

![Title slide from webinar 'Three Models in the NGINX Microservices Reference Architecture' [presenters: Chris Stetson, Floyd Smith]](https://www.nginx.com/wp-content/uploads/2017/02/webinar-3MRAmodels-slide1_title.png)
This post is adapted from a webinar by Chris Stetson and Floyd Smith. It describes the three models in the NGINX Microservices Reference Architecture (MRA): the Proxy Model, Router Mesh Model, and Fabric Model.
You can also download our ebook, Microservices Reference Architecture, which covers the models in greater detail, along with other topics.
Have specific questions about microservices? Sign up for our upcoming Ask Me Anything session about the Microservices Reference Architecture!
Table of Contents
| 0:00 | Introduction |
| 1:07 | Who Are We? |
| 1:56 | Agenda |
| 3:29 | Who Are You? |
| 4:40 | About NGINX, Inc. |
| 5:26 | Usage of NGINX and NGINX Plus |
| 6:45 | Popular Websites |
| 6:57 | What’s Inside NGINX Plus |
| 8:02 | Where NGINX Plus Fits |
| 8:54 | NGINX Plus Works In All Environments |
| 9:46 | NGINX and Microservices |
| 10:57 | The Big Shift |
| 12:39 | Architectural Changes: From Monolith… |
| 14:05 | Architectural Changes: …To Microservices |
| 15:22 | An Anecdote |
| 17:51 | The Tight Loop Problem |
| 19:08 | Mitigation |
| 20:24 | NGINX Loves Microservices |
| 21:23 | Ingenious Photo Site |
| 22:45 | The Networking Problem |
| 23:48 | Service Discovery |
| 25:56 | Load Balancing |
| 27:14 | Secure and Fast Communication |
| 30:13 | Solution |
| 30:40 | Network Architectures |
| 31:44 | Proxy Model |
| 34:27 | Proxy Model Summary |
| 34:54 | Router Mesh Model |
| 36:26 | Circuit Breakers |
| 38:27 | Router Mesh Model Summary |
| 38:51 | Fabric Model |
| 39:45 | Normal Process |
| 40:44 | Fabric Model In Detail |
| 42:35 | Circuit Breaker Pattern |
| 43:02 | Fabric Model Summary |
| 44:31 | NGINX and Microservices |
| 47:41 | Questions |
0:00 Introduction
Floyd Smith: Welcome to our webinar, Three Models in the NGINX Microservices Reference Architecture. To briefly explain the title to those of you who who are new to the topic: the NGINX Microservices Reference Architecture (MRA) is a set of approaches for implementing robust microservices in your web application or website, and the three models are key parts of the architecture.
Our focus today will be distinguishing among the three models and giving you some idea of which one might be suitable for the new apps you’re planning to build or the apps you’re going to convert to microservices from a monolithic architecture.
1:07 Who Are We?

I’m Floyd Smith, one of the presenters today. I’m a technical marketing writer at NGINX, and I’ve worked at Apple and Alta Vista. Somewhat ironically for those of you who know the history, I was later at Google, as well as other companies. I’m also the author of multiple books on technology.
Presenting with me is Chris Stetson, Chief Architect here at NGINX. Chris was formerly the Vice President of Technology at Razorfish and Vice President on the West Coast for Huge.
1:56 Agenda

On our agenda today: first I’ll introduce NGINX and NGINX Plus, then Chris will discuss the shift that is going on in app development. He will talk about the networking problem that the MRA is designed to solve, the three architectural models we’ve mentioned, and some of the issues that can come up.
We’ll answer questions at the end, but we probably won’t have enough time for all of them, so I will mention that we will be having a webinar in a few weeks that is just a Q&A session. If we still don’t have time for all the questions at that session, we’ll find a way to handle them afterward.
3:29 Who Are You?
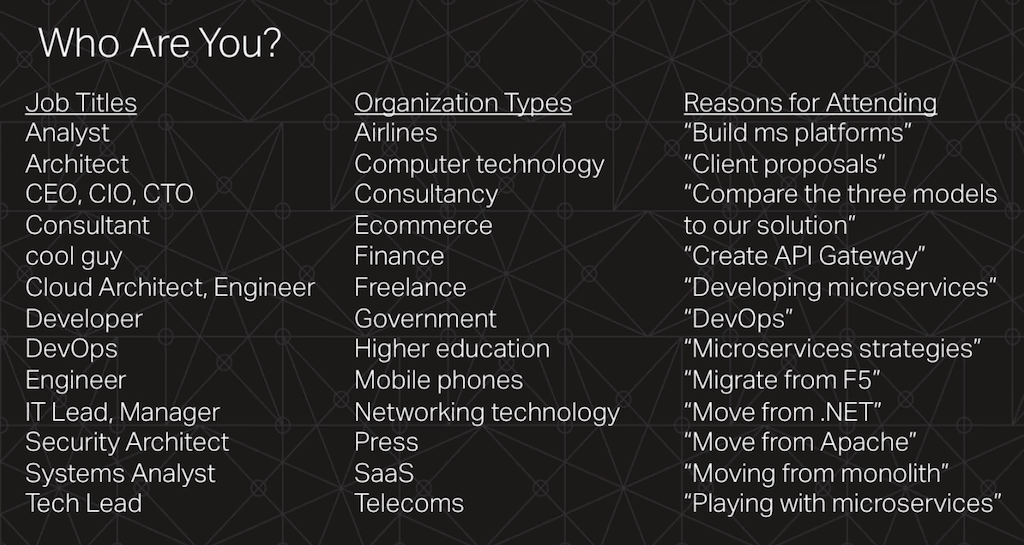
We have a lot of people interested in the presentation today. First of all, a wide range of job titles. We have analysts, lots of architects which is perfect for this presentation, CEOs, CIOs, CTOs, a number of consultants, and someone registered as “cool guy.”
We have every type of organization that you can imagine. I was very pleased to see that the British Library is among the attendees (I got permission to mention this), because I did some work in the British Library when I lived and worked in London. As you can see we have a great spread of organizations.
The reasons that people gave for attending fit right into the purpose of our presentation today: to build microservices platforms, to answer client proposals, to compare the three models to a solution someone has already developed, and to move from other systems and approaches to this one.
4:40 About NGINX, Inc.
![Slide of facts about NGINX, Inc: Founded 2011, NGINX Plus released 2013, more than 1000 customers, and over 100 employees [webinar: Three Models in the NGINX Microservices Reference Architecture]](https://www.nginx.com/wp-content/uploads/2017/02/webinar-3MRAmodels-slide5_about-nginx-inc.png)
NGINX, Inc. was founded in 2011. This was off of the introduction of the open source NGINX software in 2004, but it was seen that the resources needed to keep development going were a lot larger than could be provided by a volunteer project, so the company was started.
NGINX Plus, our commercial product, was released in 2013. We’re a classic Silicon Valley startup: we’re VC‑backed by enterprise software industry leaders. We have offices here in San Francisco, Sunnyvale, Cork, Cambridge, and Moscow. We have more than 1,000 commercial customers and more than 100 employees.
5:26 Usage of NGINX and NGINX Plus
![Over 300 million websites run NGINX and NGINX Plus, which can be a key facilitator of a move to microservices [webinar: Three Models in the NGINX Microservices Reference Architecture]](https://www.nginx.com/wp-content/uploads/2017/02/webinar-3MRAmodels-slide6_300-million-sites.png)
There are more than 300 million total websites running on NGINX.
![Over half of the 100,000 busiest websites in the world choose NGINX as their application delivery platform [webinar: Three Models in the NGINX Microservices Reference Architecture]](https://www.nginx.com/wp-content/uploads/2017/02/webinar-3MRAmodels-slide7_50-percent-top-sites.png)
More than 50% of the top 100,00 busiest websites now use open source NGINX or NGINX Plus. That’s quite a number, and it’s increasing a percent or so every couple of months.
I want to spend just a moment on that. People at these websites have a lot of things to do, so they don’t idly drop NGINX or NGINX Plus into their infrastructure. They’re doing it for a reason, and the reasons include performance, reliability, and security. So if you’re not using NGINX or NGINX Plus yet, note that more than half of your colleagues – doing something similar to what you’re doing – have found this to be a great solution.
Even if you’re not switching to microservices right away, moving to NGINX or NGINX Plus puts you in a great position to implement solutions like what we’ll be discussing today.
![Among companies running their sites and apps on Amazon Web Services, more than 40% use NGINX as their application delivery platform and microservices enabler [webinar: Three Models in the NGINX Microservices Reference Architecture]](https://www.nginx.com/wp-content/uploads/2017/02/webinar-3MRAmodels-slide8_40-percent-aws.png)
More than 40% of sites on Amazon Web Services (AWS) use NGINX.
6:45 Popular Websites
![Well-known websites using NGINX and NGINX Plus include Airbnb, CNN, Dropbox, GitHub, Hulu, Netflix, Pinterest, and WordPress [webinar: Three Models in the NGINX Microservices Reference Architecture]](https://www.nginx.com/wp-content/uploads/2017/02/webinar-3MRAmodels-slide9_popular-websites.png)
Here are some of the more interesting websites of our many customers.
6:57 What’s Inside NGINX Plus
![NGINX and NGINX Plus both provide request routing, SSL termination, data compression, an embedded scripting language, load balancing, and caching; NGINX Plus adds health checks, monitoring, and dynamic reconfiguration [webinar: Three Models in the NGINX Microservices Reference Architecture]](https://www.nginx.com/wp-content/uploads/2017/02/webinar-3MRAmodels-slide10_inside-nginx-plus.png)
What’s inside NGINX Plus? This slide shows what’s in open source NGINX and some of the things that distinguish NGINX Plus. Features like request routing, compression, SSL handling, and the embedded scripting language [nginScript, now called the NGINX JavaScript module] are all in both versions of the software. Load balancing is in both versions, but there are advanced features in NGINX Plus; the same is true for media streaming.
Features included only in NGINX Plus are application health monitoring, monitoring analytics, GUI visualization, and a RESTful API for configuration so you can do things programmatically rather than manually. There’s much more about all of these features on our website, nginx.com.
One thing not shown in this slide is support, which is hugely important. Even if you’re only using open source features at least at first, having support for a major implementation is very important.
8:02 Where NGINX Plus Fits
![NGINX and NGINX Plus fit into your infrastructure as a reverse proxy server for load balancing and caching as well as a web server [webinar: Three Models in the NGINX Microservices Reference Architecture]](https://www.nginx.com/wp-content/uploads/2017/02/webinar-3MRAmodels-slide11_where-nginx-plus-fits.png)
So where does NGINX Plus fit in a website or app‑delivery architecture? It fits in two different places. First of all, it fits in the reverse proxy position, and that’s a very widespread use case for NGINX Plus. So NGINX Plus supports caching, load balancing, API gateway, all sorts of functionality in just one piece of software.
As shown here, NGINX and NGINX Plus also serve as web servers where it actually interacts with your app. However, the web server can actually be Apache, IIS, or anything else that you care to implement there. The trick is that you can put in NGINX Plus as the reverse proxy without changing your app at all. That’s a huge win for people with existing apps.
8:54 NGINX Plus Works In All Environments
![NGINX Plus works in all environments: on bare metal, in VMs and containers, and in public, private, and hybrid clouds [webinar: Three Models in the NGINX Microservices Reference Architecture]](https://www.nginx.com/wp-content/uploads/2017/02/webinar-3MRAmodels-slide12_all-environments.png)
NGINX Plus works in all environments. So there’s a little bit of a push and pull here. Cloud providers, for instance, encourage you to use services within their environment. That’s convenient, but it causes lock‑in: if you want to move to a different environment, you’re stuck.
We encourage developers to put as much functionality as possible into the configuration of NGINX Plus. That leaves your platform independent and ready to go where cost, available services, reliability, and all of the other things you want to consider are available.
We work very well with Docker. We’re the number one downloaded piece of software on Docker Hub. People want to put NGINX and NGINX Plus in containers and then move them around.
9:46 NGINX and Microservices
![NGINX, Inc. provides extensive resources about microservices, including two ebooks and a training course [webinar: Three Models in the NGINX Microservices Reference Architecture]](https://www.nginx.com/wp-content/uploads/2017/02/webinar-3MRAmodels-slide13_nginx-microservices-resources.png)
NGINX is very big in the emerging world of microservices. Two-thirds of the developers we surveyed are using or investigating microservices.
Microservices is the number one topic on our website, so if you or your colleague need some education on this topic, we have the Chris Richardson seven‑part blog series. It could be a computer science course, really, about why you would consider microservice and what choices you make in moving to microservices. A nice combination of theory and practice.
Based on that and a whole lot of other resources as background, we came up with the NGINX Microservices Reference Architecture and Chris Stetson is writing an on‑going series of blog posts on it.
We also have MRA training, which keeps selling out, and a lot more around this. You can contact sales here at NGINX for a free evaluation of NGINX Plus and try some of these things for yourself.
I will now turn the presentation over to Chris.
10:57 The Big Shift

Chris Stetson: Good morning everyone, and thanks for joining. As Floyd pointed out earlier, we will be talking about a number of things related to the reference architecture, starting with what I call “The Big Shift.”
This is really a discussion around the architectural changes occurring as people are shifting from monolithic or SOA-based [service-oriented architecture] applications to microservices, and what that means in how you architect an application. There are some real benefits to switching, but there are some trade-offs as well, and that’s where we talk about the networking problems that you have to address and resolve when building your applications.
Specifically, there are issues around service discovery, load balancing, security, and performance. We are trying to address those with the architectures that we’ll be talking about. The three architectures that we have built into the Microservices Reference Architecture are the Proxy Model, the Router Mesh Model, and the Fabric Model. They – to varying degrees – address all of the problems that we will highlight there.
Of course everything is not cookies and cream, so we will address some of the issues that come up with introducing this technology and this architecture to your applications. Then we will stop and have some time for questions. Alright, so let’s talk about this big shift – the architectural change that we’re all witnessing in large‑scale web applications.
12:39 Architectural Changes: From Monolith…
![The move from monolithic to microservices architecture for web application delivery is an emerging trend [webinar: Three Models in the NGINX Microservices Reference Architecture]](https://www.nginx.com/wp-content/uploads/2017/02/webinar-3MRAmodels-slide14-architectural-changes1.png)
This slide shows a classic model for a monolithic application. Having built applications for the past 20 years, I can say this model for building an application is classic: all of the functional components of the application reside on a single host in a single virtual machine, and talk to each other through object references or method calls, is classic. It’s the way we’ve built applications for a long time. Occasionally, the application would reach out to third‑party services (like to Twilio for notifications or to Stripe for a payment gateway), but for the most part all of the application functionality existed within a single virtual machine.
The benefit of that is that the application engine, whether it’s Java or PHP or Python, would manage all communication, instantiation of your instances, etc. However, this model made your codebase more complex and introduced problems in updating the different components.
14:05 Architectural Changes: …To Microservices
![In a microservices architecture, the components of a web application are hosted in containers and communicate across the network using RESTful API calls [webinar: Three Models in the NGINX Microservices Reference Architecture]](https://www.nginx.com/wp-content/uploads/2017/02/webinar-3MRAmodels-slide15_architectural-changes2.png)
To address those issues, we have shifted to a microservices approach. You can see here that in a microservices environment, the classic functional components of the application – passenger management, billing, passenger web UI – have all been broken out into individual services that communicate over the network via RESTful API.
This give you the ability to easily change out components. For example, you can redeploy the passenger management system with bug fixes or new features without interrupting the service of all of the other functional components within the site.
This also gives you the ability to asymmetrically scale the application. For example if you had a surge in passengers, you would be able to build out more instances of the passenger web UI without having to scale the notification system unless it was required.
So it gives you a lot of flexibility in terms of deployment and management, and it really gives that isolation of functional components to the application.
15:22 An Anecdote
![Section title slide reading "An Anecdote" [presentation by Chris Stetson, NGINX Microservices Practice Lead, at nginx.conf 2016]](https://www.nginx.com/wp-content/uploads/2016/10/Stetson-conf2016-slide5_anecdote.png)
But it does introduce some problems, and I want to talk about an experience I had when building out an application for Microsoft. I built out the showcase application at Microsoft. It was their web‑publishing application for the videos that they produce. Microsoft in any given year will produce upwards of 60,000 videos for customers – things like “Microsoft Word Tips and Tricks.” That was the most popular video at the time at Microsoft.
They needed a platform to publish the videos and allow other parts of the site to embed and display the videos, so we built the showcase application to do that. Initially we build it as a monolith in .NET, and it proved to be very popular. We got a lot of adoption within Microsoft, so we decided to build [a new version] as a SOA‑based application to give us more flexibility.
Building SOA applications in .NET is actually fairly easy. The conversion from a DLL‑based application to a SOA application is almost the flip of a switch in Visual Studio. We made the change and in a couple weeks of refactoring, we were able to get our code to function within that context and in our testing it seemed to be working pretty well.
It wasn’t until we moved to our staging environment that we started to see some serious issues with the application. What was happening was for some of our most popular pages, it took over a minute to render them – an unbelievably long time to render a page that previously took five or six seconds.
17:51 The Tight Loop Problem
![Stetson's experience with converting a monolith to an SOA architecture alerted him to the performance problem when there are thousands of requests flying around [webinar: Three Models in the NGINX Microservices Reference Architecture]](https://www.nginx.com/wp-content/uploads/2017/02/webinar-3MRAmodels-slide16_tight-loop-problem.png)
We did some digging in the application, and ultimately we found that the culprit was a component called Telligent Community Server, which said that it was SOA‑ready. But it was not optimized for a network‑based application, for addressing the various components of the application across the network.
What we found was that a the page was rendering, Telligent Community Server was writing data to the Comments section of the page (a big part of what it does), including user IDs. Then it would go through a tight loop back to the User Manager to look up the usernames corresponding to the user IDs so it could replace IDs with names on the page.
So when we tried to render a popular page like “Microsoft Word Tips and Tricks”, which had literally thousands of comments, the server would go over the network thousands of times and make the rendering take over a minute. This was opposed to the five or six seconds it was taking when we built it as a non‑SOA‑based application.
19:08 Mitigation
![To solve the problems he experiences with excessive traffic in a network architecture, Stetson grouped requests and cached data [presentation by Chris Stetson, NGINX Microservices Practice Lead, at nginx.conf 2016]](https://www.nginx.com/wp-content/uploads/2016/10/Stetson-conf2016-slide7_mitigation.png)
We really had to struggle and work hard to address all of the issue that this presented. We tried to group the requests as best we could, we tried to cache the data. We spent a lot of time trying to optimize the network, but if you ever used IIS 7, you know how limited your ability was to do that. Looking back on it, I really wish we had had NGINX or NGINX Plus because it would have given us much more capability to optimize the network.
The biggest thing I came out of that experience with was an awareness of the fundamental difference in performance that you have to take into account when you move from functional components talking in memory on a single host to talking over a network. When you shift from a monolith to a microservices application, you’re having to rely on the network and you’re putting that change into hyperdrive.
20:24 NGINX Loves Microservices

This is in large part why microservices and NGINX go so well together. It’s really a favorite among the world’s busiest websites for managing HTTP traffic. Most of the 300 million websites that are running NGINX are using it just on the front side of the application. In many of our biggest customers, they’re using NGINX throughout their infrastructure. For example, Netflix uses NGINX for managing HTTP traffic throughout their system.
Many microservices applications use NGINX in that same capacity. One of the reasons that they do is because NGINX is small, fast, and reliable – all of the things that you need for a microservices application.
21:23 Ingenious Photo Site
![The NGINX Microservices Reference Architecture relies on containers, accommodates multiple programming languages, and follows the principles of the 12-Factor App, adapted for a microservices architecture [webinar: Three Models in the NGINX Microservices Reference Architecture]](https://www.nginx.com/wp-content/uploads/2017/02/webinar-3MRAmodels-slide17_ingenious-app.png)
We’ve been working to figure out how to help our customers implement NGINX within their microservices application. So in the last year, alongside the Microservices Reference Architecture we have built a system that we call the Ingenious photosharing site.
It enables you to upload and share photos within your site, sort of like Flickr or Shutterfly. The system is built with six microservices, all using Docker containers. Each of the microservice is written in a different language: Python, Ruby, Node.js, Java, PHP. All of these systems were designed to be polyglot in order to help us prove that our application architecture and the way that we address problems can be applied to whatever language or system that you are using in your environment.
Our application was designed along the Twelve‑Factor App principles. So ephemeral systems. The persistence layer is managed as an attached resource. We designed the application so that it is scalable and manageable as a microservices application.
22:45 The Networking Problem
![Section title slide "The Networking Problem" underlines a challenge to a microservices architecture: the need for microservices to communicate over a network [presentation by Chris Stetson, NGINX Microservices Practice Lead, at nginx.conf 2016]](https://www.nginx.com/wp-content/uploads/2016/10/Stetson-conf2016-slide11_networking_problem.png)
In going through that process of building out our application, and taking all of our experiences that my team and I have accumulated over the years in building applications, we’ve definitely recognized that there are three basic problems that need to be addressed as you change from a monolithic architecture and thought process to a microservices one. The three issues are service discovery, resource utilization (load balancing), and the issues with speed and security that a network‑based application introduces. Let’s go into each of those topics in a little more depth.
23:48 Service Discovery
![Service discovery is a challenge in a microservices architecture that does not apply in a monolithic design and is made more difficult by lack of a standard method [presentation by Chris Stetson, NGINX Microservices Practice Lead, at nginx.conf 2016]](https://www.nginx.com/wp-content/uploads/2017/02/Stetson-conf2016-slide12_svc-discovery.png)
In a monolithic application, as I mentioned before, when you have a functional component that needs to talk to another functional component, you tell the VM that you want a new instance of that component. You make a method call to that component, and it responds. The VM manages all of the instantiation and communication, object reference, connections, and so on, for your application. (Unless you’re writing in C – one of the reasons that C is not the predominant language for writing large‑scale web applications is because those things are hard.)
In a web microservices application, you don’t have a VM that is managing all of the systems and services that make up your application. So your services need a way to find and connect to the other services they are utilizing. Typically that’s done with a service registry of one sort: a key‑value database that enables one service to look up another service.
Say service A wants to talk to service B: it makes a request to the service registry to get the IP address and possibly the port number of service B, and then it creates an HTTP connection to service B.
That is a fairly intense process, and there are many different service registries out there that are quite popular – Consul, etcd, and ZooKeeper are all very popular and are embedded within key‑value store systems for large‑scale microservices applications. So that’s service discovery.
25:56 Load Balancing
![Efficient and sophisticated load balancing like that with NGINX Plus is a requirement for a microservices architecture [webinar: Three Models in the NGINX Microservices Reference Architecture]](https://www.nginx.com/wp-content/uploads/2017/02/webinar-3MRAmodels-slide18_load-balancing.png)
The second problem you need to address is load balancing, or as I like to think of it, resource utilization. If you have three instances of a shopping cart service, you don’t want all the other services to be talking to just one of the instances. You want the requests to be balanced across all of the instances, and do it in a way that optimizes the load balancing.
The standard and most typical way of doing load balancing is a round‑robin approach where you’re just cycling requests through each instance in turn. Unfortunately, that has the downside of potentially having your services overlap on each other. It can having a shotgun effect as multiple services make the same request to the same instance of the shopping cart, causing real problems. Depending on the service in the background, you may want to use a different type of load‑balancing algorithm. So having the choice of algorithm be configurable at the developer level is really beneficial in utilizing your resources appropriately.
27:14 Secure and Fast Communication
![Secure and fast communication is a big challenge in a microservices architecture because SSL/TLS processing is CPU intensive and slows down message exchange [webinar: Three Models in the NGINX Microservices Reference Architecture]](https://www.nginx.com/wp-content/uploads/2017/02/webinar-3MRAmodels-slide19_secure-fast-communication_.png)
The third problem goes back to that searing experience I had with the Microsoft showcase application working over the network. When I design an application, one of the first things I think about is that I need to optimize my request load so that it is as fast as possible. The performance of the network is really indicative of how fast the application is going to work.
On top of that, I also now have to consider all of the data that is being transmitted among my services. Because microservices talk to each other over the network using HTTP with (typically) a JSON payload, you’re essentially exposing all of your application’s data. That is a problem, particularly for regulated industries. The simple solution is to incorporate SSL into your application. Unfortunately, SSL introduces quite a lot of overhead into the request process.
This slide illustrates the SSL process for an Investment Manager service talking to a User Manager service. The Java service in the Investment Manager creates an HTTP client, which makes a request to the service registry to get the DNS value of the User Manager instance that the Investment Manager wants to connect to. The Java service then begins the nine‑step SSL negotiation process, including the key exchange.
That key exchange is actually the most CPU‑intensive part of the process. The Java service establishes the SSL‑encrypted connection, makes the request, gets the response, closes the connection, and finally garbage collects the HTTP client that it created. It repeats that process for every request it makes to every service.
So obviously that can cause a big performance hit just to make your connection secure. It’s a serious issue when you’re looking at millions of requests per hour (or even per second, depending on the scale of your application).
30:13 Solution
![The models in the NGINX Microservices Reference Architecture address the challenges of a microservices architecture by providing service discovery, robust load balancing, and fast encryption [webinar: Three Models in the NGINX Microservices Reference Architecture]](https://www.nginx.com/wp-content/uploads/2017/02/webinar-3MRAmodels-slide20_solution.png)
So we have been building our application architectures to address all three issues. We think that we have come up with architectures that will address the service discovery issue, the load balancing issue, and in particular the fast encryption process so that you essentially don’t have to pay the SSL penalty.
30:40 Network Architectures
![Section title slide reading Network Architectures to introduce the three models in the NGINX Microservices Reference Architecture [presentation by Chris Stetson, NGINX Microservices Practice Lead, at nginx.conf 2016]](https://www.nginx.com/wp-content/uploads/2016/10/Stetson-conf2016-slide16_network-architecture.png)
We have three architectures that we’ve developed to address the microservices networking problem: the Proxy Model, the Router Mesh Model, and the Fabric Model.
They are not mutually exclusive. In fact the Proxy Model, which is the simplest and most straightforward, is incorporated in the Router Mesh Model and the Fabric Model. So keep that in mind that as we go over the models: they are additive.
The mofrld take different approaches to trying to solve the problems, and hopefully by the end you will have a good understanding of how we think architectures can be built that really address all of the issues that we’ve identified.
31:44 Proxy Model
![In the Proxy Model of the NGINX Microservices Reference Architecture, NGINX manages inbound traffic as a reverse proxy and load balancer [webinar: Three Models in the NGINX Microservices Reference Architecture]](https://www.nginx.com/wp-content/uploads/2017/02/webinar-3MRAmodels-slide21_proxy-model.png)
The Proxy Model is really straightforward. Floyd spoke earlier about the reverse proxy use case for NGINX Plus, and that is largely its role in the Proxy Model. In particular, in this model NGINX Plus is managing the inbound traffic from the Internet into your microservices application.
Typically microservices (whether they’re PHP, Python, or Java) have some sort of native HTTP client that they run within the application to handle HTTP REST requests. Those web servers are okay, but they are not designed for large‑scale applications that are facing the Internet and are having to deal with the myriad clients that come and connect, the myriad network speeds and network connections that your Internet users deal with, and they don’t typically have to deal with the bad actors that try and penetrate your network.
NGINX Plus in particular is really well designed to manage that kind of traffic, giving you security controls, performance controls, and really acting as a system to manage that inbound traffic in a high‑performance way.
What makes this particular configuration useful in a microservices environment is that NGINX Plus can do service discovery very reliably and very quickly for your microservices. We are able to connect to the service registry and understand when new instances of the services become available and when they’re closed down, so that we can route to and load balance those systems very effectively.
Service discovery is one of the features that makes NGINX Plus really well suited to a microservice environment. I will be showing more specifics of the service discovery process when we get to the Fabric Model, because that’s where service discovery becomes really critical.
34:27 Proxy Model Summary
![The Proxy Model focuses on traffic coming in from the Internet, acts as a shock absorber of traffic spikes, and provides dynamic connectivity.[webinar: Three Models in the NGINX Microservices Reference Architecture]](https://www.nginx.com/wp-content/uploads/2017/02/webinar-3MRAmodels-slide22_proxy-model-summary.png)
So the Proxy Model is really straightforward: you put a reverse proxy and load balancer in place for your microservices application. In the Proxy Model, NGINX Plus focuses on Internet traffic, acting as a shock absorber for your application. Because it can do dynamic connectivity and dynamic upstream load balancing, it works really well with the scaling issues and the dynamism of a microservice application in the background.
34:54 Router Mesh Model
![In the Router Mesh Model of the NGINX Microservices Reference Architecture, NGINX Plus handles incoming traffic as a reverse proxy and also load balances among the microservices [webinar: Three Models in the NGINX Microservices Reference Architecture]](https://www.nginx.com/wp-content/uploads/2017/02/webinar-3MRAmodels-slide23_router-mesh-model.png)
The Router Mesh Model has the Proxy Model in front of the application, but where it differs from the Proxy Model is that it introduces a centralized load‑balancing system in the microservices application.
The microservices can utilize the power of NGINX Plus to do load balancing and HTTP traffic management within the application itself, giving you a lot of capabilities that make it very powerful.
Specifically, you get a lot of load‑balancing capabilities that you don’t typically get in a microservices application. You are able to do things like leaf‑connection load balancing so we can evaluate all of the connections to all of the services and be able to make intelligent decisions about which service we should route traffic to based on our awareness of all the traffic that is flowing between the services.
NGINX Plus has a load balancing algorithm called Least Time – it routes requests to whichever service instance is responding the fastest.
36:26 Circuit Breakers
![NGINX Plus in the Router Mesh Model implements the circuit breaker pattern with active health checks, request retrying, and caching [webinar: Three Models in the NGINX Microservices Reference Architecture]](https://www.nginx.com/wp-content/uploads/2017/02/webinar-3MRAmodels-slide24_circuit-breaker-pattern.png)
You also have the capability of building in the circuit breaker pattern. Because NGINX Plus has an active health check capability which essentially allows you to evaluate the health of your services, it can cut off all traffic to a service that has indicated that it is unhealthy and shouldn’t receive any more requests.
I previously mentioned the Ingenious app in the Microservices Reference Architecture, which allows you to upload photos and share them.
Ingenious includes a service called the resizer, and it’s the most CPU‑ and memory‑intensive part of the application. When you upload a photo, the resizer has to resize and reorient the data. When you’re talking about a 6000×4000 photo from your new iPhone, that is a lot of data and it is a lot of CPU that has to be utilized.
The health check on the resizer evaluates how much memory the system has, and the resizer marks itself as unhealthy if its memory usage exceeds 80%, so that it will have a chance to recover. NGINX Plus health checks monitor and can evaluate that condition, and it does retries and caching to give you resiliency within your application.
38:27 Router Mesh Model Summary
![[webinar: Three Models in the NGINX Microservices Reference Architecture]](https://www.nginx.com/wp-content/uploads/2017/02/webinar-3MRAmodels-slide25_router-mesh-model-summary.png)
The Router Mesh Model has robust service discovery. It has advanced load balancing for your services within your microservices application, and it give you the ability to build in the circuit breaker pattern without your developers having to implement it themselves in their code.
38:51 Fabric Model
![The Fabric Model of the NGINX Microservices Reference Architecture is a microservices architecture that provides routing, forward proxy, and reverse proxy at the container level and establishes persistent connections between services [webinar: Three Models in the NGINX Microservices Reference Architecture]](https://www.nginx.com/wp-content/uploads/2017/02/webinar-3MRAmodels-slide26_fabric-model.png)
The Fabric Model is the architecture that really addresses all three issues that I mentioned: service discovery, load balancing, and fast encryption. It does this by flipping load balancing on its head. Rather than having a centralized load balancer, which is the typical configuration for load balancing, what we have done is push load balancing down to the container level.
Essentially what you have is NGINX Plus living in each container of each microservice, and all of the traffic going in and out of the microservice is routed through NGINX Plus. There are a lot of advantages to that, as we’ll explore in the next slides.
39:45 Normal Process
![In a standard microservices architecture, a client first makes a DNS request to the service registry, then uses the addresses obtained to establish an SSL/TLS connection to the service [webinar: Three Models in the NGINX Microservices Reference Architecture]](https://www.nginx.com/wp-content/uploads/2017/02/webinar-3MRAmodels-slide27_normal-process.png)
Let’s quickly review the normal process for securing traffic between microservices, then we’ll contrast that with the way that works within the Fabric Model. In the normal process, the Java service in the Investment Manager creates an HTTP client, then it does a request to the service registry to get the IP address of the User Manager instance it wants to connect to. It begins the SSL handshake process which takes nine steps. It establishes the connection, makes the request, gets a response, closes the connection, and then it garbage collects the HTTP client.
So that whole process is fairly straightforward and it’s done millions of times per hour in a typical microservices application.
40:44 Fabric Model In Detail
![In the Fabric Model of the NGINX Microservices Reference Architecture, NGINX Plus runs in every service to establish local persistent connections and maintain service discovery information [webinar: Three Models in the NGINX Microservices Reference Architecture]](https://www.nginx.com/wp-content/uploads/2017/02/webinar-3MRAmodels-slide28_fabric-model-detail.png)
In the Fabric Model, we’ve changed that around quite a bit. What we have here is the Java service talking in localhost to NGINX Plus, and NGINX Plus talking to NGINX Plus in each of the User Manager instances. Specifically, the Java service creates its HTTP client and makes a localhost request to the local instance of NGINX Plus, but it doesn’t have to do a DNS lookup.
It also can work over HTTP, so it doesn’t have to do the SSL connection. In the meantime, NGINX Plus has been periodically going to the service registry to learn about all instances of the User Manager that are available. It’s keeping that list in a load‑balancing pool and repeating the request once every three seconds or so to keep the load‑balancing pool fresh.
It’s pre‑establishing connections to the User Manager instances over SSL and using the HTTP keepalive protocol to maintain [keep open] those connections. Then the Java service simply uses that tunnel [existing keepalive connection] over to the User Manager instance to send a request to the User Manager and get a response back.
So in our experience, the performance increase is approximately 77% faster for that kind of connection than if you were doing it over plain SSL in the manner that I described earlier.
42:35 Circuit Breaker Pattern
On top of that you get the circuit breaker capability that I described before, with active health checks happening between the different systems and an ability to do retries and caching. Because the load balancing is built into each of the containers, the developers have a lot of capability to customize the response and management of the circuit breaker pattern within the application.
43:02 Fabric Model Summary
![The Fabric Model provides robust service discovery, advanced load balancing, the circuit breaker pattern, and persistent SSL connections [webinar: Three Models in the NGINX Microservices Reference Architecture]](https://www.nginx.com/wp-content/uploads/2017/02/webinar-3MRAmodels-slide29_fabric-model-summary.png)
The Fabric Model really addresses the service‑discovery issue and it gives you a lot of load‑balancing capability.
To expand on load balancing a bit, within the Fabric Model NGINX Plus’ Least Time load‑balancing algorithm is really powerful for managing traffic within an application.
Least Time evaluates which service is responding the fastest, and it will bias the request load to the local instances of the services that it is connecting to. So if you happen to have a User Manager instance running on the same host as an Investment Manager service [which typically makes for very fast response times], Least Mode biases requests to go to the local User Manager instance, increasing the performance of that connection significantly.
Least Time uses a moving average algorithm, so it does still distribute the requests around. This means that if the local instance does become overloaded and slows down, Least Time reroutes to other instances automatically.
You also also get the circuit breaker pattern, and you get that persistent SSL network so that you don’t have to keep recreating SSL connections between all of your systems.
44:31 NGINX and Microservices
Floyd Smith: Thank you, Chris. I’m putting up this slide again to link to some of the resources we have available and trainings that are coming up.
I also wanted to point out some of the performance gains from the models, especially the Fabric Model, that might not be immediately apparent.
As I studied the models, one of the things that I finally caught onto is that the pool of service instances that are available for communication is updated perhaps once every one or two seconds, but the communication between instances can happen many hundreds of times per second. That’s where you get the performance advantage. You only snoop once every couple of seconds, but you use the information that you snooped for a lot of times.
There are also the persistent connections that Chris described, which eliminate the overhead that’s usually associated with SSL. There are a lot of details like these in each of the models that you see as you really dig into them.
That points out one of the advantages of microservices that I think at this point is overlooked. People move a monolith to microservices to get the immediate advantages we’ve mentioned, but you really get the advantages as you write your second, third, and fourth microservices applications. At that point you have a set of reliable services and a lot of architectural understanding. Then you get to be able to do amazing things amazingly quickly. So we’re all in the discovery phase here, and there’s a lot of goodness coming up if you stay with it.
So here again is the list of microservices‑oriented resources if you want to dig in further. There’s also a long book chapter in a book called AOSA [The Architecture of Open Source Applications] for a great description of how NGINX really works and how it fits into all of this.
In addition to all of the resources here, I also want to mention again that we will have an AMA coming up. So if we don’t get to your question today, we’ll have an opportunity to answer your questions.
47:41 Questions
![Section title slide for questions [webinar: Three Models in the NGINX Microservices Reference Architecture]](https://www.nginx.com/wp-content/uploads/2017/02/webinar-3MRAmodels-slide30_questions.png)
Q: How do you sell microservices to your colleagues?
Chris: I think that the best way is to really focus on the use cases that you need to address. Look at the kinds of traffic and the kinds of business or organizational requirements that you need to address.
For example, if you’re in a regulated industry and need to encrypt your data in motion – you need HIPAA compliance, or are in a PCI/fiserv environment, or are a government agency – the Fabric Model is a good solution for you.
If you have an application that really needs effective load balancing and you really don’t need to have encryption other than SSL termination at the edge, then the Router Mesh Model is often a good solution for you.
If you just want to get started with microservices and you want to make sure that your internet traffic is managed appropriately, the Proxy Model is a great way to get started with NGINX Plus, knowing that it can help you scale your microservices application without having to do any sort of re‑architecture in the application itself.
Q: What use cases are best suited for each model? How would one decide which model to deploy and when would one migrate from one model to another?
Floyd: I see this question best answered by a 3×3 matrix. On the bottom, you have the three models: Proxy, Router Mesh, and Fabric. On the left axis you have your organizational preparation to deal with the complexities of having to deal with microservices.
So if you are just beginning with microservices, you may want to consider using the Proxy Model whether it’s the ultimate best model for your app or not. It’s just a great place to start the move from a monolith to microservices.
As you get more sophisticated, you can then consider moving to the Router Mesh model, adding an additional NGINX Plus server and getting additional control capabilities. You’ll be able to configure one set of NGINX Plus instances as a reverse proxy server for security, and another set in the middle of the router mesh for microservices management.
But then as your organization abilities increase, you can consider the Fabric Model. I tend to take the reverse approach – why wouldn’t someone want secure communications between microservices, whether they’re in a regulated industry or not? No one wants to get hacked, and no one wants to see themselves as not having been ready when an attack comes.
But in many cases, you can’t just jump into the Fabric Model without help. NGINX, Inc. does offer professional services from the team led by Chris. So we’re here to help, but I think that it will take time for organizations to get to the point where they can move freely among the different models depending on the needs of the particular app and the development level of that app.
If you’re doing something new and you’re not sure how many resources to put into it yet, implement the Proxy Model. Set it up, get it going, and see what kind of feedback you get from users. Then you can consider where to go both with that app and with your own organizational learning.
Chris: The different models are very useful depending on the context of your application. I think that in many respects, once you’ve become sophisticated enough and have an understanding of the networking and organization of the application, the Fabric Model really addresses the issues the best.
Q: Do the different models work with JSON Web Tokens (JWTs)? Is there a reference model for that?
Chris: The latest version of NGINX Plus actually has JWT decryption built in. [Editor – This capability is included in NGINX Plus R10 and later.] You’re able to pass and understand JWTs as they’re passed within the environment, and in fact in the Reference Architecture we have a very similar mechanism to do OAuth authentication at the edge and then pass that user information throughout the application.
The MRA is a system that we are building out to be open sourced. Expect to see that happen in the relatively near future where you can see how we’re utilizing a similar mechanism to the JWT format.
Q: Could you show me a config with NGINX Plus with a real example?
Floyd: That is what the Reference Architecture will include when we open source it in the near future.
Q: What microservices features are available in NGINX versus NGINX Plus?
Chris: One feature that NGINX Plus provides for microservices is service discovery, which is really about being able to dynamically add and subtract instances in a load‑balancing pool. Being able to dynamically add and subtract instances in a load‑balancing pool by querying the service registry is a very powerful feature of NGINX Plus and makes it very well suited for the dynamic aspect of a microservices application.
The second feature that’s very powerful and unique to NGINX Plus (not open source NGINX) is the active health checks. Our ability to actively check the health of individual services allows us to build circuit breaker pattern into the Router Mesh and Fabric models. We are going to be releasing the first version of the MRA as an open source version, so it won’t have dynamic updating of the load‑balancing pool and it won’t have the active health checks.
However, you can get it up and running and see how the system works. You will also be able to replace open source NGINX with NGINX Plus in that environment, so that you can see the benefits from NGINX Plus.
Floyd: I will also add that NGINX Plus adds support. With the scale of resources that go into developing a robust microservices application, you definitely would want support for any major piece of your architecture, and NGINX is definitely a major piece of any of these architectures. So consider the support as well when you’re think about which version to use.
You can still use either version of the software within a model, but NGINX Plus gets a different kind of support because it gets regular releases. We can be more precise and incisive and fast with our support answers, and in a production environment that can be vital.
Q: How do you deal with local development versus production environments with these kinds of architectures?
Chris: That’s a really good question. Depending on the environment that you’re working in, it can be more or less easy to do. For example, if you’re working with Kubernetes and you use Minikube, the Fabric Model will work especially well.
When going through the process of building out the local instances of your container and connecting to remote resources, we often use an environment variable to switch between running the Fabric Model or not. We have a number of different approaches depending on your production environment and your development environment, but for the most part it’s a pretty straightforward process.
This post is adapted from a webinar by Chris Stetson and Floyd Smith, available for viewing on demand.
You can also download our ebook, Microservices Reference Architecture, which covers the models in greater detail, along with other topics.
Have specific questions about microservices? Sign up for our upcoming Ask Me Anything session about the Microservices Reference Architecture!

