

Editor – The blog post titled “Do I Need a Service Mesh?” redirects here.
This post is part of a 10-part series:
- Reduce Complexity with Production-Grade Kubernetes
- How to Improve Resilience in Kubernetes with Advanced Traffic Management
- How to Improve Visibility in Kubernetes
- Six Ways to Secure Kubernetes Using Traffic Management Tools
- A Guide to Choosing an Ingress Controller, Part 1: Identify Your Requirements
- A Guide to Choosing an Ingress Controller, Part 2: Risks and Future-Proofing
- A Guide to Choosing an Ingress Controller, Part 3: Open Source vs. Default vs. Commercial
- A Guide to Choosing an Ingress Controller, Part 4: NGINX Ingress Controller Options
- How to Choose a Service Mesh (this post)
- Performance Testing NGINX Ingress Controllers in a Dynamic Kubernetes Cloud Environment
You can also download the complete set of blogs as a free eBook – Taking Kubernetes from Test to Production.
In recent years, service mesh adoption has steadily moved from the bleeding edge to the mainstream as organizations deepen investment in microservices and containerized apps. The Cloud Native Computing Foundation’s 2020 survey about use of cloud‑native technologies leads us to the following conclusions.
Takeaway #1: Service mesh adoption is rising rapidly.
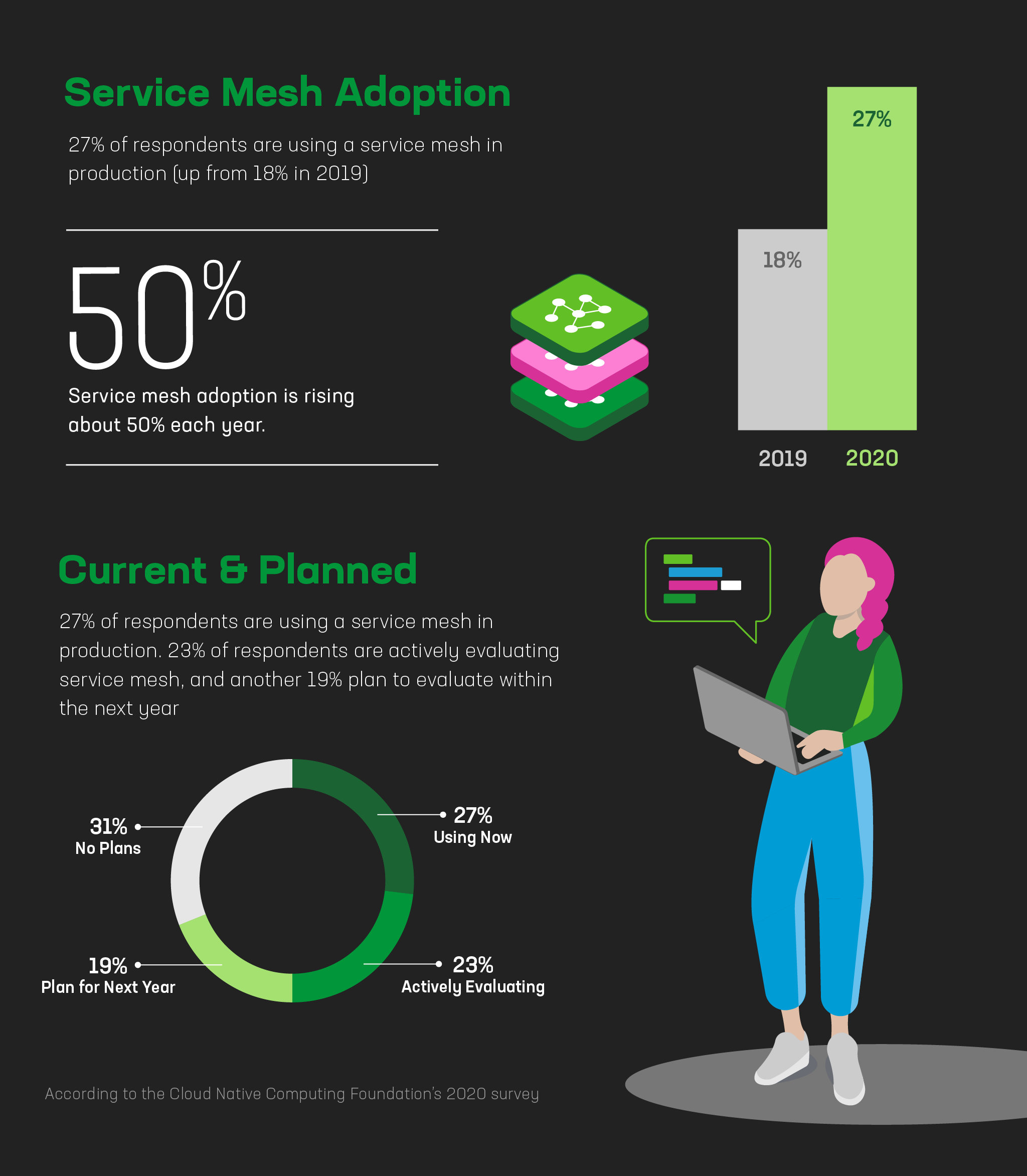
Takeaway #2: Increased use of containers indicates more organizations need advanced traffic management and security tools, and can potentially benefit from a mesh.

Takeaway #3: Three of the top challenges in containers are interrelated.

Are You Ready for a Service Mesh?
At NGINX, we think it’s no longer a binary question of “Do I have to use a service mesh?” but rather “When will I be ready for a service mesh?” We believe that anyone deploying containers in production and using Kubernetes to orchestrate them has the potential to reach the level of app and infrastructure maturity where a service mesh adds value.
But as with any technology, implementing a service mesh before you need one just adds risk and expense that outweigh the possible benefits to your business. We use this 6‑point checklist with customers who are interested in adopting a service mesh, both to determine readiness and to gain an understanding of the modernization journey. The more statements are true for you, the more a service mesh will add value.

#1: You are fully invested in Kubernetes for your production environment.
Whether you’ve already moved production apps into Kubernetes or you’re just starting to test app migration to container workloads, your long‑term application management roadmap includes Kubernetes.
#2: You require a zero‑trust production environment and need mutual TLS (mTLS) between services.
You either already rely on a zero‑trust model for your production apps and need to maintain that level of security in your containerized environment, or you’re using the migration as a forcing function to increase your service‑level security.
#3: Your app is complex in both number and depth of services.
You have a large, distributed app. It has multiple API dependencies and most likely requires external dependencies.
#4: You have a mature, production CI/CD pipeline.
“Mature” depends on your organization. We apply the term to procedures that programmatically deploy Kubernetes infrastructure and apps, likely using tools including Git, Jenkins, Artifactory, or Selenium.
#5: You are deploying frequently to production – at least once per day.
This is where we find most people answer “no” – although they’ve moved apps into production Kubernetes, they aren’t yet using Kubernetes for the dream goal of constant revisions.
#6: Your DevOps team is ready to rock and start using the right tools for ultra‑modern app deployment!
Even if the service mesh is going to be owned by your NetOps team, administration is often handled within the cluster by DevOps teams and they need to be ready to handle the addition of a mesh to their stack.
Didn’t answer “yes” to all six statements? That’s ok! Keep reading to get an idea of where your journey will head once you’re ready, including what you can do to prepare your team for a service mesh.
How to Choose the Service Mesh That’s Right for Your Apps
Once you’ve decided that you’re ready for a service mesh, there’s still a wide variety from which to choose. Much like Kubernetes has become the de facto container orchestration standard, Istio is often seen as the de facto service mesh standard. In fact, it’s easy to think that Istio is the only choice, not just because of its prevalence but also because it aims to solve just about every problem in the Kubernetes networking world. At the risk of sound self‑serving, we’re here to tell you that Istio isn’t the only choice, nor is it the right choice for everyone or every use case. Istio adds a lot of complexity to your environments, can require an entire team of engineers to run it, and often ends up introducing more problems than it solves.
To get clear on which service mesh is best for your apps, we recommend a strategic planning session with your team and stakeholders. Here’s a conversation guide to help you facilitate these discussions.
Step 1: Why are you looking for a service mesh?
In other words, what problems do you need the service mesh to solve? For example, your organization might mandate mTLS between services or you need end-to-end encryption, including both from the edge in (for ingress traffic) and from within the mesh (for egress traffic). Or perhaps you need enterprise‑grade traffic management tools for your new Kubernetes services.
Step 2: How will you use the service mesh?
This depends on who you are.
-
If you’re a developer:
- Do you plan to add security to a legacy app that is moving into Kubernetes?
- Are you going to incorporate security as you refactor an app into a native Kubernetes app?
-
If you’re responsible for platforms and infrastructure:
- Are you going to add the service mesh into your CI/CD pipeline so that it’s automatically deployed and configured with every new cluster and available when a developer spins up a new instance?
Step 3: What factors influence your selection?
Does your service mesh need to be infrastructure agnostic? Compatible with your visibility tools? Kubernetes‑native? Easy to use? Do you see a future when you’ll want to manage ingress and egress (north‑south) traffic at the edge with the same tool as service-to-service (east‑west) traffic within the mesh?
Once you’ve worked through these questions, you’ll have a solid list of requirements to use as you evaluate options.
How NGINX Can Help
We’re excited to announce that NGINX Service Mesh – introduced as a development release in 2020 – is officially production‑ready! NGINX Service Mesh is free, optimized for developers, and the lightest, easiest way to implement mTLS and end-to-end encryption in Kubernetes for both east‑west (service-to-service) traffic and north‑south (ingress and egress) traffic. We’ve built our own service mesh because we want to give you full control of the application data plane in the way that’s least intrusive but still provides advanced flexibility and critical insights.
We think you’ll like NGINX Service Mesh if need a mesh that is:
- Easy to use. You’re going to manage the service mesh and don’t want to mess around with a complicated set of tools just to add mTLS and advanced traffic management to an already complex Kubernetes environment.
- Lightweight. You want a component that won’t drain your resources or impact performance.
- Infrastructure‑agnostic. You’re planning to use the same service mesh across all your Kubernetes environments.
- Compatible with your ecosystem. You need a Kubernetes‑native service mesh that integrates with your Ingress controller and visibility tools without adding latency.
About the Architecture
NGINX Service Mesh has two main components.
The Control Plane
We built a lightweight control plane that provides dynamic support and management of apps in partnership with the Kubernetes API server. It reacts to and updates apps as they scale and deploy so that each workload instance automatically stays protected and integrated with other app components – letting you “set it and forget it” and spend your time on valuable business solutions.
The Data Plane
The real star of NGINX Service Mesh is the fully integrated, high‑performance data plane. Leveraging the power of NGINX Plus to operate highly available and scalable containerized environments, our data plane brings a level of enterprise traffic management, performance, and scalability to the market that no other sidecars can offer. It provides the seamless and transparent load balancing, reverse proxy, traffic routing, identity, and encryption features needed for production‑grade service mesh deployments. When paired with the NGINX Plus-based version of NGINX Ingress Controller, it provides a unified data plane that can be managed with a single configuration.
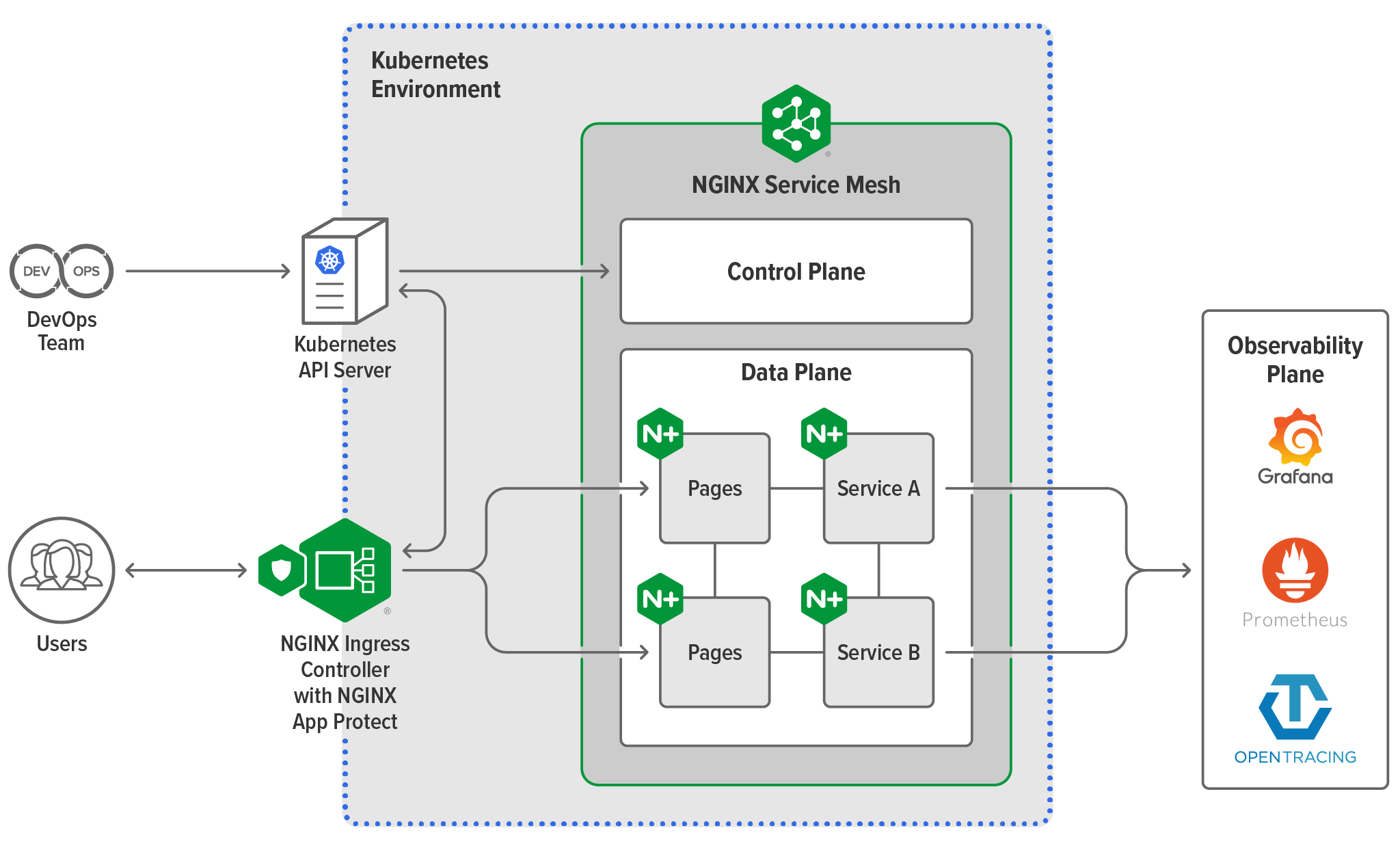
NGINX Service Mesh Benefits
You can expect several benefits from NGINX Service Mesh.
Less Complexity
NGINX Service Mesh is easy to use and infrastructure agnostic. It implements the Service Mesh Interface (SMI) specification, which defines a standard interface for service meshes on Kubernetes, and provides SMI extensions that make it possible to roll out a new app version with minimal effort and interruption to production traffic. NGINX Service Mesh also integrates natively with NGINX Ingress Controller, creating a unified data plane where you can centralize and streamline configuration of ingress and egress (north‑south) traffic management at the edge with service-to-service (east‑west) reverse proxy sidecar traffic management. And unlike other meshes, NGINX Service Mesh doesn’t need to inject a sidecar into NGINX Ingress Controller, so it doesn’t add latency and complexity to your Kubernetes environments.
Improved Resilience
With our intelligent management of container traffic, you can specify policies that limit traffic to newly deployed service instances and slowly increase it over time. Capabilities like rate limiting and circuit breakers give you full control over the traffic flowing through your services. You can leverage a robust range of traffic distribution models, including rate shaping, quality of service (QoS), service throttling, blue‑green deployments, canary releases, circuit breaker pattern, A/B testing, and API gateway features.
Learn more in our blog How to Improve Resilience In Kubernetes with Advanced Traffic Management and watch this demo by NGINX engineer Kate Osborn on how to use NGINX Service Mesh for traffic splitting.
Fine-Grained Traffic Insights
NGINX Service Mesh is instrumented for metrics collection and analysis using OpenTracing and Prometheus. The NGINX Plus API generates metrics from NGINX Service Mesh sidecars and NGINX Ingress Controller pods. Use the built‑in Grafana dashboard to visualize metrics with detail down to the millisecond, day-over-day overlays, and traffic spikes.
Learn more in our blog How to Improve Visibility in Kubernetes and check out this live stream showing how to use Prometheus and Grafana with NGINX.
Secure Containerized Apps
Extend mTLS encryption and Layer 7 protection all the way down to individual microservices and leverage access controls to define policies which describe the topology of your application – giving you granular control over which services are authorized to talk with each other. NGINX Service Mesh enables advanced security features including configuration gating and governance, and allowlist support for ingress and egress and service-to-service traffic. With the NGINX Plus-based version of NGINX Ingress Controller, you also get default blocking of north‑south traffic to internal services, and edge firewalling with NGINX App Protect.
Check out this demo by NGINX engineer Aidan Carson on using access control to manage a zero‑trust environment with end-to-end encryption.
Not Ready for a Service Mesh?
If you aren’t yet ready for a mesh, then you’re probably new to Kubernetes or you’re hitting blockers that are preventing you from large production deployments. This is a great time to work on employing two‑data plane components – the Ingress controller and built‑in security – to address common Kubernetes challenges around complexity, security, visibility, and scalability. Read more in our blog Reduce Complexity with Production‑Grade Kubernetes.
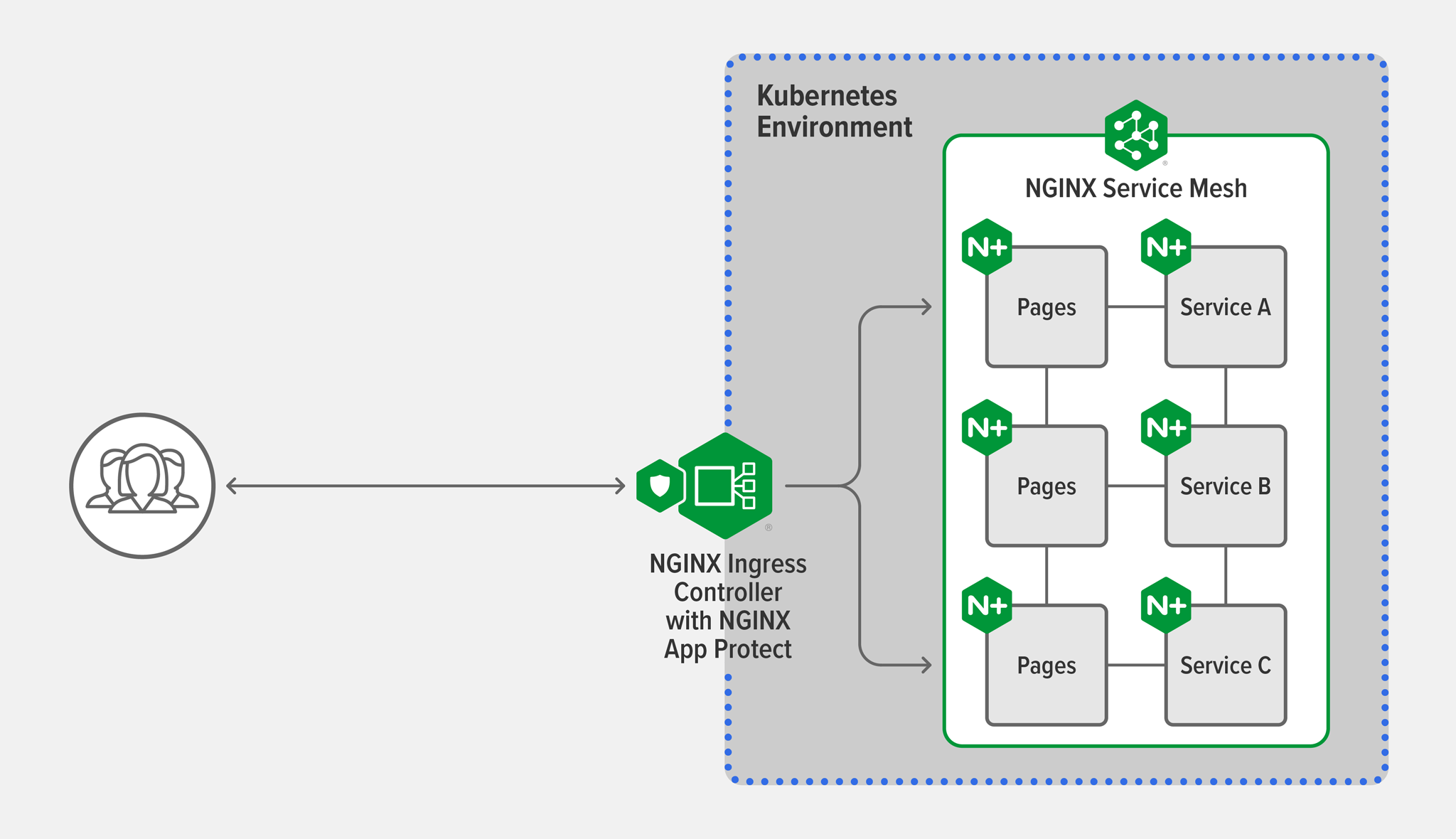
Get Started Today
Join our upcoming webinar, Are You Service Mesh Ready? Moving from Consideration to Implementation, for a deeper dive into how to choose a service mesh!
NGINX Service Mesh is completely free and available for immediate download and can be deployed in less than 10 minutes! To get started, check out our docs and watch this short demo by Product Manager Alan Murphy. We’d love to hear how it goes for you, so please give us your feedback on GitHub.
If it turns out that Istio is the best fit for your needs, check out F5’s Aspen Mesh. It’s an enterprise‑grade service mesh built on top of open source Istio. With a real‑time traffic GUI, it’s particularly great for service providers seeking to deliver 5G.


