perform initial client authentication (for example, with HTTP basic authentication, subrequests to external auth servers, and JSON Web Tokens), and apply all manner of rules to rate limit traffic when necessary.
Not Your Typical Load Balancer or ADC
Finally, do not forget that unlike other accelerating proxies, load balancers, or application delivery controllers (ADCs), NGINX is also a full web server. You can use NGINX to serve static content, forward traffic to application servers for Java, PHP, Python, Ruby, and other languages, deliver media (audio and video), integrate with authentication and security systems, and even respond to transactions directly using rules embedded in the NGINX configuration.
With no built‑in performance limitations, NGINX and NGINX Plus take full advantage of the hardware you deploy it on, now and in the future.
To try NGINX Plus, start your free 30-day trial today or contact us to discuss your uses cases.


