As developers and technology professionals, we are all feeling the pressure of having to innovate, adapt, and build extraordinary new products and experiences faster than our competition. Continuous development and integration, the rapid deployment and elasticity of containers and cloud services, and breaking our applications into interconnected microservices are emerging as the new normal.
With the rise of this new approach to application development and deployment, a whole new suite of tools is emerging. Today’s developer tools are overwhelmingly open source, cloud‑friendly, and place a premium on adaptability, performance, and scalability.
If you ask anyone building microservices-based applications or working with containers today which software they use the most, NGINX is usually one of the first names that they mention. For example, NGINX Open Source is the third most popular piece of software on Docker Hub. As of the writing of this piece, it has been downloaded more than three million times, compared to only a few thousand downloads for the next most popular web servers, load balancers, and caching tools.
We’re incredibly proud of the broad adoption of NGINX and NGINX Plus and of our role as the application delivery platform for some of the world’s most innovative applications. But why are we so often paired with microservices and containerized applications?
There are a number of reasons why people select NGINX and NGINX Plus to proxy traffic to application instances on a distributed, containerized platform. They act as a ‘shock absorber’, filtering and smoothing out the flow of requests into an application. To reduce the load on applications, they can cache content and directly serve static content, as well as offload SSL/TLS processing and gzip compression.
NGINX and NGINX Plus perform HTTP routing, directing each request to the appropriate server as defined by policies that refer to values in the Host header and URI, followed up by load balancing, health checks, and session persistence. Application developers gain a huge degree of control over what traffic is admitted to their application, how rate limits are applied, and how requests are secured. NGINX and NGINX Plus also provide a layer of indirection between the client and the application, making it a vital point of control when you manage these applications. You can add and remove nodes, move traffic from one version of an application to another, and even perform A/B testing to compare two implementations.
But why should you care?
Below are 12 production‑proven reasons why we believe you should use NGINX and NGINX Plus to deliver your applications.
Reason #1 – A Single Entry Point
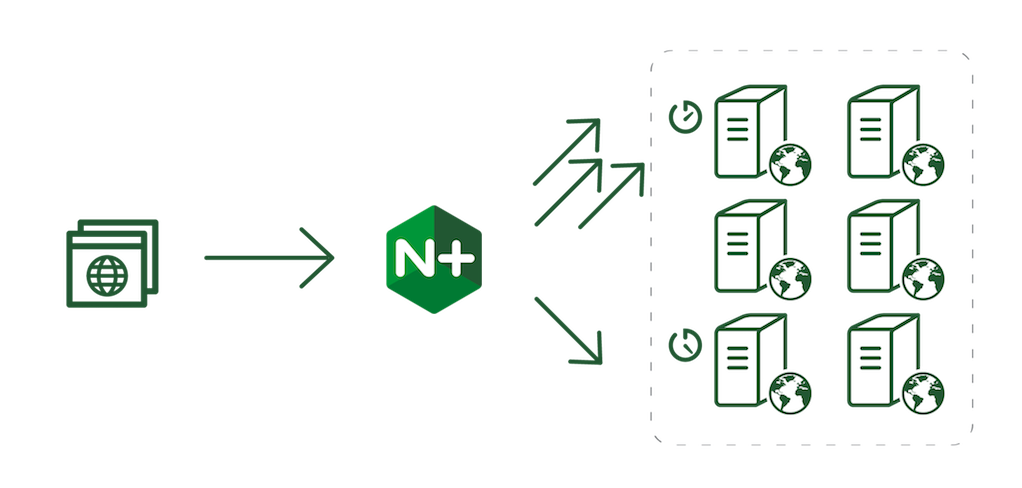
One of the advantages of a containerized platform is its fluidity: you can deploy and destroy containers as necessary. But at the same time you need to provide your end users with a single, stable entry point to access your services.
NGINX and NGINX Plus are perfect for that situation. For example, you can deploy a single cluster of NGINX Plus servers in front of your applications to load balance and route traffic, with a stable public IP address published in DNS. Clients address their requests to this reliable entry point, and NGINX Plus forwards them to the most appropriate container instance. If you add or remove containers, or otherwise change the internal addressing, you only need to update NGINX Plus with the new internal IP addresses (or publish them internally through DNS).
The single entry point provided by NGINX Plus bridges the reliable, stable frontend and the fluid, turbulent internal platform.
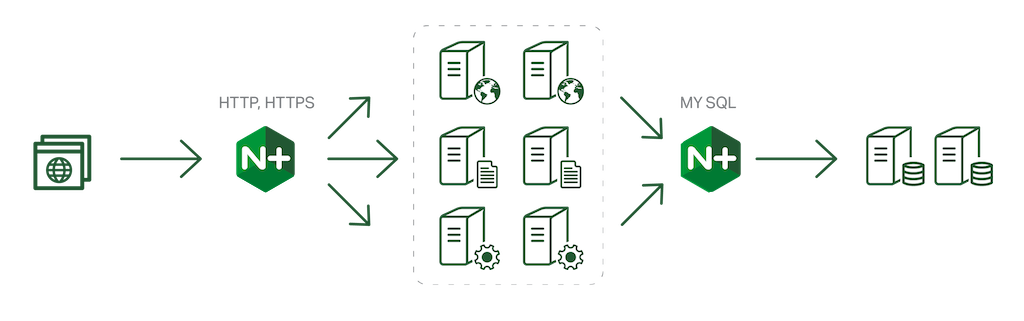
Reason #2 – Serving Static and Other Non‑Application Content
Not all of your microservices apps have APIs! It’s very likely that you will need to publish ‘static content’. In the mobile case, it’s the HTML5 framework, which creates the bare application in the device; in the more traditional web environment, it’s images, CSS, static web pages, and perhaps some video content.
An NGINX Plus or NGINX instance acts as an HTTP router, inspecting requests and deciding how each one should be satisfied. You can publish and deliver this content from the frontend NGINX and NGINX Plus servers.
Reason #3 – Caching
NGINX Open Source provides a highly capable cache for both static and dynamic content, with NGINX Plus adding even more features and capability.
There are many situations where caching dynamic content generated by your applications improves performance, such as content that is not personalized, or is updated on a predictable schedule – think news headlines, timetables, even lottery results. It’s very computationally expensive to route each request for this type of data to the microservice that generates it. A much more effective alternative is microcaching – caching a piece of data for a short period of time.
For example, if a resource is requested 10 times per second at its peak, and you cache it for just one second, you reduce the load on the backend infrastructure by 90%. The net result is that NGINX and NGINX Plus insulate your applications from spikes of traffic so that they can run smoothly and predictably, and you don’t need to scale resources on a second‑by‑second basis.
Reason #4 – SSL/TLS and HTTP/2 Termination
NGINX and NGINX Plus offer a feature‑rich, high‑performance software stack for terminating SSL/TLS and HTTP/2 traffic (Editor – when this blog was originally published, NGINX and NGINX Plus supported HTTP/2’s predecessor, SPDY). By offloading SSL/TLS and HTTP/2, NGINX and NGINX Plus provide three benefits to the microservice instances:
- Reduced CPU utilization.
- Richer SSL/TLS support. NGINX and NGINX Plus support HTTP/2, session resumption, OCSP stapling, and multiple ciphers – a more comprehensive range of functionality than many application platforms.
- Improved security and easier management of SSL/TLS private keys and certificates, because they are stored only on the host where NGINX or NGINX Plus is running, instead of at every microservice instance.
Offloading SSL/TLS processing for client connections to NGINX and NGINX Plus does not prevent you from using SSL/TLS on your internal network. They maintain persistent SSL/TLS and plain‑text keepalive connections to the internal network, and multiplex requests from different clients down the same connection. This greatly reduces connection churn and the computational load on your servers.
Reason #5 – Multiple Backend Apps
Recall that we mentioned that an NGINX or NGINX Plus instance can act as an HTTP “router”? The configuration language is designed to express rules for traffic, based on the Host header and the URL, making it very easy and natural to manage traffic for multiple applications through a single NGINX and NGINX Plus cluster. This is precisely what cloud providers like CloudFlare and MaxCDN do – they use NGINX and NGINX Plus to proxy traffic for hundreds of thousands of individual HTTP endpoints, routing each request to the appropriate origin server.
You can load application delivery configuration into NGINX and NGINX Plus and update rules without any downtime or interruption in service, making your NGINX or NGINX Plus instance a highly available switch for large, complex sets of applications.
Reason #6 – A/B Testing
The A/B testing capabilities built into NGINX and NGINX Plus can help with the rollout of microservice applications.
NGINX and NGINX Plus can split traffic between two or more destinations based on a range of criteria. When deploying a new implementation of a microservice, you can split incoming traffic so that (for example) only 1% of your users are routed to it. Monitor the traffic, measure the KPIs (response time, error rate, service quality), and compare how the new and old versions handle real production traffic.
Reason #7 – Consolidated Logging
NGINX and NGINX Plus use the standard HTTP access log formats. So instead of logging traffic for each microservice instance separately and then merging the log files (which requires synchronizing timestamps with millisecond‑level precision), you can log web traffic on the NGINX front end.
This significantly reduces the complexity of creating and maintaining access logs, and is a vital instrumentation point when you are debugging your application.
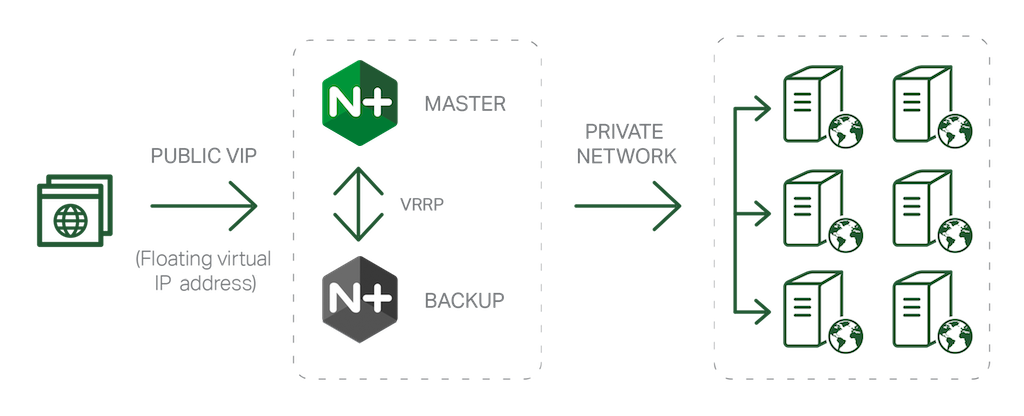
Reason #8 – Scalability and Fault Tolerance
You can seamlessly scale your backend infrastructure, adding and removing microservices instances without your end users ever experiencing a failure.
The load balancing, health checks, session persistence, and draining features in NGINX Plus are key to building a reliable yet flexible application infrastructure. If you need more capacity, you can deploy more microservice instances and simply inform NGINX Plus that you’ve added new instances to the load‑balanced pool. NGINX Plus detects when a microservice instance fails (whether planned or unplanned), retries failed requests, and doesn’t route traffic to the failed server until it recovers. If you’re using NGINX Plus to manage end‑user sessions for a stateful HTTP application, the ‘connection draining’ feature lets you smoothly remove a server from service without disrupting client sessions.
Reason #9 – GZIP Compression
GZIP compression is a great way to reduce bandwidth and, in the case of high‑latency networks, improve response time. Structured data such as JSON responses is particularly compressible with ease on NGINX Plus and NGINX.
By using NGINX Plus and NGINX to compress server responses, you simplify the configuration and operation of the internal services, allowing them to operate efficiently and making internal traffic easier to debug and monitor.
Reason #10 – Zero Downtime
A fluid, frequently upgraded microservices‑based application is not the only part of your architecture to benefit from high availability delivered by NGINX Plus and NGINX, which are themselves fully available during major software upgrades.
You can perform on‑the‑fly binary upgrades of software, something that is simply not possible with legacy application delivery controllers. You can update software versions seamlessly, with no connections dropped or refused during the upgrade process.
Reason #11 – Your Application Does Not Need :80 Root Privileges
On a Linux host, services need ‘root’ or ‘superuser’ privileges to bind to ports 80 and 443, the ports commonly used for HTTP and HTTPS traffic. However, granting applications these privileges can also give them other privileges that might be exploited if the application has a bug or vulnerability.
It’s best practice to deploy applications with minimal privileges, for example by having them bind to high port numbers instead of privileged ports. NGINX and NGINX Plus can receive public traffic on port 80 or 443 and forward it to internal servers that use other port numbers.
Reason #12 – Mitigate Security Flaws and DoS Attacks
Finally, NGINX and NGINX Plus are very robust, proven engines that handle huge volumes of HTTP traffic. They protect applications from spikes of traffic and malformed HTTP requests, cache common responses, and deliver requests to the application smoothly and predictably. You can think of them as a shock absorber for your application.
NGINX and NGINX Plus can further control traffic, applying rate limits (requests per second and requests per minute) based on a range of user‑defined criteria. This allows administrators to protect vulnerable APIs and URIs from being overloaded with floods of requests. They can also apply concurrency limits, queuing requests so that individual servers are not overloaded.
But Don’t Take Our Word For It . . .
As the authors of NGINX and NGINX Plus we believe we have created the ideal platform for delivering containerized applications and the deployment of microservices, but don’t take our word for it! Try NGINX Plus for free today, or learn more about building and deploying containerized applications in this technical webinar from experts at Docker and NGINX.