We’re happy to announce the availability of NGINX Plus Release 29 (R29). Based on NGINX Open Source, NGINX Plus is the only all-in-one software web server, load balancer, reverse proxy, content cache, and API gateway.
New and enhanced features in NGINX Plus R29 include:
- Support for MQTT protocol– Message Queuing Telemetry Transport (MQTT) is a lightweight protocol used for communication between devices in the Internet of Things (IoT). NGINX Plus R29 supports the MQTT protocol with Preread and Filter modules that introduce multiple new directives and variables to help manage and secure MQTT traffic.
- SAML support for authentication and authorization – Security Assertion Markup Language (SAML) is a well-established protocol that provides single sign-on (SSO) to web applications. NGINX Plus can now be configured as a SAML service provider (SP) to authenticate users against a SAML identity provider (IdP).
- Native OpenTelemetry – OpenTelemetry (OTel) is a framework that generates, collects, and exports telemetry data (traces, metrics, and logs) from remote sources in a vendor-agnostic way. The new NGINX OTel dynamic module provides a high-performance OTel implementation for NGINX Plus HTTP request tracing.
- Experimental QUIC+HTTP/3 packages – Preview packages of NGINX Plus R29 with QUIC+HTTP/3 are now available. The NGINX Plus R29 QUIC packages provide support for HttpContext and a range of new directives to manage QUIC connections and HTTP/3 traffic.
Important Changes in Behavior
Note: If you are upgrading from a release other than NGINX Plus R28, be sure to check the Important Changes in Behavior section in previous announcement blogs for all releases between your current version and this one.
Changes to Packaging Repository
The old package repository plus-pkgs.nginx.com is immediately decommissioned with the release of NGINX Plus R29. This repository has not been updated since NGINX Plus R25 and you are strongly advised to use the pkgs.nginx.com package repository that was introduced in NGINX Plus R24.
Changes to Platform Support
New operating systems supported:
Older operating systems removed:
- Alpine 3.13, which reached end-of-life (EOL) on November 1, 2022
Older operating systems deprecated and scheduled for removal in NGINX Plus R30:
- Ubuntu 18.04, which will reach EOL in June 2023
- Alpine 3.14, which will reach EOL in May 2023
Adapting to the ModSecurity End-of-Life Announcement
In line with the ModSecurity EOL announcement, NGINX Plus R29 removes support of ModSecurity packages. If you are a NGINX Plus customer using ModSecurity packages, you will soon be able to opt-in to a trade-in program between ModSecurity and NGINX App Protect. Details on this will be available soon and you can reach out to your contact at F5 for more information.
New Features in Detail
Support for MQTT Protocol
MQTT (Message Queuing Telemetry Transport) is a popular and lightweight publish-subscribe messaging protocol, ideal for connecting IoT devices and applications (clients) over the internet. It allows clients to publish messages to a specific topic and subscribe to other topics. Subscribed clients receive all messages published to that topic, enabling efficient and fault-tolerant data exchange between many devices and services.
At the heart of an MQTT architecture is a broker. A broker is a server responsible for tracking clients and any topics they’re subscribed to, processing messages, and routing those messages to appropriate systems. NGINX Plus R29 supports MQTT 3.1.1 and MQTT 5.0. It acts as a proxy between clients and brokers, which simplifies system architecture, offloads tasks, and reduces costs.
The initial MQTT feature set enables:
- MQTT broker load balancing
- Session persistence (reconnecting clients to the same broker)
- TLS termination
- Client certificate authentication
- CONNECT message parsing and rewriting
The MQTT protocol defines several message types, including CONNECT, PUBLISH, and SUBSCRIBE. NGINX Plus R29 can actively parse and rewrite portions of MQTT CONNECT messages, enabling configuration scenarios previously only possible with custom scripts.
MQTT message parsing and rewriting must be defined in the Stream context of an NGINX configuration file and is made possible with the ngx_stream_mqtt_preread_module
and ngx_stream_mqtt_filter_module modules.
MQTT Examples
Modifying the default client identifier sent by an MQTT device enables NGINX to hide sensitive information, such as a device’s serial number. In this first example, the identifier is rewritten to the device’s IP address.
Note: Using a device’s IP address as the MQTT client identifier is not recommended in a production environment.
stream {
mqtt on;
server {
listen 1883;
proxy_pass 10.0.0.8:1883;
mqtt_set_connect clientid '$remote_addr';
}
}
Given the ephemeral nature of MQTT clients, you can’t simply rely on a device’s hostname or IP address for establishing sticky sessions to load balanced brokers. In this example, a device’s MQTT client identifier acts as a hash key for persisting connections to individual MQTT brokers in a load balanced cluster:
stream {
mqtt_preread on;
upstream brokers{
zone tcp_mem 64k;
hash $mqtt_preread_clientid consistent;
server 10.0.0.7:1883; # mqtt broker 1
server 10.0.0.8:1883; # mqtt broker 2
server 10.0.0.9:1883; # mqtt broker 3
}
server {
listen 1883;
proxy_pass brokers;
proxy_connect_timeout 1s;
}
}
Next Steps
Future developments to MQTT in NGINX Plus may include parsing of other MQTT message types, as well as deeper parsing of the CONNECT message to enable functions like:
- Additional authentication and access control mechanisms
- Protecting brokers by rate limiting “chatty” clients
- Message telemetry and connection metrics
We would love to hear your feedback on the features that matter most to you. Let us know what you think in the comments.
SAML Support for Authentication and Authorization
SAML (Security Assertion Markup Language) is an open federation standard that allows an identity provider (IdP) to authenticate users for access to a resource (ensuring the end user is, in fact, who they claim to be) and to pass that authentication information, along with the user’s access rights on that resource, to a service provider (SP) for authorization.
With a long track record of providing a secure means to exchange identity data, SAML is a widely adopted protocol for exchanging authentication and authorization information between an IdP and SP.
Key reasons enterprises and government institutions choose to adopt SAML include:
- Effective management of a large volume of identities
- Enhanced, consistent, and unified identity security to customers and employees
- Improved operational efficiencies via standardizing identity management processes
- Efficient handling of regulatory compliances
SAML also provides several benefits:
- Better User Experience: With its SSO integration and single point of authentication verification at the IdP, SAML enables users to have one authentication that accesses all connected services. This improves user experience and saves time because users no longer need to remember multiple credentials for various applications.
- Increased Security: Depending on your organization’s security and authentication policies, users can log in using an SSO authentication scheme either at the SP interface (SP-initiated SSO) or directly at the IdP interface (IdP-initiated SSO). This reduces security risks due to potentially weak and/or repeating passwords.
- Reduced Administrative Costs: SAML helps organizations offload the identity management responsibilities to a trusted IdP, thereby reducing the cost of maintaining account information and associated expenses.
- Standardized Protocol: Designed with the principle of making security independent of application logic (as much as possible), SAML is a standardized protocol that is supported by almost all IdPs and access management systems. It abstracts the security framework away from platform architectures and particular vendor implementations, which enables robust security and reliable integration between systems.
The current reference implementation of SAML uses SAML 2.0 and is built using the NGINX JavaScript (njs) framework. In this implementation, NGINX Plus acts as a SAML SP, allowing it to participate in an SSO setup with a SAML IdP. The current implementation also depends on the key-value store, which is an existing NGINX Plus feature and, as such, is not suitable for NGINX Open Source without additional modifications.
SAML support in NGINX Plus is available as a reference implementation on GitHub. The GitHub repo includes a sample configuration with instructions on installation, configuration, and fine‑tuning for specific use cases.
Native OpenTelemetry
OpenTelemetry (OTel) is a technology and standard that can be used for monitoring, tracing, troubleshooting, and optimizing applications. OTel works by collecting telemetry data from various sources, such as proxies, applications, or other services in a deployed application stack.
As a protocol-aware reverse proxy and load balancer, NGINX is ideally positioned to initiate telemetry calls for tracing application requests and responses. While third-party OTel modules have been available for some time, we’re excited to announce native support for OTel in NGINX Plus with a new dynamic module.
The new module ngx_otel_module can be installed using the nginx-plus-module-otel package and provides several key improvements to third-party modules, including:
- Better Performance – Most OTel implementations reduce performance of request processing by up to 50% when tracing is enabled. Our new native module limits this impact to around 10-15%.
- Easy Provisioning – Setting up and configuring the telemetry collection can be done right in the NGINX configuration files.
- Fully Dynamic Variable-Based Sampling – The ability to trace a particular session by cookie/token and control the module dynamically via the NGINX Plus API and key-value store modules.
More details about the OTel dynamic module are available in the NGINX documentation.
OTel Tracing Examples
Here is an example of basic OTel tracing of an application served directly by NGINX:
load_module modules/ngx_otel_module.so;
events {}
http {
otel_exporter {
endpoint localhost:4317;
}
server {
listen 127.0.0.1:8080;
otel_trace on;
otel_span_name app1;
}
}
In this next example, we inherit trace contexts from incoming requests and record spans only if a parent span is sampled. We also propagate trace contexts and sampling decisions to upstream servers.
load_module modules/ngx_otel_module.so;
http {
server {
location / {
otel_trace $otel_parent_sampled;
otel_trace_context propagate;
proxy_pass http://backend;
}
}
}
In this ratio-based example, tracing is configured for a percentage of traffic (in this case 10%):
http {
# trace 10% of requests
split_clients "$otel_trace_id" $ratio_sampler {
10% on;
* off;
}
# or we can trace 10% of user sessions
split_clients "$cookie_sessionid" $session_sampler {
10% on;
* off;
}
server {
location / {
otel_trace $ratio_sampler;
otel_trace_context inject;
proxy_pass http://backend;
}
}
}
In this API-controlled example, tracing is enabled by manipulating the key-value store via the /api endpoint:
http {
keyval "otel.trace" $trace_switch zone=name;
server {
location / {
otel_trace $trace_switch;
otel_trace_context inject;
proxy_pass http://backend;
}
location /api {
api write=on;
}
}
}
Experimental QUIC+HTTP/3 Packages
Following our announcement of preview binary packages for NGINX Open Source, we are pleased to announce experimental QUIC packages for NGINX Plus R29. This makes it possible to test and evaluate HTTP/3 with NGINX Plus.
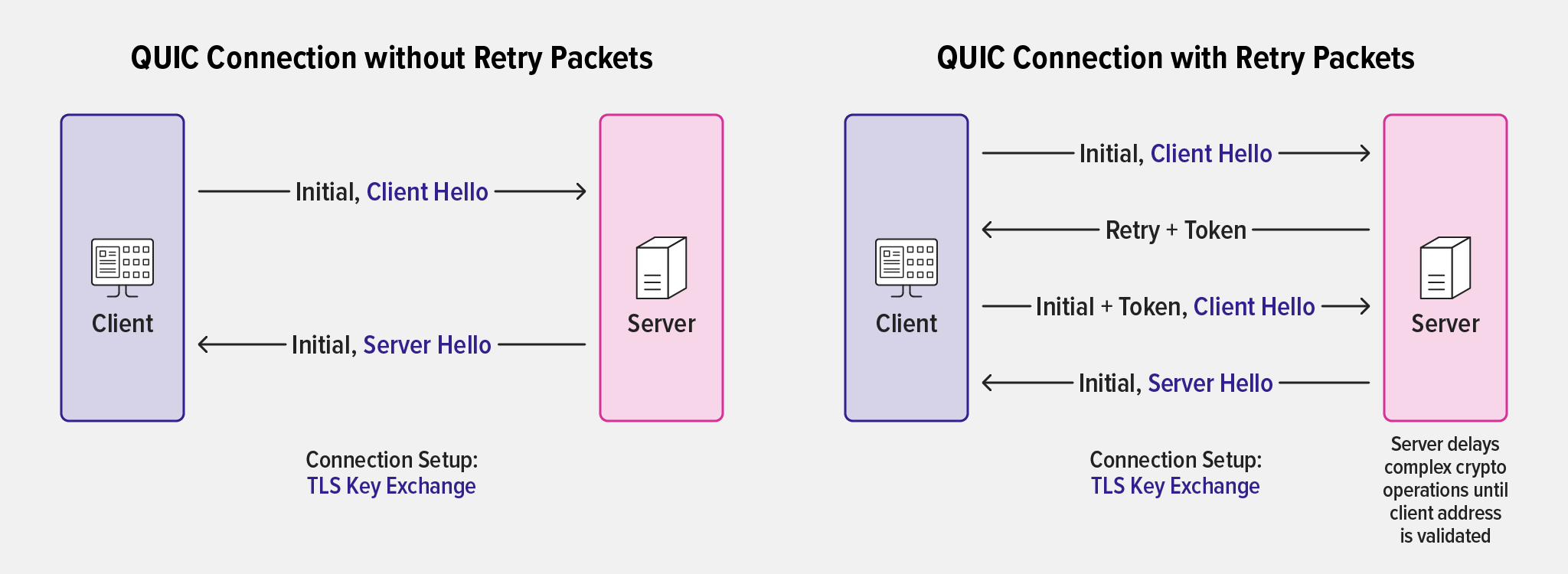
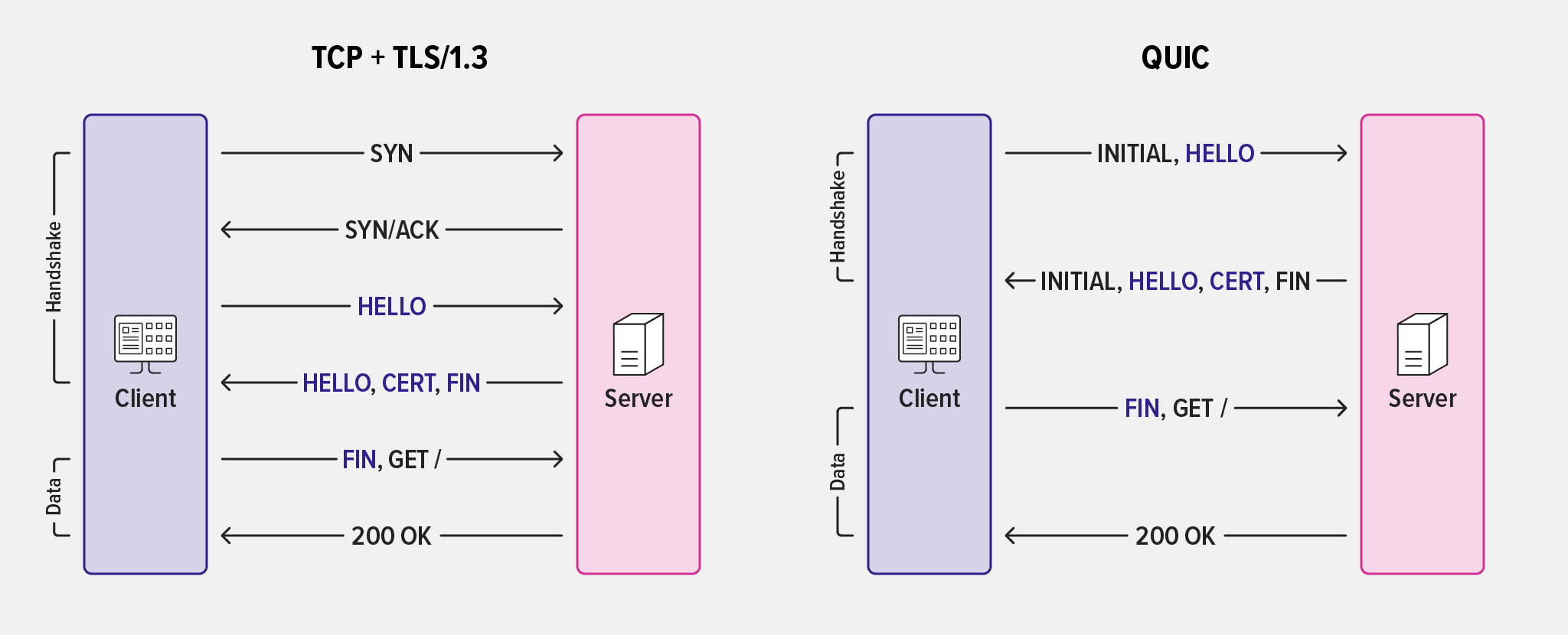
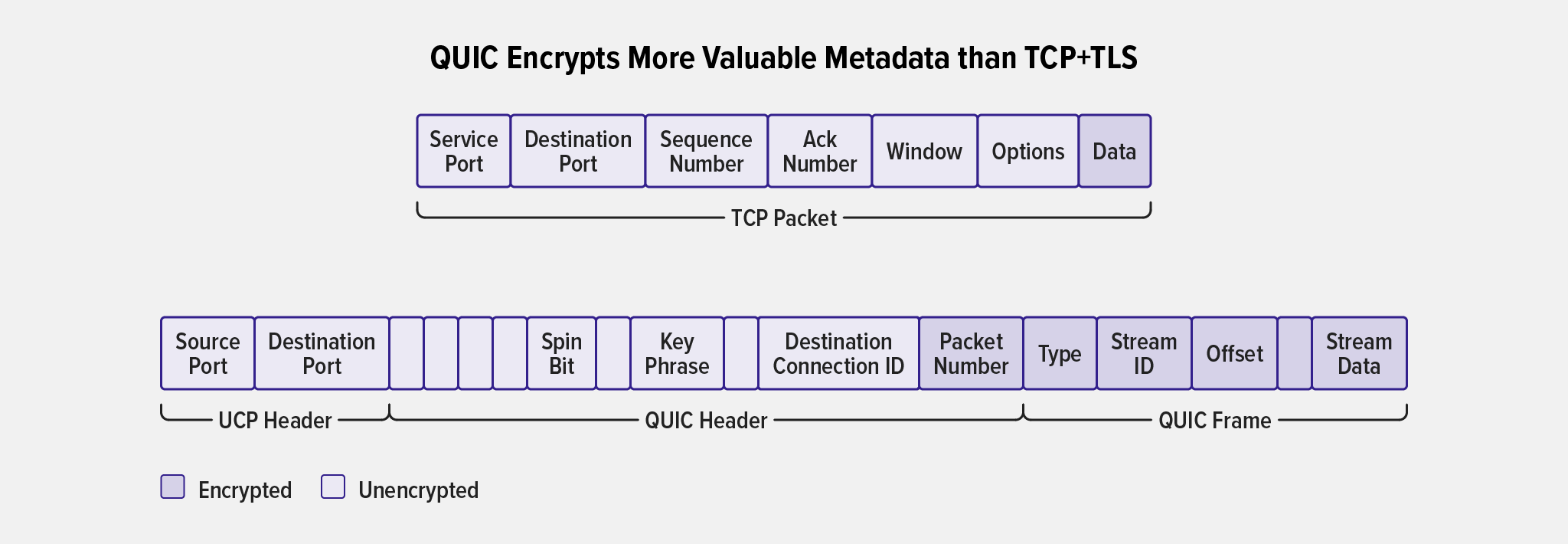
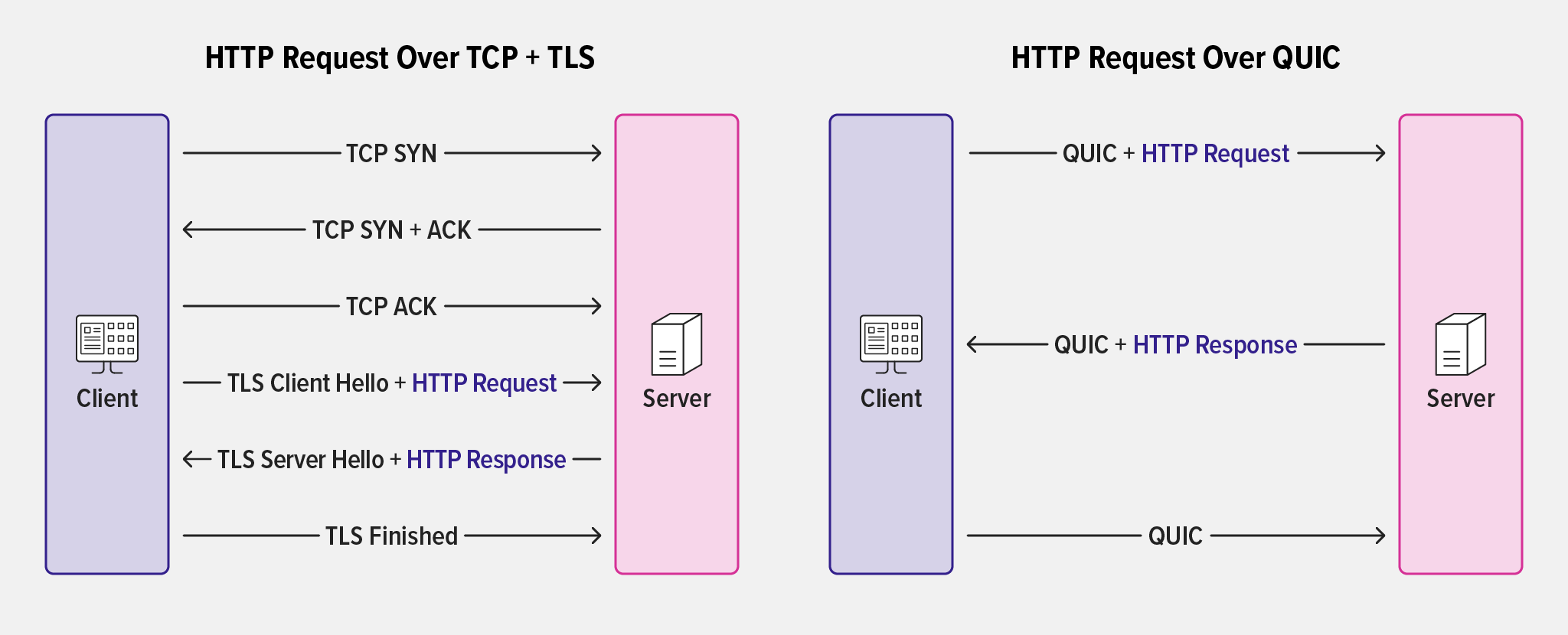
With a new underlying protocol stack, HTTP/3 brings UDP and QUIC to the transport layer. QUIC is an encrypted transport protocol designed to improve upon TCP by providing connection multiplexing and solving issues like head-of-line blocking. It reimplements and enhances a number of TCP capabilities from HTTP/1.1 and HTTP/2, including connection establishment, congestion control, and reliable delivery. QUIC also incorporates TLS as an integral component, unlike HTTP/1.1 and HTTP/2 which have TLS as a separate layer. This means HTTP/3 messages are inherently secure as they are sent over an encrypted connection by default.
Typically, for secure communication and cryptographic functionality, NGINX Plus relies on OpenSSL, making use of the SSL/TLS libraries that ship with operating systems. However, because QUIC’s TLS interfaces are not supported by OpenSSL at the time of this writing, third-party libraries are needed to provide for the missing TLS functionality required by HTTP/3.
To address this concern, we developed an OpenSSL Compatibility Layer for QUIC, removing the need to build and ship third-party TLS libraries like quictls, BoringSSL, and LibreSSL. This helps manage the end-to-end QUIC+HTTP/3 experience in NGINX without the burden of a custom TLS implementation nor the dependency on schedules and roadmaps of third-party libraries.
Note: The OpenSSL Compatibility Layer is included in the experimental NGINX Plus QUIC+HTTP/3 packages and requires OpenSSL 1.1.1 or above to provide TLSv1.3 (which is required by the QUIC protocol). It does not yet implement 0-RTT.
QUIC+HTTP/3 Sample Configuration
Let’s look at a sample configuration of QUIC+HTTP/3 in NGINX Plus:
http {
log_format quic '$remote_addr - $remote_user [$time_local]'
'"$request" $status $body_bytes_sent '
'"$http_referer" "$http_user_agent" "$http3"';
access_log logs/access.log quic;
server {
# for better compatibility it's recommended
# to use the same port for quic and https
listen 8443 quic reuseport;
listen 8443 ssl;
ssl_certificate certs/example.com.crt;
ssl_certificate_key certs/example.com.key;
location / {
# required for browsers to direct them into quic port
add_header Alt-Svc 'h3=":8443"; ma=86400';
}
}
}
Similar to our implementation of HTTP/2, when NGINX Plus acts as a proxy, QUIC+HTTP/3 connections are made on the client side and converted to HTTP/1.1 when connecting to backend and upstream services.
The NGINX Plus QUIC+HTTP/3 experimental packages are available from a separate repository, accessible with existing NGINX Plus Certificates and Keys. Installation of the experimental QUIC packages is similar to a standard NGINX Plus installation. Please make sure to use the QUIC repo, as highlighted in the installation steps.
You can refer to Configuring NGINX for QUIC+HTTP/3 for more information on how to configure NGINX for QUIC+HTTP/3. For information about all the new directives and variables, see the Configuration section of the nginx-quic README.
Next Steps
In the near future, we plan to merge the QUIC+HTTP/3 code into the NGINX mainline branch. The latest version of NGINX mainline with QUIC+HTTP/3 support will then be merged into a following NGINX Plus release. Expect an announcement on the official availability of QUIC+HTTP/3 support in NGINX Plus later this year.
Other Enhancements in NGINX Plus R29
Changes to OpenID Connect
OpenID Connect (OIDC) support was introduced in NGINX Plus R15 and then significantly enhanced in subsequent versions. NGINX Plus R29 continues to enhance OIDC, with the following additions.
Support for Access Tokens
Access tokens are used in token-based authentication to allow an OIDC client to access a protected resource on behalf of the user. NGINX Plus receives an access token after a user successfully authenticates and authorizes access, and then stores it in the key-value store. NGINX Plus can pass that token on the HTTP Authorization header as a Bearer Token for every request that is sent to the downstream application.
Note: NGINX Plus does not verify the validity of the access token on each request (as it does with the ID token) and cannot know if the access token has already expired. If the access token’s lifetime is less than that of the ID token, you must use the proxy_intercept_errors on directive. This will intercept and redirect 401 Unauthorized responses to NGINX and refresh the access token.
For more information on OpenID Connect and JSON Web Token (JWT) validation with NGINX Plus, see Authenticating Users to Existing Applications with OpenID Connect and NGINX Plus.
Added Arguments in OIDC Authentication Endpoint
Some identity providers, like Keycloak, allow adding extra query string arguments to the authentication request to enable additional capabilities. For example, Keycloak allows a default IdP to be specified by adding a kc_idp_hint parameter to the authentication request. As part of this enhancement, the user can specify additional arguments to the OIDC authorization endpoint.
Extended SSL Counters in Prometheus-njs Module
In NGINX Plus R28, we added additional SSL counter support for handshake errors and certificate validation failures in both HTTP and Stream modules for client-side and server-side connections. Our Prometheus-njs module, which converts NGINX Plus metrics to a Prometheus‑compliant format, now supports these counters.
New internal_redirect Directive
The new internal_redirect directive and module allows for internal redirects after checking request processing limits, connection processing limits, and access limits.
Here is an example internal_redirect configuration:
http {
limit_req_zone $jwt_claim_sub zone=jwt_sub:10m rate=1r/s;
server {
location / {
auth_jwt "realm";
auth_jwt_key_file key.jwk;
internal_redirect @rate_limited;
}
location @rate_limited {
internal;
limit_req zone=jwt_sub burst=10;
proxy_pass http://backend;
}
}
}
In the example above, JWT authentication is performed at the location block and – if the token is valid – the request is passed to the internal content handler @rate_limited, where a request rate limit is applied based on sub claim value. This happens in the JWT before the request is passed to the upstream service.
This particular configuration prevents a denial-of-service (DoS) attack where an attacker sends a flood of requests containing readable JWTs, encoded with a particular user as the sub field. That flood of requests will not pass authentication but would count towards the rate limit. By authenticating the JWT before passing the request to the content handler, you ensure that only valid requests count towards the rate limit.
Changes Inherited from NGINX Open Source
NGINX Plus R29 is based on NGINX Open Source 1.23.4 and inherits functional changes and bug fixes made since NGINX Plus R28 was released (in NGINX 1.23.3 through 1.23.4).
Changes
- The TLSv1.3 protocol is now enabled by default and is the default value for these directives:
- NGINX now issues a warning if protocol parameters of a listening socket are redefined.
- NGINX now closes connections with lingering if pipelining was used by the client.
- The logging level of the data length too long, length too short, bad legacy version, no shared signature algorithms, bad digest length, missing sigalgs extension, encrypted length too long, bad length, bad key update, mixed handshake and non-handshake data, ccs received early, data between ccs and finished, packet length too long, too many warn alerts, record too small, and got a fin before a ccs SSL errors has been lowered from crit to info.
Features
- Byte ranges are now supported in the
ngx_http_gzip_static_module.
Bug Fixes
- Fixed port ranges in the listen directive that did not work.
- Fixed an incorrect location potentially being chosen to process a request if a prefix location longer than 255 characters was used in the configuration.
- Fixed non-ASCII characters in file names on Windows, which were not supported by
ngx_http_autoindex_module, ngx_http_dav_module, and the include directive.
- Fixed a socket leak that sometimes occurred when using HTTP/2 and the
error_page directive to redirect errors with code 400.
- Fixed messages about logging to
syslog errors, which did not contain information that the errors happened while logging to syslog.
- Fixed handling of blocked client read events in proxy -r.
- Fixed an error that sometimes occurred when reading the PROXY protocol version 2 header with large number of TLVs.
- Fixed a segmentation fault that sometimes occurred in a worker process if SSI was used to process subrequests created by other modules.
- Fixed NGINX potentially hogging CPU during unbuffered proxying if SSL connections to backends were used.
Workarounds
zip filter failed to use pre-allocated memory alerts appeared in logs when using zlib-ng. - When a hostname used in the
listen directive resolves to multiple addresses, NGINX now ignores duplicates within these addresses.
For the full list of new features, changes, bug fixes, and workarounds inherited from these releases, see the CHANGES file.
Changes to the NGINX JavaScript Module
NGINX Plus R29 incorporates changes from the NGINX JavaScript (njs) module versions 0.7.9 to 0.7.12. Several exciting features were added to njs, including:
- Extended Fetch API Support
- Extended Web Crypto API
- XML Document Support
- XML Document Parsing
- XMLNode API to Modify XML Documents
- Zlib Module Compression Support
For a comprehensive list of all the features, changes, and bug fixes from njs version 0.7.9 to 0.7.12, see the njs Changes log.
Extended Fetch API Support
Headers(), Request(), and Response() constructors are added to the Fetch API, along with other enhancements:
async function makeRequest(uri, headers) {
let h = new Headers(headers);
h.delete("bar");
h.append("foo", "xxx");
let r = new Request(uri, {headers: h});
return await ngx.fetch(r);
}
Extended Web Crypto API
The Web Crypto API was extended to support the JSON Web Key (JWK) format and the importKey() now takes keys in JWK format as input:
async function importSigningJWK(jwk) {
return await crypto.subtle.importKey('jwk', jwk,
{name: "RSASSA-PKCS1-v1_5"},
true, ['sign']);
}
njs 0.7.10 also added the generateKey() and exportKey() methods. The generateKey() method allows you to generate a new key for symmetric algorithms or a key pair for public-key algorithms. The exportKey() method takes a CryptoKey object as input and returns the key in an external, portable format. It supports the JWK format to export the key as a JSON object.
For more details, refer Web Crypto API.
XML Document Support
The XML module was added in njs 0.7.10 to provide native support for working with XML documents.
XML Document Parsing
You can now parse a string or buffer for an XML document, which then returns an XMLDoc wrapper object representing the parsed XML document:
const xml = require("xml");
let data = `<note><to b="bar" a= "foo">Tove</to><from>Jani</from></note>`;
let doc = xml.parse(data);
console.log(doc.note.to.$text) /* 'Tove' */
console.log(doc.note.to.$attr$b) /* 'bar' */
console.log(doc.note.$tags[1].$text) /* 'Jani' */
XMLNode API to Modify XML Documents
The XMLNode API was added in njs 0.7.11 to modify XML documents:
Const xml = require("xml");
let data = `<note><to b="bar" a="foo">Tove</to><from>Jani</from></note>`;
let doc = xml.parse(data);
doc.$root.to.$attr$b = 'bar2';
doc.$root.to.setAttribute('c', 'baz');
delete doc.$root.to.$attr$a;
console.log(xml.serializeToString(doc.$root.to))
/* '<to b="bar2" c="baz">Tove</to>' */
doc.$root.to.removeAllAttributes();
doc.$root.from.$text = 'Jani2';
console.log(xml.serializeToString(doc))
/* '<note><to>Tove</to><from>Jani2</from></note>' */
doc.$root.to.$tags = [xml.parse(`<a/>`), xml.parse(`<b/>`)];
doc.$root.to.addChild(xml.parse(`<a/>`));
console.log(xml.serializeToString(doc.$root.to))
/* '<to><a></a><b></b><a></a></to>' */
doc.$root.to.removeChildren('a');
console.log(xml.serializeToString(doc.$root.to))
/* '<to><b></b></to>' */
For more details on all XML related enhancements, refer to the XML documents.
Zlib Module Compression Support
The zlib module was added in njs 0.7.12 and provides compression functionality using the deflate and inflate algorithms.
Const zlib = require('zlib');
zlib.deflateRawSync('αβγ').toString('base64')
/* "O7fx3KzzmwE=" */
zlib.inflateRawSync(Buffer.from('O7fx3KzzmwE=', 'base64')).toString()
/* "αβγ" */
For more details on zlib, refer to the zlib documents.
Upgrade or Try NGINX Plus
If you’re running NGINX Plus, we strongly encourage you to upgrade to NGINX Plus R29 as soon as possible. In addition to all the great new features, you’ll also pick up several additional fixes and improvements, and being up to date will help NGINX to help you if you need to raise a support ticket.
If you haven’t tried NGINX Plus, we encourage you to try it out – for security, load balancing, and API gateway, or as a fully supported web server with enhanced monitoring and management APIs. Get started today with a free 30-day trial.